根据抽取的数据,进行数据探索分析,本案例的探索分析,主要是缺失值分析和异常值分析,通过观察数据,我们得知,数据存在票价为空值,票价最小值为0,折扣率最小值为0,总飞行公里数大于0的情况。
票价为空,可能是客户不存在乘机记录造成的,其它客户可能是因为客户乘坐0折机票或者积分兑换产生的。
然后计算出每个属性对应的空值的属性和最大值和最小值,然后再进行数据的清洗和变换,数据探索的代码如下:
# -*- coding: utf-8 -*- import pandas as pd inputfile='F:\python数据挖掘\chapter7\demo\data\air_data.csv' outputfile='F:\python数据挖掘\chapter7\demo\tmp\tansuo.xls' data=pd.read_csv(inputfile,encoding='utf-8') tansuo=data.describe(percentiles=[],include='all').T tansuo['null']=len(data)-tansuo['count'] tansuo=tansuo[['null','max','min']] tansuo.columns=[u'空值数',u'最大值',u'最小值'] tansuo.to_excel(outputfile) #print(tansuo)
得出的结果为:各个属性的空值数和最大值和最小值,保存到相对应的路径。
对数据的清洗:
去掉票价为空值,保存票价不为o,然后折扣为0,总的飞行路线为0的情况。
最后得出结果,保存到excel文档中。
相对应的代码如下:
# -*- coding: utf-8 -*- import pandas as pd inputfile='F:\python数据挖掘\chapter7\demo\data\air_data.csv' outputfile='F:\python数据挖掘\chapter7\demo\tmp\clean_data.xls' data=pd.read_csv(inputfile,encoding='utf-8') data=data[data['SUM_YR_1'].notnull()*data['SUM_YR_2'].notnull()] index=data['SUM_YR_1']!=0 index1=data['SUM_YR_2']!=0 index2=(data['avg_discount']==0) & (data['SEG_KM_SUM']==0) clean=data[index | index1 | index2] #print(clean) clean.to_excel(outputfile)
因为给出的数据太多,所以需要进行数据规约:
数据规约如下:
进行提取主要影响的因素,进行数据的规约,最后根据这个数据进行模型构建,最后得出结果:
首先涉及几个因素,主要是时间的提取天数:
计算时间的天数,可以根据numpy.timedelta64进行计算得出:
结果为:
res = d_load - d_ffp data['L'] = res.map(lambda x: x / np.timedelta64(30 * 24 * 60, 'm'))
数据规约如下:
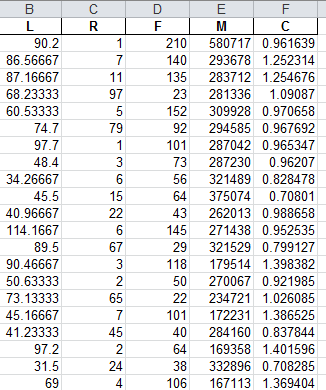
import numpy as np import pandas as pd inputfile='F:\python数据挖掘\chapter7\demo\tmp\clean_data.xls' outputfile='F:\python数据挖掘\chapter7\demo\tmp\zs_data.xls' data=pd.read_excel(inputfile,encoding='utf-8') #data = pd.read_excel(inputfile, encoding='utf-8') data = data[['LOAD_TIME', 'FFP_DATE', 'LAST_TO_END', 'FLIGHT_COUNT', 'SEG_KM_SUM', 'avg_discount']] # data['L']=pd.datetime(data['LOAD_TIME'])-pd.datetime(data['FFP_DATE']) # data['L']=int(((parse(data['LOAD_TIME'])-parse(data['FFP_ADTE'])).days)/30) ####这四行代码费了我3个小时 