0.展示PTA总分

1.本周学习总结
1.1 总结线性表内容
1.顺序表结构体定义、顺序表插入、删除的代码操作等
- 顺序表结构体定义:
typedef struct
{
ElemType data[MaxSize]; //存放顺序表元素
int length ; //存放顺序表的长度
} List;
- 顺序表插入:
这是一种插入操作的写法,核心函数如下,通过遍历顺序表找到插入位置,并将之后的元素逐一后移。个人感觉与数组插入的思路相同。
bool Insert(List L, ElementType X, Position P)
{
if (L->Last>=MAXSIZE||L==NULL)//空间已满
{
printf("FULL");
return false;
}
if ((P < 0) || (P > (L->Last)))//P指向非法位置
{
printf("ILLEGAL POSITION");
return false;
}
int temp = L->Last;
if (P + 1 == MAXSIZE)//插入位置在最后一位,且刚好把表装满
{
L->Data[P] = X;
(L->Last)++;
}
else
{
while (P < temp)
{
L->Data[temp] = L->Data[temp - 1];
temp--;
}
L->Data[P] = X;
(L->Last)++;
}
return true;
}
- 顺序表删除:
这是一题删除顺序表中重复元素的核心函数,与数组类似,通过循环来找到符合要求的元素之后进行移动。
void DelSameNode(List& L)//删除顺序表重复元素
{
if (L->length == 0)
{
return;
}
int i;
int j;
int k;
for (i = 0; i < L->length - 1; i++)//当长度为2时,此循环无法解决
{
for (j = i + 1; j < L->length; j++)
{
if (L->data[j] == L->data[i])
{
for (k = j; k < L->length - 1; k++)
{
L->data[k] = L->data[k + 1];
}
L->length--;
}
}
}
if (L->length == 2)
{
if (L->data[0] == L->data[1])
{
L->length--;
}
}
}
2.链表结构体定义、头插法、尾插法、链表插入、删除操作
- 链表结构体定义:
typedef struct LNode //定义单链表结点类型
{
ElemType data;
struct LNode *next; //指向后继结点
} LNode,*LinkList;
