Renaming-and-combining
教程
通常,数据会以列名,索引名或我们不满意的其他命名约定提供给我们。 在这种情况下,您将学习如何使用pandas函数将有问题的条目的名称更改为更好的名称。
Renaming
我们将在这里介绍的第一个函数是rename(),它使您可以更改索引名和/或列名。 例如,要将数据集中的点列更改为得分,我们可以
reviews.rename(columns={'points': 'score'})
通过rename(),可以分别通过指定索引或列关键字参数来重命名索引或列值。 它支持多种输入格式,但是通常最方便的是Python字典。 这是一个使用它重命名索引的某些元素的示例。
reviews.rename(index={0: 'firstEntry', 1: 'secondEntry'})
您可能会经常重命名列,但是很少重命名索引值。 为此,通常使用set_index()更方便。
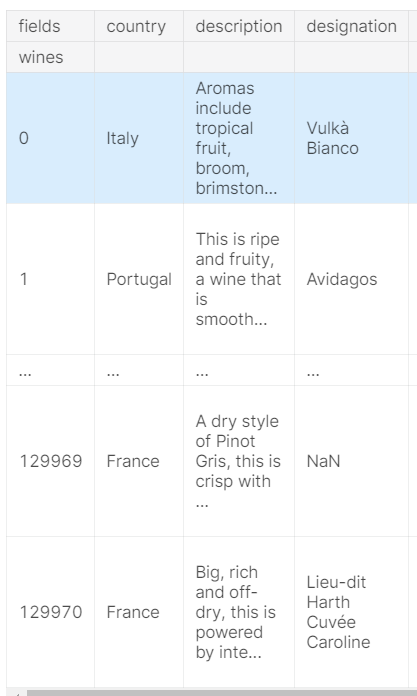
行索引和列索引都可以具有自己的名称属性。 互补的rename_axis()方法可用于更改这些名称。 例如:
reviews.rename_axis("wines", axis='rows').rename_axis("fields", axis='columns')
原来的表:
现在的表:
Combining
在数据集上执行操作时,有时我们需要以不平常的方式组合不同的DataFrame和/或Series。 pandas有三种核心方法可以做到这一点。 按照从简单到复杂的顺序,分别是concat(),join()和merge()。 merge()可以执行的大多数操作也可以通过join()来更简单地完成,因此我们将省略它,而只关注前两个函数。
最简单的组合方法是concat()。 给定一个元素列表,此函数会将这些元素沿轴拖在一起。
当我们在不同的DataFrame或Series对象中具有数据但具有相同的字段(列)时,这很有用。 一个示例:YouTube视频数据集,该数据集可根据来源国家/地区(例如本例中的加拿大和英国)对数据进行拆分。 如果我们想同时研究多个国家,可以使用concat()将它们混在一起:
canadian_youtube = pd.read_csv("../input/youtube-new/CAvideos.csv") british_youtube = pd.read_csv("../input/youtube-new/GBvideos.csv") pd.concat([canadian_youtube, british_youtube])
相当于两个表拼接到了一起。
就复杂性而言,最中间的组合器是join()。 join()使您可以组合具有共同索引的不同DataFrame对象。 例如,要提取加拿大和英国在同一天流行的视频,我们可以执行以下操作:
left = canadian_youtube.set_index(['title', 'trending_date']) right = british_youtube.set_index(['title', 'trending_date']) left.join(right, lsuffix='_CAN', rsuffix='_UK')
这里必须使用lsuffix和rsuffix参数,因为在英国和加拿大数据集中,数据具有相同的列名。 如果这不是真的(例如,因为我们事先将其重命名),则不需要它们。
join就是数据库之中的连接操作,主键与外键需要一样。
练习
1.
region_1 and region_2 are pretty uninformative names for locale columns in the dataset. Create a copy of reviews with these columns renamed to region and locale, respectively.
# Your code here renamed = reviews.rename(columns={'region_1': 'region','region_2':'locale'}) # Check your answer q1.check()
2.
Set the index name in the dataset to wines.
reindexed = reviews.rename_axis("wines", axis='rows') print(reindexed) # Check your answer q2.check()
3.
The Things on Reddit dataset includes product links from a selection of top-ranked forums ("subreddits") on reddit.com. Run the cell below to load a dataframe of products mentioned on the /r/gaming subreddit and another dataframe for products mentioned on the r//movies subreddit.
gaming_products = pd.read_csv("../input/things-on-reddit/top-things/top-things/reddits/g/gaming.csv") gaming_products['subreddit'] = "r/gaming" movie_products = pd.read_csv("../input/things-on-reddit/top-things/top-things/reddits/m/movies.csv") movie_products['subreddit'] = "r/movies"
Create a DataFrame of products mentioned on either subreddit.
combined_products = pd.concat([gaming_products, movie_products]) # Check your answer q3.check()
4.
The Powerlifting Database dataset on Kaggle includes one CSV table for powerlifting meets and a separate one for powerlifting competitors. Run the cell below to load these datasets into dataframes:
powerlifting_meets = pd.read_csv("../input/powerlifting-database/meets.csv") powerlifting_competitors = pd.read_csv("../input/powerlifting-database/openpowerlifting.csv")
Both tables include references to a MeetID, a unique key for each meet (competition) included in the database. Using this, generate a dataset combining the two tables into one.
powerlifting_combined = powerlifting_meets.set_index("MeetID").join(powerlifting_competitors.set_index("MeetID")) # Check your answer q4.check()