今天正好学习了一下python的爬虫,觉得收获蛮大的,所以写一篇博客帮助想学习爬虫的伙伴们。
这里我就以一个简单地爬取淘票票正在热映电影为例,介绍一下一个爬虫的完整流程。
首先,话不多说,上干货——源代码
1 from bs4 import BeautifulSoup 2 import requests 3 import json 4 5 #伪装成浏览器请求 6 headers={ 7 'User-Agent':'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;', 8 'Referer':'https://www.taopiaopiao.com/showList.htm?spm=a1z21.3046609.header.4.1d69112aGq86y0&n_s=new' 9 } 10 11 #获取网页的代码 12 def getPage(url): 13 try: 14 response=requests.get(url) 15 if response.status_code==200: #http状态码,200表示请求成功 16 return response.text 17 else: 18 return None 19 except Exception: 20 return None 21 22 def getInfo(html): 23 soup=BeautifulSoup(html,'lxml') #创建bs对象 bs是使用的python默认的解析器,lxml也是解析器 24 items=soup.select('div .movie-card-wrap') #去网站的控制台找需要内容的上级标签元素,注意找的时候讲究方法,爬取的内容大部分都是有规律的,找到要爬取内容后,找你要爬的内容的父标签,这里找到div标签,然后后面的.movie-card-wrap是类名,当然也可以按照id查找,不会的自行百度soup.select 25 i=1 26 for item in items: 27 name=item.find(name='div',class_='movie-card-name').get_text().strip() #这个是找你要爬取内容的标签和它的类 28 info=item.find(name='div',class_='movie-card-list').get_text().strip() 29 print(str(i)+' '+'电影名:'+name+' '+info+' ') 30 i=i+1 31 32 url='https://www.taopiaopiao.com/showList.htm?spm=a1z21.3046609.header.4.1d69112aGq86y0&n_s=new' 33 html=getPage(url) 34 getInfo(html)
然后说一下代码的具体含义,其实注释都有,我再详细讲一下流程吧
一、伪装成浏览器请求headers
这很好理解,因为如果不伪装的话,那你去爬取,爬取网站就能获悉你在爬数据,很容易被封,所以我们写一个headers的json伪装成浏览器来访问,不明白的自行百度
二、获取网页代码getPage
这部分代码很好理解,有用的就两行,所以就不详细说了,用的时候直接用即可
三、获取信息getInfo
这部分是我觉得就爬取而言最难的一部分,当然也不是很难,所以我结合例子详细说一下
首先我们要知道,爬取网页内容是爬取的网页代码中的内容,服务器端的数据我们是没办法爬取到的,什么意思,我们打开浏览器,按F12
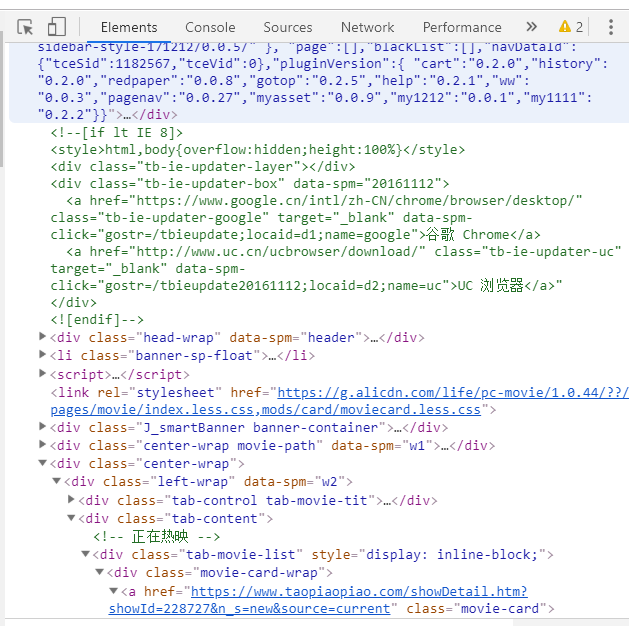
可以看到网页的源代码,然后我们要爬取的就是标签之间的那部分内容
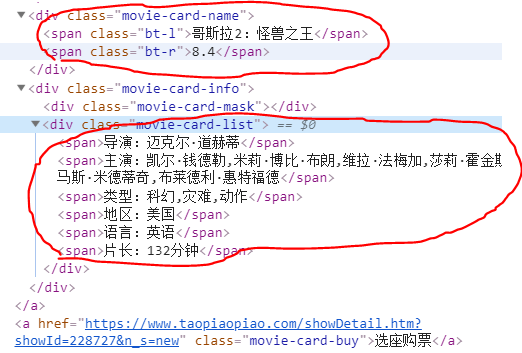
就是例如我上面画红圈的这些内容,我们这一步要做的,就是定位你要爬取内容在源代码中的位置,这么说大家可以理解吧。然后找到对应的标签,调用方法就可以了。
然后爬取到的信息可以存数据库,可以写成json数据,可以写入文件等再去做二次处理,筛选一些有用的数据,这里为了方便理解,我直接输出到控制台大家可以看一下结果。

这就是python爬虫,我也是新手,可能有很多说的不到位,希望大家海涵。