- 头插法:
通过不断改变头结点与下一结点之间的关系,将每次需要插入的新结点插在链表的最前端,来达到类似与逆序建表的效果。通过核心代码,可以看出,核心操作即为先断开头结点与下一结点的连接,将插入的新结点与断开的下一结点连接,再将头节点与插入的新节点相连即可。图如下:
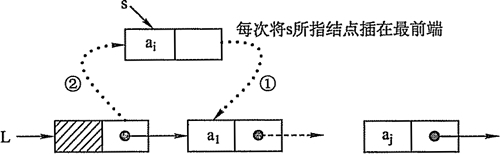
核心函数如下:
void CreateListF(LinkList& L, int n)
{
int i;
int num;
LinkList p;
L = new LNode;
L->next = NULL;
for (i = 0;i < n;i++)
{
cin >> num;
p = new LNode();
p->data = num;
p->next = L->next;
L->next = p; //头插法核心代码
}
}
PS:上述图解中的步骤1与步骤2,即核心的两句代码不可改变顺序,否则会改变原链表的逻辑关系,导致后续结点无法正常连接。
- 尾插法
与头插法相比,尾插法需要多建立一个尾结点来进行移动,将需要插入的新结点插在链表的最后。核心代码的实现为将新结点与尾结点tail相连,之后再将尾结点移动至新的链表末尾。图如下:

核心函数如下:
void CreateListR(LinkList &L, int n)
{
int i;
L=new LNode;
LinkList ptr;//指向原链表
LinkList tail;//尾节点
tail = L;
for(i=0;i<n;i++)
{
ptr=new LNode;
cin>>ptr->data;
tail->next = ptr;
tail = ptr; //尾插法核心代码
}
tail->next = NULL;
}
PS:需要注意的是,尾插法在进行完毕后,尾指针tail需要进行```
tail->next = NULL;
- 链表插入:
插入的操作在头插法与尾插法都有过相应的了解,主要操作即为改变原链表对应位置结点之间的关系,操作如下;
核心代码:
q->data = e; //e为需要插入元素的大小
q->next = p->next;
p->next = q;
- 链表删除:
链表删除即为找到需要删除的结点进行如下操作:
核心代码:
s=p->next; //LinkList s,多定义一个s用于保存删除的结点
p->next = p->next->next;
delete s;
**3.有序表,尤其有序单链表数据插入、删除,有序表合并**
**有序表**是一种比较特殊的线性表,其中的元素均以递增或者递减的方式有序排列,因此我们在对此类表进行操作时会比无序表的更轻松。
- 有序单链表数据插入
