SGA和PGA简介
1 sga组成: 2b4p1s(记忆)
database buffer cache:包括 default pool,keep pool,recycle pool;
redo log buffer
share pool:包括 library cache,dictionary cache
large pool
java pool
streams pool
fixed sga 这部分区域的大小只有几MB
2.pga组成:
1)stack space(sql work area) :sort area(排序区),hash area(构造hash表),bitmap merge area(索引区)
2)uga区: (private sql area占主要部分):
2.1) persistent 区域 :存放绑定变量的值,以及数据类型等游标信息
2.2) run-time 区域 :查询执行状态信息,X$KSMUP
Oracle为执行sql的每一个session分配一个private sql area,这个区域还存储了一个很重要的地址信息用来指向存储在library cache中的shared sql area,
里面保存了SQl的执行计划。Oracle建议程序开发过程中尽量多使用bind variable目的就是为了降低hard parse,
直接意思的理解就是让我们尽量重用library cache中的SQL执行计划,这样就可以降低share pool latch和library cache latch等闩的竞争。
其中bind variable从那里来呢?上面其实已经提到了就是在private sql area中的永久内存区域存在,这个区域只有在游标关闭的状态下才被释放。
这里最后要了解的是,永久内存或者是运行时内存的释放并不是将内存反还给OS,而是反还给了UGA
官方文档位置
- Books → Concepts → Part V Oracle Instance Architecture → 14 Memory Architecture → 14.2 Overview of the User Global Area
- Books → Concepts → Part V Oracle Instance Architecture → 14 Memory Architecture → 14.3 Overview of the Program Global Area (PGA)
PGA 概述
PGA 是特定于一个操作系统进程或线程的内存区,且不和系统上的其他进程或线程共享。由于 PGA 是特定于进程的,所以它决不会在 SGA 中分配。PGA 是包含某个专用或共享服务器进程所需的会话变量的内存堆。服务器进程在需要时会在 PGA 中分配内存结构。
PGA 好比是文员所使用的临时工作台面。在这个比喻中,文员是为客户(客户端进程) 服务的服务器进程。文员清理出台面的一部分,使用这个工作空间来存储有关客户要求的详细信息,并对顾客请求的文件夹排序,然后在完成工作时让出工作空间。
下图显示某个未配置为共享服务器的实例的 PGA(所有 PGA 的集合) 。您可以使用一个初始化参数设置实例 PGA 的目标最大大小。根据需要, 各个 PGA 可以按需增大到这个目标大小。
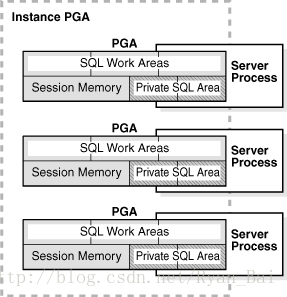
图 2:实例 PGA
Note:
后台进程也分配它们自己的 PGA。 本讨论的重点仅限于服务器进程 PGA。
See Also:
- "Summary of Memory Management Methods"
1 PGA 的内容
PGA 被进一步细分为多个不同区域,每一个都有不同的目的。
下图显示一个专用服务器会话的 PGA 中可能包含的内容。不是所有的 PGA 区域在任何情况下都存在。
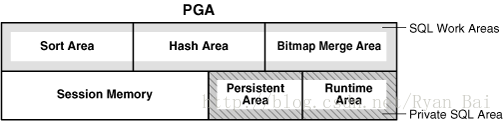
图 3:PGA 内容
1.1 Private SQL 区
私有 SQL 区保存了有关某个已解析的 SQL 语句的信息,和其他特定于会话的信息。
当服务器进程执行 SQL 或 PL/SQL 代码时,该过程使用其私有SQL 区域,来存储绑定变量值、查询执行状态信息、和查询执行工作区。
不要混淆在 UGA 中的私有 SQL 区,和在 SGA 中存储执行计划的共享 SQL区。在相同或不同的会话中的多个私有 SQL 区,可能指向 SGA 中的一个单一执行计划。 例如,在某个会话中运行“SELECT * FROM sales” 20 次,而在另一个不同的会话中运行同一查询 10 次,但它们可以共享相同的执行计划。每次运行的私有 SQL 区并不共享,因此可能包含不同的值和数据。
游标是指向某个特定的私有 SQL 区的一个名称或句柄。如下图所示,你可以将游标看成是一个从客户端指向服务器端状态信息的指针。游标与私有 SQL 区密切相关,这两个术语有时可以互换使用。
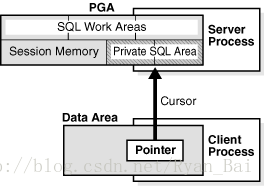
图 4:游标
私有 SQL 区又分为以下几个区域:
- run-time 区域
此区域包含查询执行状态信息。例如,run-time area会跟踪到目前为止在全表扫描中检索到的行数。
Oracle 数据库将创建 run-time 区域,作为一个执行请求的第一步。对于 DML 语句,其 run-time 区域将在 SQL 语句关闭时被释放。 - persistent 区域
此区域包含绑定变量的值。绑定变量是执行 SQL 语句时,在运行时提供给 SQL 语句的值。仅当关闭该游标时,persistent 区域才被释放。
客户端进程负责管理私有 SQL 区。虽然客户端进程可以分配的私有 SQL 区数量由初始化参数 OPEN_CURSORS 限制,但私有 SQL 区的分配和释放主要取决于应用程序。
尽管大多数用户依赖于数据库实用程序的自动游标处理机制,但 Oracle 数据库编程接口仍为开发人员提供了对游标更多的控制。一般情况下,应用程序应关闭所有打开的且不再使用的游标,以释放持久区域, 并最小化应用程序用户的内存需求。