d_ffp = pd.to_datetime(data['FFP_DATE']) d_load = pd.to_datetime(data['LOAD_TIME']) res = d_load - d_ffp data['L'] = res.map(lambda x: x / np.timedelta64(30 * 24 * 60, 'm')) data['R'] = data['LAST_TO_END'] data['F'] = data['FLIGHT_COUNT'] data['M'] = data['SEG_KM_SUM'] data['C'] = data['avg_discount'] data = data[['L', 'R', 'F', 'M', 'C']] data.to_excel(outputfile) print('finish')
存入的结果为:
接下来进行数据的标准化:
而且更改列名:
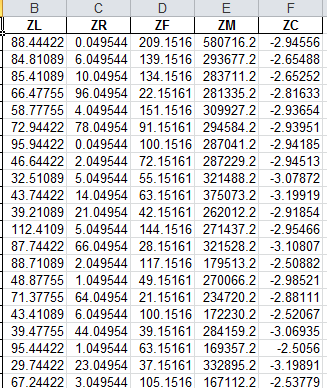
# -*- coding: utf-8 -*- import numpy as np import pandas as pd inputfile='F:\python数据挖掘\chapter7\demo\tmp\zs_data.xls' outputfile='F:\python数据挖掘\chapter7\demo\tmp\zs_code_data.xls' data=pd.read_excel(inputfile,encoding='utf-8') data=data-data.mean(axis=0)/data.std(axis=0) data.columns=['Z'+i for i in data.columns] #print(data.columns) data.to_excel(outputfile) print('finish')
得出的结果为:
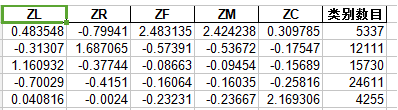
接下来就是对模型的构建,因为需要判断客户的价值,所以就分为几种客户,根据类别,可以给聚类中心赋值为5
import pandas as pd from sklearn.cluster import KMeans import matplotlib.pyplot as plt from itertools import cycle datafile='./tmp/zscore.xls' k=5 classoutfile='./tmp/class.xls' resoutfile='./tmp/result.xls' data=pd.read_excel(datafile) kmodel=KMeans(n_clusters=k,max_iter=1000) kmodel.fit(data) # print(kmodel.cluster_centers_) r1=pd.Series(kmodel.labels_).value_counts() r2=pd.DataFrame(kmodel.cluster_centers_) r=pd.concat([r2,r1],axis=1) r.columns=list(data.columns)+['类别数目'] # print(r) # r.to_excel(classoutfile,index=False) r=pd.concat([data,pd.Series(kmodel.labels_,index=data.index)],axis=1) r.columns=list(data.columns)+['聚类类别'] # r.to_excel(resoutfile,index=False)
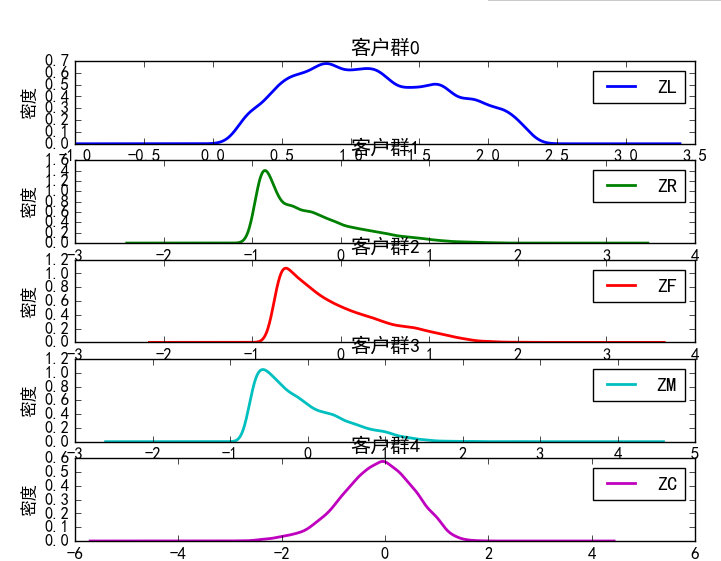
def density_plot(data): plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus']=False p=data.plot(kind='kde',linewidth=2,subplots=True,sharex=False) [p[i].set_ylabel('密度') for i in range(k)] [p[i].set_title('客户群%d' %i) for i in range(k)] plt.legend() return plt