对于插入的操作,无论是顺序表还是链表的思路都又相似的地方,我对于这题有序链表的插入操作也是通过遍历找符合要求的结点位置进行操作。与顺序表不同的是,链表只需对单个结点的关系进行重构来达到插入的操作,无需像顺序表一样逐个后移,在时间上会节约不少。
void ListInsert(LinkList& L, ElemType e)
{
LinkList p = new(LNode);
p = L;
LinkList q = new(LNode);
while (1)
{
if (p && p->next)
{
if (e >= p->data && e <= p->next->data)
{
q->data = e;
q->next = p->next;
p->next = q;
return;
}
p = p->next;
}
else
break;
}
/若插入位置在最后一位,则上述循环无法完成,此时p没有后记结点,
因此直接将q结点赋值之后直接与p的最后一个节点连接/
q->data = e;
p->next = q;
p = p->next;
p->next = NULL;
return;
}
- 有序单链表数据删除
这道删除操作,同样是遍历找结点,然后进行删除操作。不过我这里的写法不够规范,只达到了从这条链表中移除需要删除的结点的功能,移除后的结点并没有进行删除操作,虽然对链表没有什么影响,但是在严谨上还不够。
void ListInsert(LinkList& L, ElemType e)
{
LinkList p = new(LNode);
p = L;
LinkList q = new(LNode);
while (1)
{
if (p && p->next)
{
if (e >= p->data && e <= p->next->data)
{
q->data = e;
q->next = p->next;
p->next = q;
return;
}
p = p->next;
}
else
break;
}
/若插入位置在最后一位,则上述循环无法完成,此时p没有后记结点,
因此直接将q结点赋值之后直接与p的最后一个节点连接/
q->data = e;
p->next = q;
p = p->next;
p->next = NULL;
return;
}
核心代码处应该改为:
s=p->next; //LinkList s,多定义一个s用于保存删除的结点
p->next = p->next->next;
delete s;
return;
- 有序表合并
这种写法是比较简单易懂的一种写法,即为二路归并算法。新定义一条新链表L3,在L1与L2的的比较中选出较小的那个元素用尾插法插入L3,伴随相应指针的移动。需要注意的就是L1与L2所指元素大小的判断条件与指针移动的操作。算法流程如下:
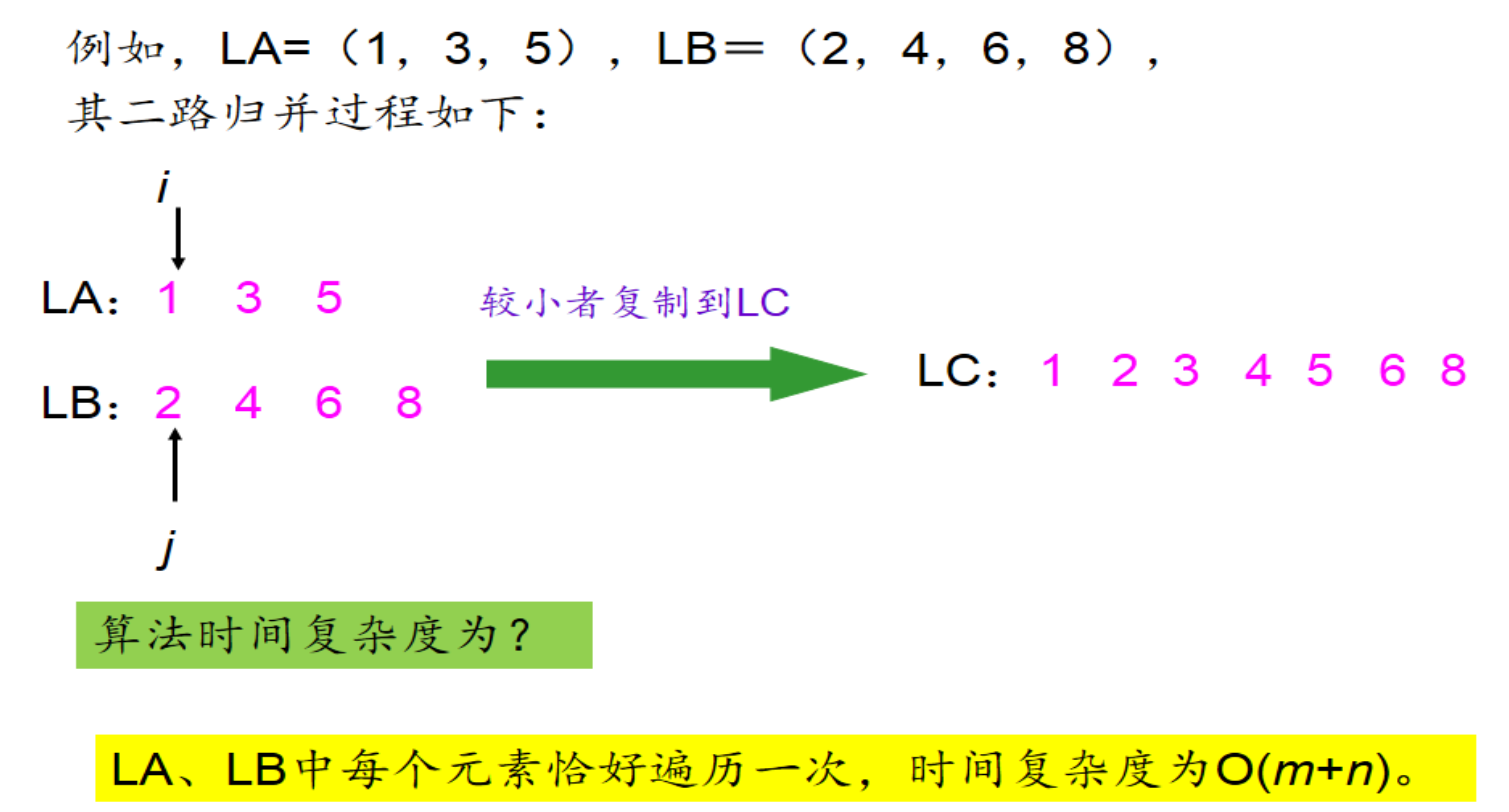
void MergeList(LinkList& L1, LinkList L2)
{
LinkList L3;
LinkList ptr;
ptr = new LNode;
ptr->next = NULL;
L3 = ptr; //创建L3头节点,并让ptr指向它
LinkList tail;//尾插法,定义尾节点
LinkList p = L1->next;
LinkList q = L2->next;/*因为有头节点,先将两个链表的位置下移*/
while (p && q)
{
if (p->data > q->data)//L1的节点的值较大
{
tail = q;//赋值
q = q->next;//L2下移
tail->next = NULL;
ptr->next = tail;
ptr = tail;
}
else if (p->data < q->data)
{
tail = p;//赋值
p = p->next;//L1下移
tail->next = NULL;
ptr->next = tail;
ptr = tail;
}
else//相等时,L1和L2的指针要同时下移
{
tail = p;
p = p->next;
q = q->next;//同时下移
tail->next = NULL;
ptr->next = tail;
ptr = tail;
}
}
if (p)//L1未到链表末尾
{
ptr->next = p;
}
if (q)//L2未到链表末尾
{
ptr->next = q;
}
L1 = L3;//最后把L3赋给L1
}
**4.循环链表、双链表结构特点**
- **循环链表结构特点**
1.循环链表是另一种形式的**链式**存贮结构。它的特点是表中**最后一个结点的指针域**指向**头结点**,整个链表形成一个环。
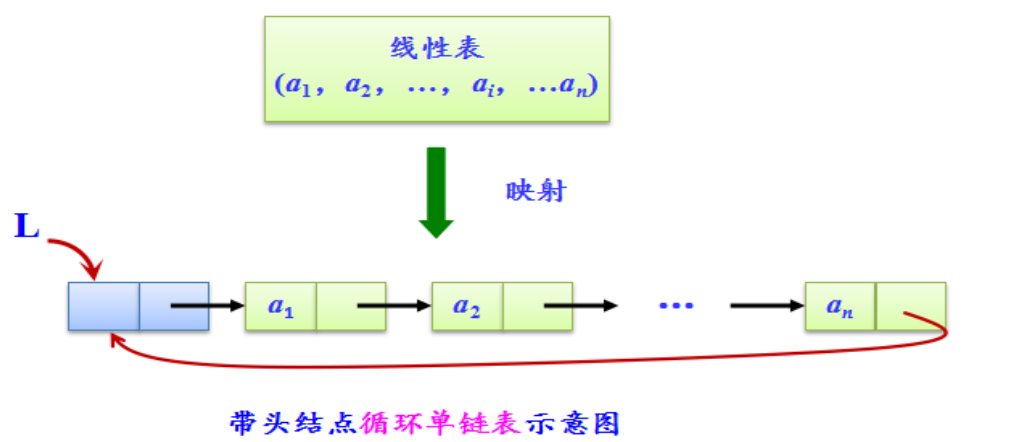
2.循环链表的**分类**:
- 单循环链表--在单链表中,将终端结点的指针域NULL改为指向表头结点或开始结点即可。
- 多重链的循环链表
3.**特点**:循环链表的特点是无须增加存储量,仅对表的链接方式稍作改变,即可使得表处理更加方便灵活。
PS:
- 循环链表中没有NULL指针。涉及遍历操作时,其终止条件就不再是像非循环链表那样判别p或p->next是否为空,而是判别它们是否等于某一指定指针,如头指针或尾指针等。
- 在单链表中,从一已知结点出发,只能访问到该结点及其后续结点,无法找到该结点之前的其它结点。而在单循环链表中,从任一结点出发都可访问到表中所有结点,这一优点使某些运算在单循环链表上易于实现。
- **双链表结构特点**
1.双链表的结构体定义:
typedef struct NNode
{
ELemType data;
struct DNode* prior; //指向前驱结点
struct DNode* next; //指向后继结点
}DLinkList;
2.双向链表也叫双链表,是链表的一种,它的每个数据结点中都有**两个指针**,分别指向**直接后继**和**直接前驱**。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
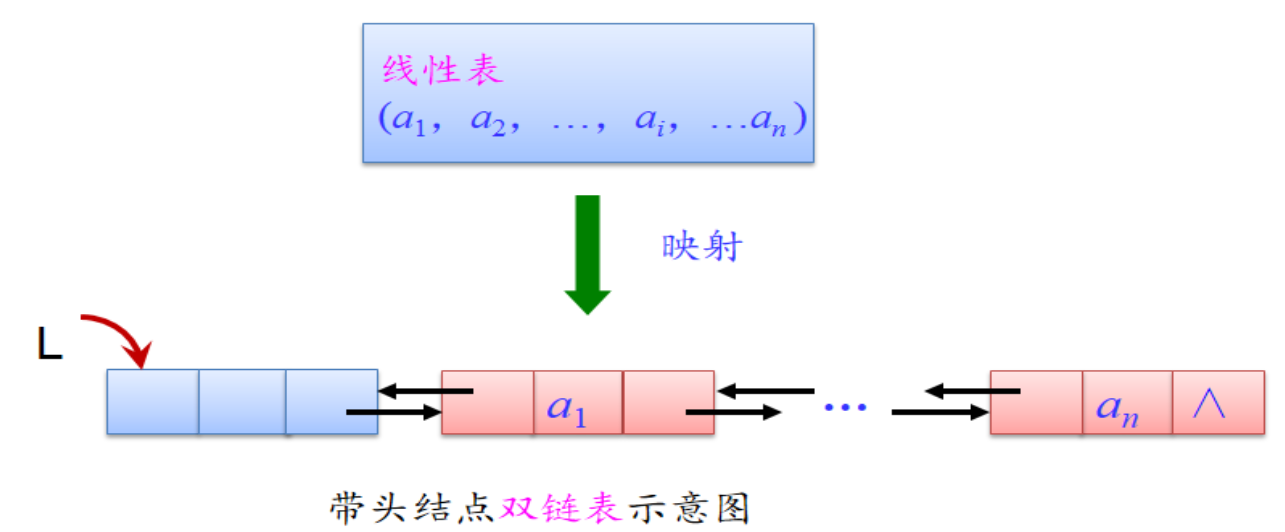
3.由于双链表的特殊结构,在进行一些操作时会大大优于单链表,如:
- 我们在**删除**单链表中的某个结点时,一定要得到待删除结点的前驱,一般来说,我们都会在定位待删除结点的同时一路保存当前结点的前驱,指针的总的移动操作有2*i次。而如果用双向链表,因为双向链表有一个指向直接前驱的指针,因此不需要定位前驱结点。因此指针总的移动操作为i次。
- 在进行**查找**时也一样,我们可以借用二分法的思路,从头结点向后查找操作和尾结点向前查找操作同步进行,这样查找元素的效率可以提高一倍。
PS:虽然在大部分操作的效率(时间复杂度)上,双链表会优于单链表,但是双链表的的每一个结点都比单链表多一个指向前驱的指针,因此,双向链表的在空间的占用上要大于单链表,因此,个人认为在一些对于时间效率并不高的程序中,单链表会由于双向链表。
###1.2.谈谈你对线性表的认识及学习体会。
**认识**
线性表主要分为顺序存储结构和链式存储结构两种。其中顺序存储结构主要运用的就是我们非常熟悉的数组,而链式存储结构则运用的是后来学习的链表。在建表前,两种结构都需要先对结构体做出定义。顺序存储结构由于类似于我们学习过的数组,比较简单,因此上手与熟练运用的比较快;但是链式存储结构是学习不久的链表,因此操作起来会有些生疏,也容易出现更多的错误。因此,在链表的学习上,还是要花更多的时间。
**体会**
今年因为疫情的原因,在家里以网课的形势开始了数据结构的学习。可能是在寒假中缺乏对指针与链表方面内容的复,刚刚开始学习的时候,觉得链表学习起来有些复杂,尤其是在打pta的时候,对于链表的初始化,头插法尾插法,以及许多链表的操作都没有一个清晰的认识,导致了许多不必要的麻烦,尤其是在初始化链表方面经常出现段错误。之后请教了一些同学,自己也进行了一些归纳,个人感觉,线性表的学习还是要多练习,阅读概念是没有用的,自己上手操作才会有收获;同时,阅读代码也是很关键的,面对一些比较复杂的代码,慢慢通过画图的方式来梳理清楚每一个结点之间的关系以及指针移动的操作,会对链表的学习有很大的帮助。尤其是在写函数题的时候,除了必要的函数之外,也可以练习如输出链表函数,定义结构体等的编写,让自己对一整套链表的操作有一个清晰的掌控。还是那句话:熟能生巧。面对问题的时候,一步一步的缕清楚代码关系,要知道,再复杂的代码也是由一组组简单代码构成的,慢慢调试,找到每个细小的错误点,多多练习,一定可以提高自己的正确率。新学期的第一篇博客,在这里希望自己可以保持一如既往的热情,认真上好每一堂课。冲冲冲!

