HBase应用开发
HBase的定义
HBase是一个高可靠、高性能、面向列、可伸缩的分布式存储系统。
- 适合于存储大表数据,可以达到实时级别。
- 利用Hadoop HDFS 作为其文件存储系统,提供实时的读写的数据库系统。
- 利用ZooKeeper作为协同服务。
HBase架构
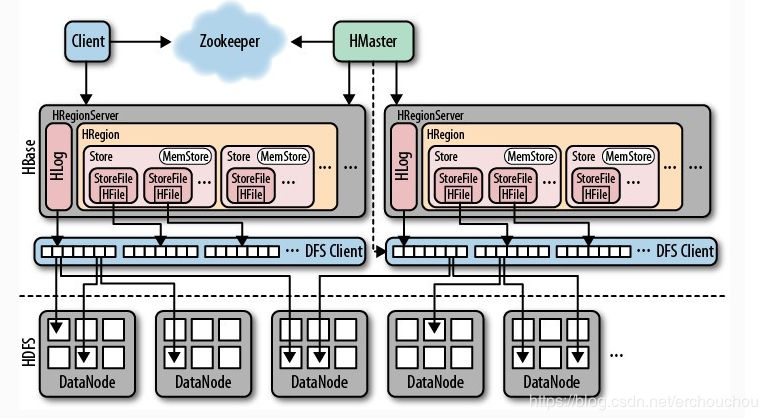
HBase的适用场景
- 海量数据
- 高吞吐量
- 需要在海量数据中实现高效的随机读取
- 需要很好的性能伸缩能力
- 能够同时处理结构化和非结构化的数据
- 不需要完全拥有传统关系型数据库所具备的ACID特性
HBase应用开发流程
- 制定业务目标
- 准备开发环境
- 下载并导入样例工程
设计HBase表
设计原则:
查询数据唯一
数据均匀分布
查询性能优化
其他因素(region的提前划分,冷热Family的使用)
- 根据场景开发工程
- 编译并运行程序
- 查看结果与调试程序
HBase表设计-总体原则
设计目标:提高吞吐量
设计原则:预分region,是region分布均匀,提高并发
实现方法:Rowkey范围和分布已知,建议预分region
设计目标:提高写入性能
设计原则:避免过多的热点region
设计方法:根据应用场景,可以考虑将时间因素引入Rowkey
设计目标:提高查询性能
设计原则:数据连续存储,频繁访问的数据存储一个地方,数据连续存储,离散度,信息冗余。
实现方法:同时读取的数据存放在同一行、cell,使用二级索引
HBase表设计-设计内容
设计内容通过不同维度,可分为:
Table设计(表粒度的设计)
- 建表方法
- 预分region
- Family属性
- 系统并发能力、数据清洗能力
RowKey设计
- 原则:需要同时访问的数据,RowKey尽量连续
- 访问效率:分散写,连续读
- 属性内容:常用的查询场景属性
- 属性值顺序:枚举,访问权重
- 时间属性:循环Key+TTL,周期建表
- 二级索引
- 折中法
- 冗余法
Family设计
可枚举数量少扩展性弱的属性作为Family
Qualifier设计
不可枚举、数量多且扩展性强的属性作为Qualifier
原则:同时访问的数据存放到同一个Cell,列名尽量简短
HBase常用接口
create()
put()
get()
getScanner(Scan scan)
、、、
创建Configuration实例以及Kerberos安全认证
HBaseConfiguration方法
创建表
create Table方法
写入数据
put方法
读取一行数据
get方法
读取多行数据
scan方法
HBase的开发
1. list_namespace:查询所有命名空间 hbase(main):001:0> list_namespace NAMESPACE default hbase 2. list_namespace_tables : 查询指定命名空间的表 hbase(main):014:0> list_namespace_tables 'hbase' TABLE meta namespace 3. create_namespace : 创建指定的命名空间 hbase(main):018:0> create_namespace 'myns' hbase(main):019:0> list_namespace NAMESPACE default hbase myns 4. describe_namespace : 查询指定命名空间的结构 hbase(main):021:0> describe_namespace 'myns' DESCRIPTION {NAME => 'myns'} 5. alter_namespace :修改命名空间的结构 hbase(main):022:0> alter_namespace 'myns', {METHOD => 'set', 'name' => 'eRRRchou'} hbase(main):023:0> describe_namespace 'myns' DESCRIPTION {NAME => 'myns', name => 'eRRRchou'} 修改命名空间的结构=>删除name hbase(main):022:0> alter_namespace 'myns', {METHOD => 'unset', NAME => 'name'} hbase(main):023:0> describe_namespace 'myns' 6. 删除命名空间 hbase(main):026:0> drop_namespace 'myns' hbase(main):027:0> list_namespace NAMESPACE default hbase 7. 利用新添加的命名空间建表 hbase(main):032:0> create 'myns:t1', 'f1', 'f2'
DDL
1. 查询所有表 hbase(main):002:0> list TABLE HelloHbase kylin_metadata myns:t1 3 row(s) in 0.0140 seconds => ["HelloHbase", "kylin_metadata", "myns:t1"] 2. describe : 查询表结构 hbase(main):003:0> describe 'myns:t1' {NAME => 'f1', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP _DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMP RESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '6553 6', REPLICATION_SCOPE => '0'} {NAME => 'f2', BLOOMFILTER => 'ROW', VERSIONS => '1', IN_MEMORY => 'false', KEEP _DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', COMP RESSION => 'NONE', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '6553 6', REPLICATION_SCOPE => '0'} 3. 