Getting-started-with-sql-and-bigquery
教程
结构化查询语言(SQL)是数据库使用的编程语言,它是任何数据科学家的一项重要技能。 在本课程中,您将使用BigQuery来提高SQL技能,BigQuery是一种Web服务,可用于将SQL应用于庞大的数据集。
在本课程中,您将学习访问和检查BigQuery数据集的基础知识。 在您掌握了这些基础知识之后,我们将再次建立您的SQL技能。
Your first BigQuery commands
要使用BigQuery,我们将在下面导入Python包
from google.cloud import bigquery
工作流程的第一步是创建一个Client对象。 您将很快看到,此Client对象将在从BigQuery数据集中检索信息中发挥核心作用。
# Create a "Client" object client = bigquery.Client()
我们将使用Hacker News(一个专注于计算机科学和网络安全新闻的网站)上的帖子数据集。
在BigQuery中,每个数据集都包含在相应的项目中。 在这种情况下,我们的hacker_news数据集包含在bigquery-public-data项目中。 要访问数据集,
我们首先使用dataset()方法构造对数据集的引用。接下来,我们使用get_dataset()方法以及刚刚构造的引用来获取数据集。
# Construct a reference to the "hacker_news" dataset dataset_ref = client.dataset("hacker_news", project="bigquery-public-data") # API request - fetch the dataset dataset = client.get_dataset(dataset_ref)
每个数据集都只是表的集合。 您可以将数据集视为包含多个表(均由行和列组成)的电子表格文件。我们使用list_tables()方法列出数据集中的表。
# List all the tables in the "hacker_news" dataset tables = list(client.list_tables(dataset)) # Print names of all tables in the dataset (there are four!) for table in tables: print(table.table_id)
output
comments
full
full_201510
stories
与获取数据集相似,我们可以获取表。 在下面的代码单元中,我们在hacker_news数据集中获取完整表。
# Construct a reference to the "full" table table_ref = dataset_ref.table("full") # API request - fetch the table table = client.get_table(table_ref)
Table schema
表的结构称为其架构。 我们需要了解表的架构以有效地提取所需的数据。
在此示例中,我们将调查上面获取的完整表。
# Print information on all the columns in the "full" table in the "hacker_news" dataset table.schema
output
[SchemaField('title', 'STRING', 'NULLABLE', 'Story title', ()), SchemaField('url', 'STRING', 'NULLABLE', 'Story url', ()), SchemaField('text', 'STRING', 'NULLABLE', 'Story or comment text', ()), SchemaField('dead', 'BOOLEAN', 'NULLABLE', 'Is dead?', ()), SchemaField('by', 'STRING', 'NULLABLE', "The username of the item's author.", ()), SchemaField('score', 'INTEGER', 'NULLABLE', 'Story score', ()), SchemaField('time', 'INTEGER', 'NULLABLE', 'Unix time', ()), SchemaField('timestamp', 'TIMESTAMP', 'NULLABLE', 'Timestamp for the unix time', ()), SchemaField('type', 'STRING', 'NULLABLE', 'Type of details (comment, comment_ranking, poll, story, job, pollopt)', ()), SchemaField('id', 'INTEGER', 'NULLABLE', "The item's unique id.", ()), SchemaField('parent', 'INTEGER', 'NULLABLE', 'Parent comment ID', ()), SchemaField('descendants', 'INTEGER', 'NULLABLE', 'Number of story or poll descendants', ()), SchemaField('ranking', 'INTEGER', 'NULLABLE', 'Comment ranking', ()), SchemaField('deleted', 'BOOLEAN', 'NULLABLE', 'Is deleted?', ())]
每个SchemaField都会告诉我们一个特定的列(也称为字段)。 按顺序,信息为:
列名
列中的字段类型(或数据类型)
列的模式(“ NULLABLE”表示列允许NULL值,并且是默认值)
该列中数据的描述
比如 SchemaField('by', 'STRING', 'NULLABLE', "The username of the item's author.", ()) 告诉我们:这个列名字为"by",数据为字符串型,允许为空,这个列存储了作者的名字
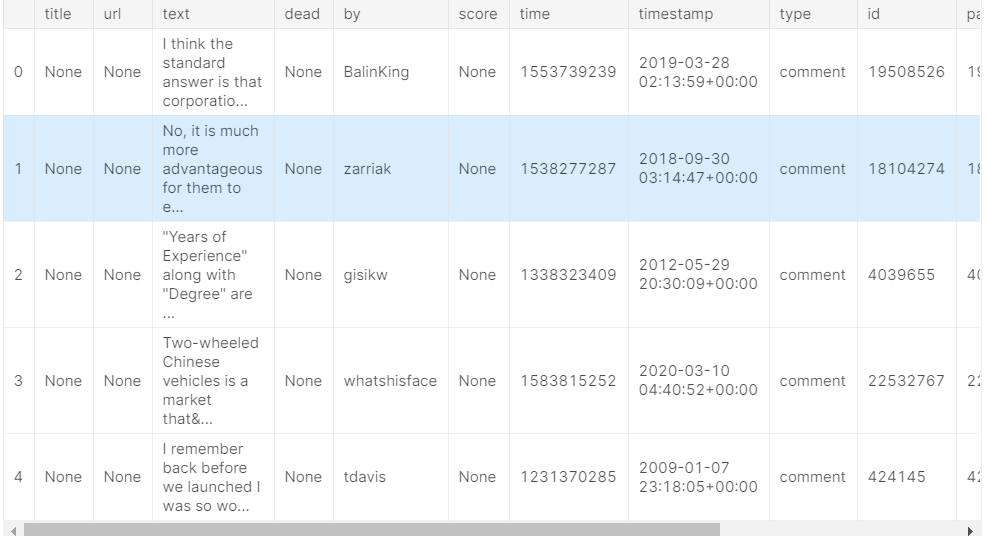
我们可以使用list_rows()方法来检查整个表的前五行,以确保这是正确的。 (有时数据库的描述已经过时,因此最好检查一下。)这将返回一个BigQuery RowIterator对象,该对象可以使用to_dataframe()方法快速转换为pandas DataFrame。
# Preview the first five lines of the "full" table client.list_rows(table, max_results=5).to_dataframe()
list_rows()方法还将使我们仅查看特定列中的信息。 例如,如果我们要查看by列中的前五个条目,则可以这样做:
# Preview the first five entries in the "by" column of the "full" table client.list_rows(table, selected_fields=table.schema[:1], max_results=5).to_dataframe()
Disclaimer
在进行编码练习之前,对已经知道一些SQL的人快速声明一下:
每个Kaggle用户可以每30天免费扫描5TB。 达到该限制后,您将不得不等待重置。
到目前为止,您所看到的命令将不需要该限制的有意义的一部分。 但是某些BiqQuery数据集非常庞大。 因此,如果您已经了解SQL,请等待运行SELECT查询,直到您了解如何有效使用分配。 如果您像大多数阅读此书的人一样,则还不知道如何编写这些查询,因此您无需担心此免责声明。