##2.PTA实验作业
****
###2.1 PTA题目1
2019-ds-test
7-1 两个有序链表序列的交集 (20分)
已知两个非降序链表序列S1与S2,设计函数构造出S1与S2的交集新链表S3。
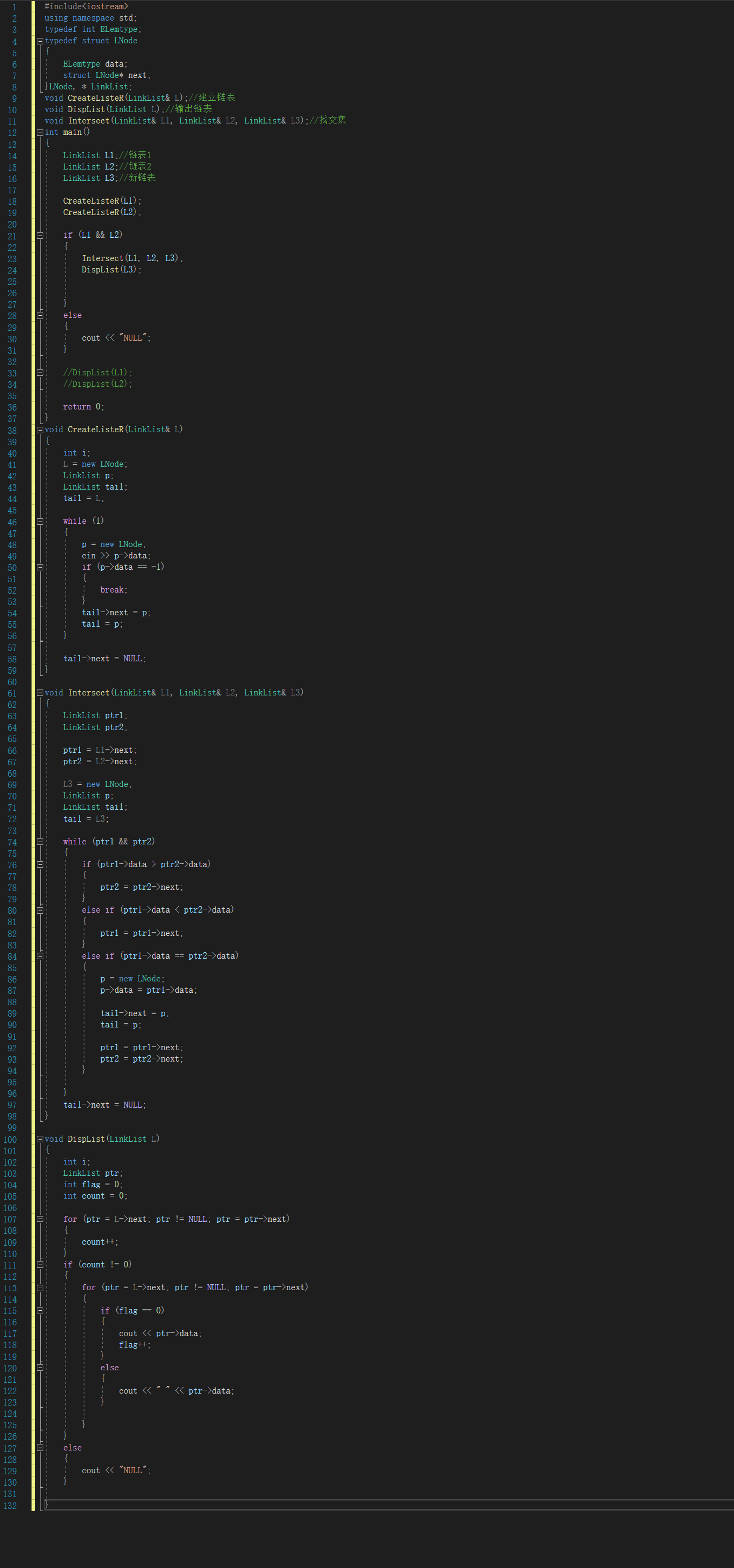
**2.1.1 代码截图**
**2.1.2 PTA提交列表及说明**
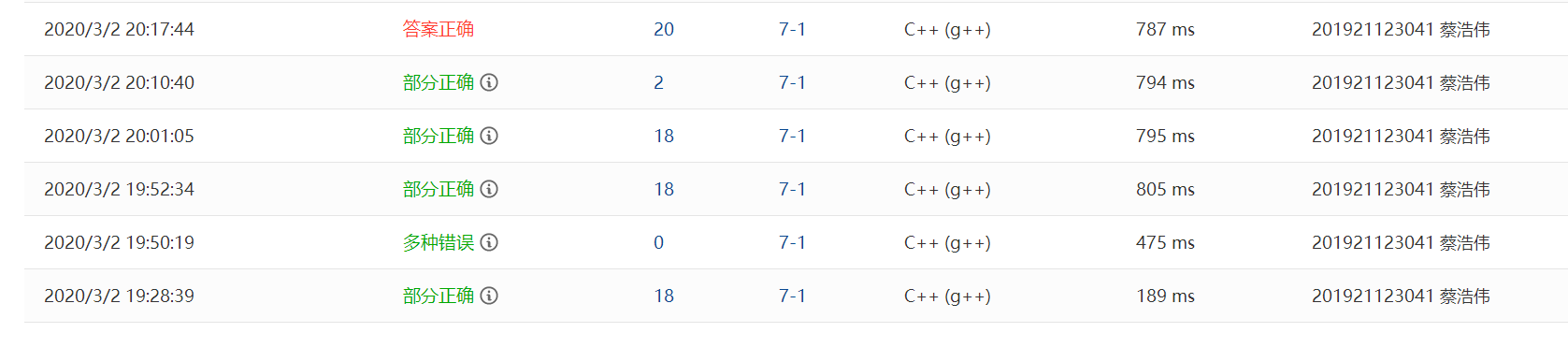
Q1: 部分正确
A1:在编写函数时忘记加入空链表的判断,最后又测试点过不了
Q2:多种错误
A2:在编写判断空链表的语句时,测试出现错误
Q3:全部正确
A3:直接在输出函数中加入判断,先遍历,若表中无元素,直接输出NULL,最后通过了全部测试点。
****
###2.2 PTA题目2
2019-ds-test
6-3 jmu-ds-链表区间删除 (20分)
已知L是一个带头结点的单链表,要求:
1.用插入排序方法创建链表L,L递增有序排列。
2.输入一个区间,能删除区间及区间内数。若全部删除,输出NULL
3.输出删除区间后的链表,应该是一个有序的链表。
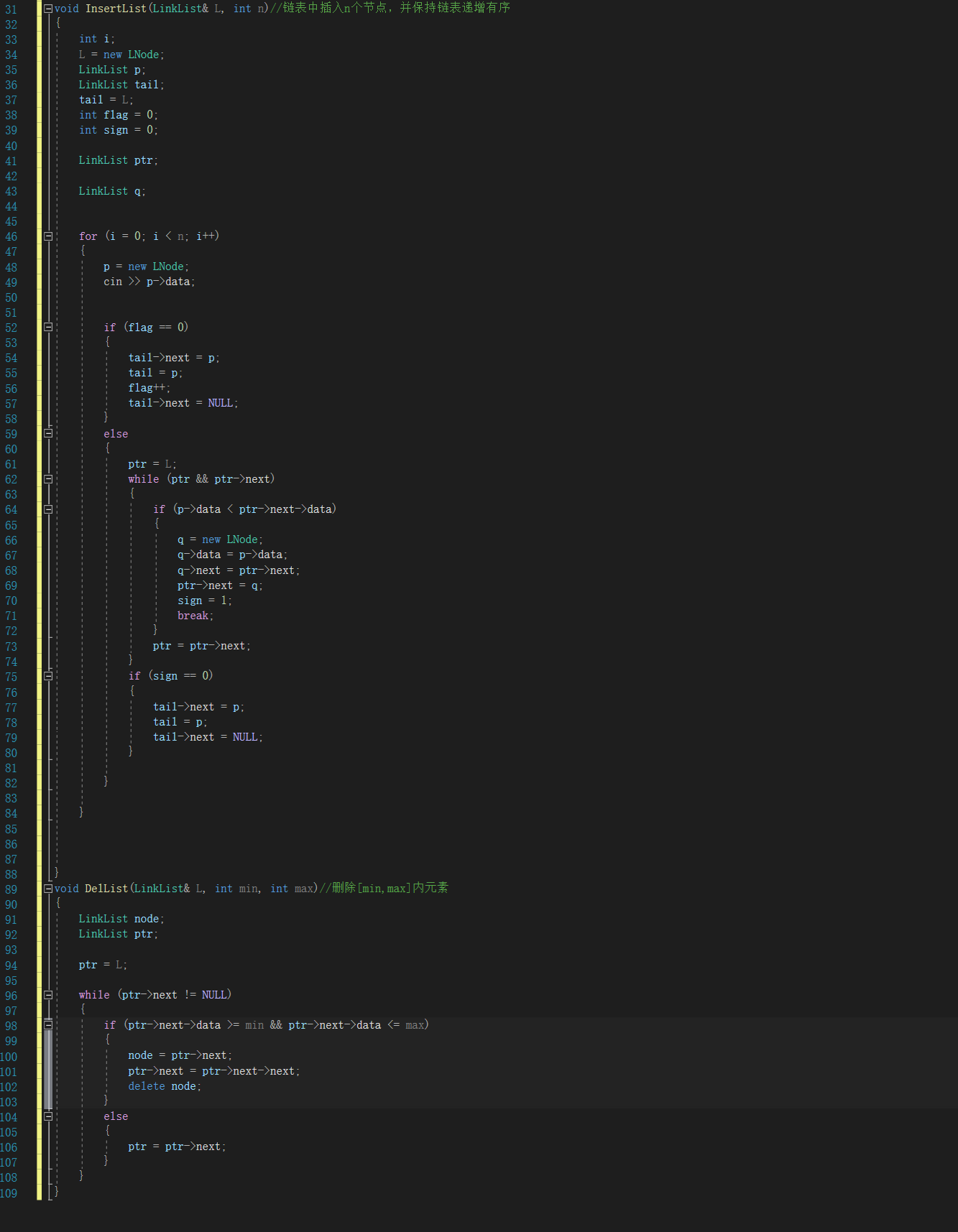
**2.2.1 代码截图**
**2.2.2 PTA提交列表及说明**

Q1:答案错误
A1:一开始我花了大量时间来编写插入排序,对于删除函数直接选择照搬从前的写法,两次错误后返回VS进行测试,发现是删除函数出了问题,变成了固定结点的删除
Q2:全部正确
A2:知道错误之后,我根据题目要求重新编写了删除函数,确保测试正确后提交,全部正确。
****
###2.3 PTA题目3
2019-线性表
7-2 一元多项式的乘法与加法运算 (20分)
设计函数分别求两个一元多项式的乘积与和。
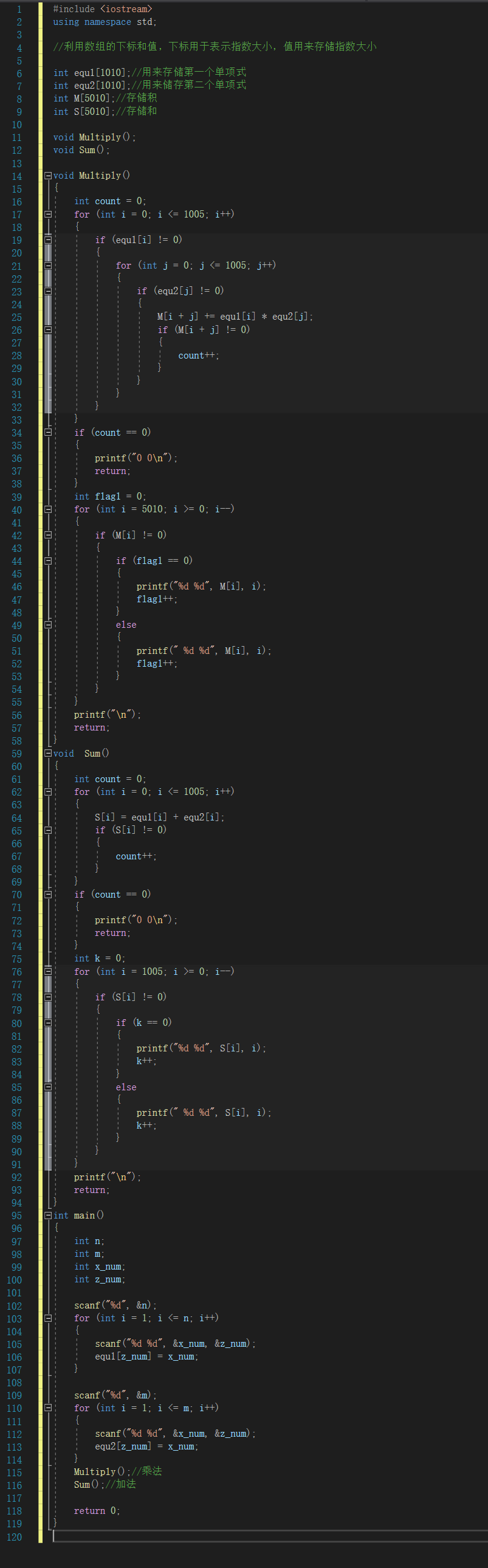
**2.3.1 代码截图**
**2.3.2 PTA提交列表及说明**

Q1: 部分正确
A1:第一次采用了链表的写法,运用的不太熟练,只有空表的情况过了测试点
Q2:全部正确
A2:采用链表多次调试失败后,我借鉴了一些思路,有了用数组来写的想法,最后调试成功。
PS:其实题目本意应该是希望我们用链表的写法完成这道题,我使用数组应该是有点取巧了。当时急着刷完pta,因此直接使用这样的写法提交,居然也通过了。后面我会继续写用链表完成这道题的代码...