创建分片表 hbase(main):007:0> create 'myns:t2', 'f1', SPLITS => ['10', '20', '30', '40'] 4. 修改表,添加修改列簇信息 hbase(main):009:0> alter 'myns:t1', {NAME=>'info1'} hbase(main):010:0> describe 'myns:t1' 5. 删除列簇 hbase(main):014:0> alter 'myns:t1', {'delete' => 'info1'} hbase(main):015:0> describe 'myns:t1' 6. 删除表 hbase(main):016:0> disable 'myns:t1' hbase(main):017:0> drop 'myns:t1'
DML
用到的表创建语句: hbase(main):011:0> create 'myns:user_info','base_info','extra_info' 1. 插入数据(put命令,不能一次性插入多条) hbase(main):012:0> put 'myns:user_info','001','base_info:username','张三' 2. scan扫描 hbase(main):024:0> scan 'myns:user_info' 3. 通过指定版本查询 hbase(main):024:0> scan 'myns:user_info', {RAW => true, VERSIONS => 1} hbase(main):024:0> scan 'myns:user_info', {RAW => true, VERSIONS => 2} 4. 查询指定列的数据 hbase(main):014:0> scan 'myns:user_info',{COLUMNS => 'base_info:username'} 5. 分页查询 hbase(main):021:0> scan 'myns:user_info', {COLUMNS => ['base_info:username'], LIMIT => 10, STARTROW => '001'} 6. get查询 hbase(main):015:0> get 'myns:user_info','001','base_info:username' hbase(main):017:0> put 'myns:user_info','001','base_info:love','basketball' hbase(main):018:0> get 'myns:user_info','001' 7. 根据时间戳查询 是一个范围,包头不包尾 hbase(main):029:0> get 'myns:user_info','001', {'TIMERANGE' => [1571650017702, 1571650614606]} 8. hbase排序 插入到hbase中去的数据,hbase会自动排序存储: 排序规则: 首先看行键,然后看列族名,然后看列(key)名; 按字典顺序 9. 更新数据 hbase(main):010:0> put 'myns:user_info', '001', 'base_info:name', 'rock' hbase(main):011:0> put 'myns:user_info', '001', 'base_info:name', 'eRRRchou' 10. incr计数器 hbase(main):053:0> incr 'myns:user_info', '002', 'base_info:age3' 11. 删除 hbase(main):058:0> delete 'myns:user_info', '002', 'base_info:age3' 12. 删除一行 hbase(main):028:0> deleteall 'myns:user_info','001' 13. 删除一个版本 hbase(main):081:0> delete 'myns:user_info','001','extra_info:feature', TIMESTAMP=>1546922931075 14. 删除一个表 hbase(main):082:0> disable 'myns:user_info' hbase(main):083:0> drop 'myns:user_info' 15. 判断表是否存在 hbase(main):084:0> exists 'myns:user_info' 16. 表生效和失效 hbase(main):085:0> enable 'myns:user_info' hbase(main):086:0> disable 'myns:user_info' 17. 统计表行数 hbase(main):088:0> count 'myns:user_info' 18. 清空表数据 hbase(main):089:0> truncate 'myns:user_info'
更多学习:https://www.csdn.net/gather_2f/MtTaEgzsMzI2Ni1ibG9n.html