See Also:
- "Shared SQL Areas"
- 《Oracle Database Development Guide》和《Oracle Database PL/SQL Language Reference》了解如何使用游标
1.2 SQL Work 区
工作区是在 PGA 中为内存密集型操作分配的私有内存区。
例如, 排序操作使用排序区来对一组行进行排序。同样,哈希联接操作将其左侧数据为输入,并使用哈希区来创建一个哈希表,而位图合并操作则使用位图合并区来合并从扫描多个位图索引检索到的数据。
如下示例显示了 employees 表和 departments 表相联接的查询计划。
SQL> SELECT *
2 FROM employees e JOIN departments d
3 ON e.department_id=d.department_id
4 ORDER BY last_name;
--------------------------------------------------------------------------------
| Id| Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 106 | 9328 | 7 (29)| 00:00:01 |
| 1 | SORT ORDER BY | | 106 | 9328 | 7 (29)| 00:00:01 |
|*2 | HASH JOIN | | 106 | 9328 | 6 (17)| 00:00:01 |
| 3 | TABLE ACCESS FULL| DEPARTMENTS | 27 | 540 | 2 (0)| 00:00:01 |
| 4 | TABLE ACCESS FULL| EMPLOYEES | 107 | 7276 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------在示例 1 中,run-time 区域跟踪全表扫描的进度。此会话在哈希区中执行一个哈希联接,以匹配两个表中的行。而 ORDER BY 排序操作在排序区中进行。
如果要由该运算符处理的数据量太大,不能在SQL Work 区中完成, 则 Oracle 数据库会将输入数据分成更小的片断。这样一来,数据库先在内存中处理一些数据片断,而将其余数据写入到临时磁盘存储,以待后续处理。
当启用了自动 PGA 内存管理时,数据库自动优化工作区大小。你也可以手动控制和优化工作区大小。更多的信息,请参阅“Memory Management”。
通常,更大的工作区可以显著提高操作性能,但这是以更多的内存消耗为代价的。理想的情况是,工作区域的大小足以容纳由其关联的SQL操作符分配的输入数据和辅助内存结构。否则,响应时间会增加,因为输入数据的一部分必须被缓存到磁盘上。在极端情况下,如果工作区的大小相比输入数据的大小显得过小,则数据库必须来回多次倒腾这些数据片断,极大地增大了响应时间。
See Also:
- 《Oracle Database Administrator’s Guide》了解如何使用自动 PGA 管理
- 《Oracle Database Performance Tuning Guide》 了解如何调整 PGA 内存
2 在专用和共享服务器模式中使用 PGA
PGA 内存分配取决于数据库是使用专用的还是共享的服务器连接。
表 1 显示了差异之处。
| 内存区 | 专用服务器 | 共享服务器 |
|---|---|---|
| 会话内存的性质 | 私有的 | 共享的 |
| persistent 区域的位置 | PGA | SGA |
| DML/DDL 语句的run-time区域的位置 | PGA | SGA |
表 14-1 专用和共享服务器之间的内存分配差异
See Also:
- 《Oracle Database Administrator’s Guide》了解如何将数据库配置为共享服务器
UGA 概述
UGA 是为会话变量分配的会话内存, 如登录信息和数据库会话所需的其他信息。 实际上,UGA 存储了会话状态。
图 1 描述了 UGA

图 1:用户全局区 (UGA)
如果某个会话将 PL/SQL 包加载到内存, 则在 UGA 中包含包状态,即是所有包变量在某个特定的时刻所存储的值集。当包的子程序更改变量的值时,包状态也将更改。默认情况下,包变量在会话的存活期间是唯一且持久的。
OLAP 页面缓冲池也存储在 UGA 中。该池管理相当于数据块的 OLAP 数据页。页缓冲池在启动一个 OLAP 会话时分配,并在该会话结束时释放。每当用户查询一个多维对象(如立方体)时,就会自动打开一个 OLAP 会话。
该 UGA 必须在数据库会话的整个存活期间是可用的。 由于这个原因, 当使用共享服务器的连接时,UGA 不能存储在 PGA 中,因为 PGA 是特定于单个进程的。因此,当使用共享服务器的连接时,UGA 被存储在 SGA 中,以使任何共享服务器进程都能访问它。在使用专用服务器的连接时, UGA 存储在 PGA 中。
pga和uga比较
uga:user global area ,是会话含义的内存区 为了保证数据可以被会话访问到,所以mts模式属于sga中的大池,专有模式属于pga,属于用户的内存区。
uga保存当前会话相关的信息,比如会话登录信息、pl/sql包的参数信息,绑定变量的值。
pga:program global area,是操作系统含义上的内存区,
可以理解为操作系统在一个进程启动时,为他分配的内存空间
查询使用 show pga;
sga和pga比较
sga:共享数据块,所有进程可以访问,数据并发访问
涉及lock,latch,锁定和队列
是数据库最主要优化区域,一些重要的指标:data buffer hit,library hit(hard/soft parse),hot blocks
pga:为专有进程服务,进程间无法数据共享,数据独占
无需锁定机制
性能优化只需要考虑它的大小。