****
********
##3.阅读代码:
###3.1 题目及解题代码
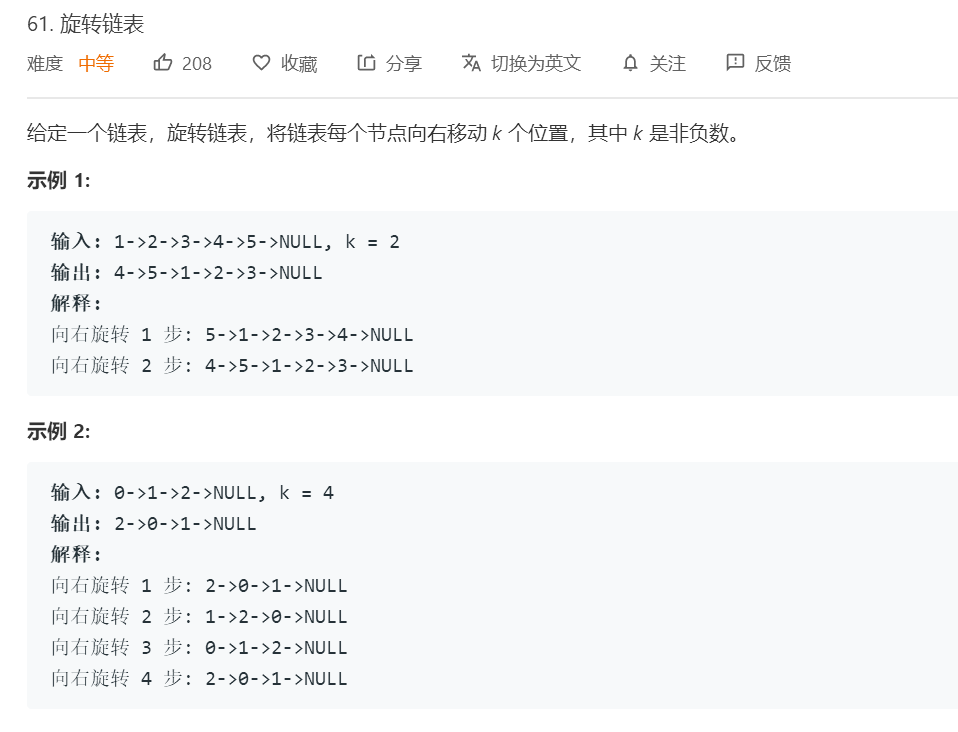

**3.1.1 该题的设计思路**
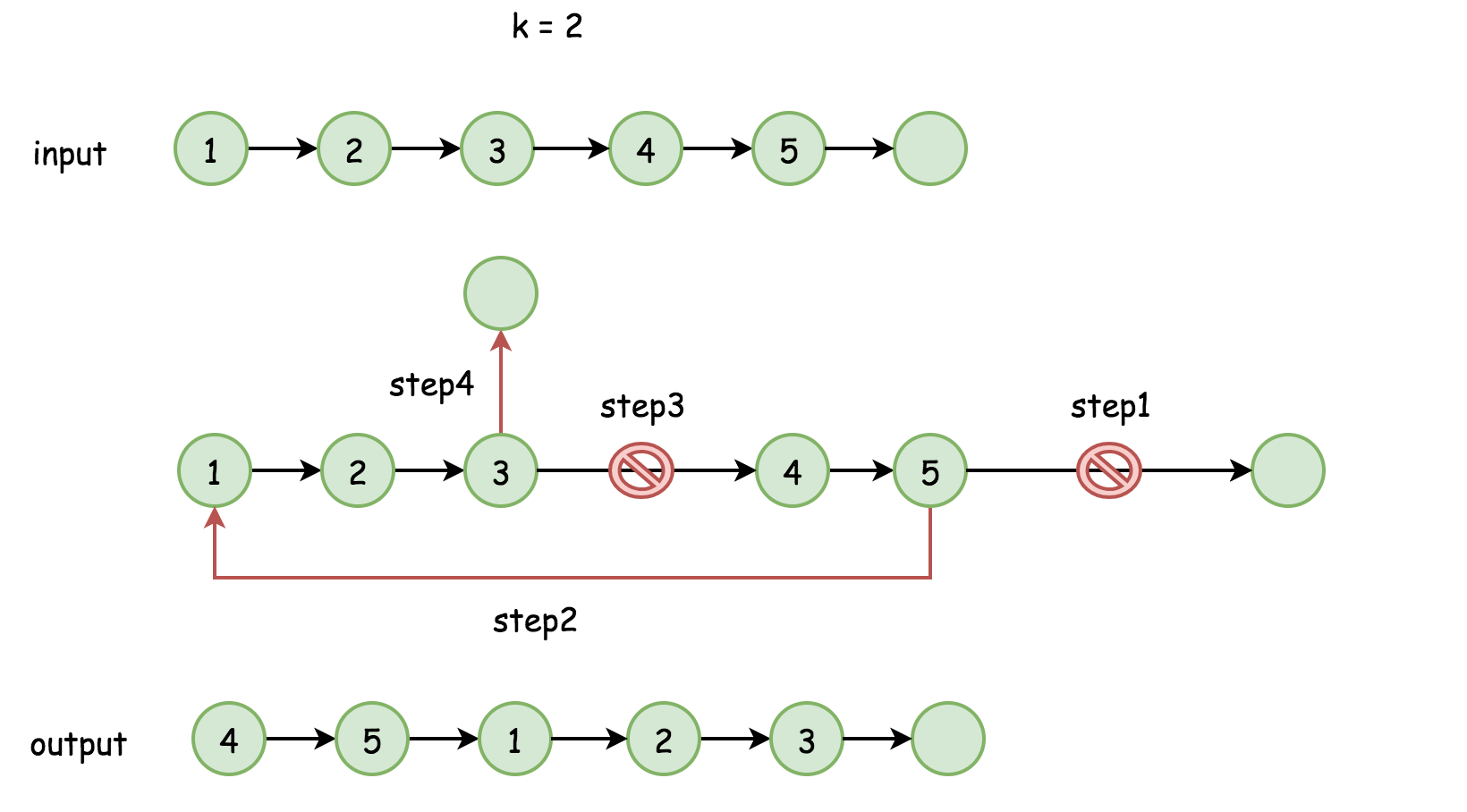
- 找到旧链表的尾部并将其与链表头相连,整个链表闭合成环。找到新的尾部节点,并断开环,返回新的链表头
- 时间复杂度:O(N) N为链表元素的个数
- 空间复杂度:O(1) 无需重新定义一条链,因此为O(1)
**3.1.2 该题的伪代码**
class Solution {
public ListNode rotateRight(ListNode head, int k) {
先判断头结点head是否为空;
判断头结点head->next是否为空;
定义旧的尾结点old_tail = 头结点head;
定义 n;//保存链表长度
for n = 1; old_tail.next != null; n++
old_tail = old_tail.next;
end for//计算链表长度
令尾结点的后继指向头结点old_tail.next = head;//将链表连成环
// find new tail : (n - k % n - 1)th node
// and new head : (n - k % n)th node
定义新的尾结点 new_tail = head;
for int i = 0; i < n - k % n - 1; i++
new_tail = new_tail.next;
end for//将新的尾结点移动到新的位置,即(n - k % n - 1)个结点处
ListNode new_head = new_tail.next;
断开环new_tail.next = null;
返回新的头结点new_head;//
}
}
**3.1.3 运行结果**
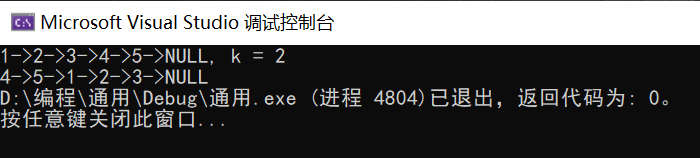
这题完整的代码是我从网上找来的,设计思路大体相同,也是通过连接成环再在对应位置断开形成新链表。
**3.1.4分析该题目解题优势及难点。**
- 优势:一开始,我看到这道题的时候,我的想法是将这条链表分割,再进行重构;但是看完题解,我感觉这种将链表变成一个环,改变头结点位置后再断开的写法大大节省了空间,同时代码量精简,可读性更强。
- 难点:
- 个人感觉此题的难点在于如何将一条单链表变成一条循环链表
- 当k大于链表长度时,需要将(k%n)再进行位置判断
###3.2 题目及解题代码



**3.2.1 该题的设计思路**
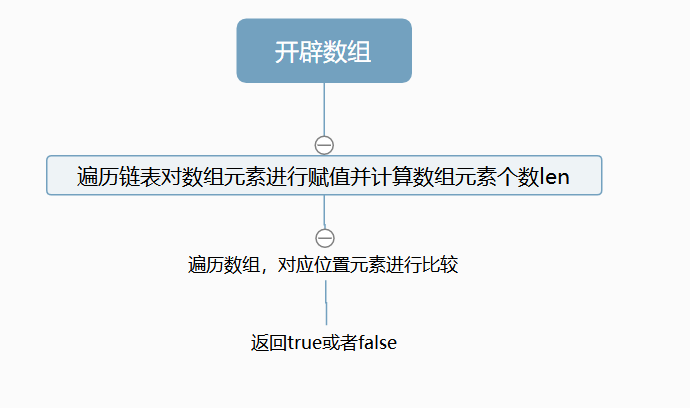
- 这道题的设计思路是比较简单的,直接开辟一个足够大的数组,将链表内容复制进数组中,之后利用数组的特性进行回文判断
- 时间复杂度:O(N) N为链表元素的个数
- 空间复杂度:O(1)
**3.2.2 该题的伪代码**
开辟一个大数组q[70000];
bool isPalindrome(struct ListNode* head){
定义指针p并令他指向头结点p = head;
定义长度len = 0;
while(p){
长度自增len++;
将链表中每个结点对应的值依次复制到数组中q[len] = p->val;
p指针下移 p = p->next;
}
for i = 1 to len/2
如果对应位置的数值相等if(q[i] != q[len-i+1])
返回false;
end for
返回true;
}
**3.2.3 运行结果**

**3.2.4分析该题目解题优势及难点。**
- 优势:代码精简易懂,我刚刚开始的想法是重新定义一个链表,将原链表中的元素以头插法插入新链表,将新链表与原链表进行对比,但是这样写的代码量比较大,对于指针也需要比较细致的处理
- 难点:这道题是LeetCode上找到的一道面试题,总的难度不是很大,个人感觉写法唯一的缺点就是数组的静态开辟所造成的空间浪费。