大数据第6周
1.启动集群并验证
启动集群:start-all.sh
启动后先用jps验证线程数是否正确,按照我的配置,master节点线程:
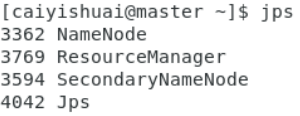
![]()
连个slave节点:
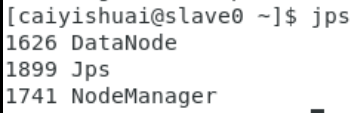
![]()
为了验证集群mapreduce工作是否正常,可以运行例子程序,例如:
进入相应目录hadoop-2.7/share/hadoop/mapreduce,执行:
hadoop jar hadoop-mapreduce-examples-2.7.7.jar pi 10 10
其中:第一个10是指运行10次map任务,第二个10是指每个map任务投掷次数,所以总投掷次数是10×10=100。如果显示:
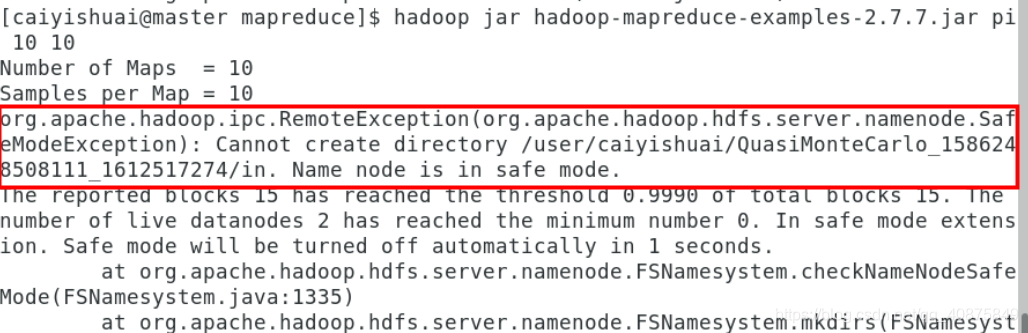
![]()
表明没有关闭安全模式,用下面的命令把安全模式关闭:
hdfs dfsadmin -safemode leave
然后再次执行后结果显示:

![]()
HDFS命令
hadoop fs展示所有命令
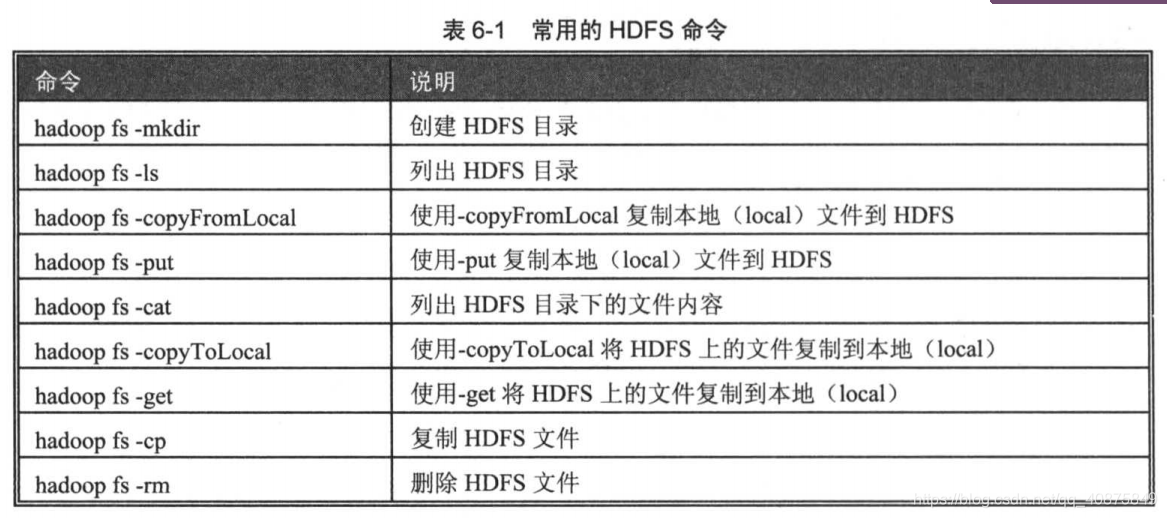
![]()
新建一个aaa的目录:
![]()
![]()

![]()
在浏览器中也可以查看,输入地址:master:50070
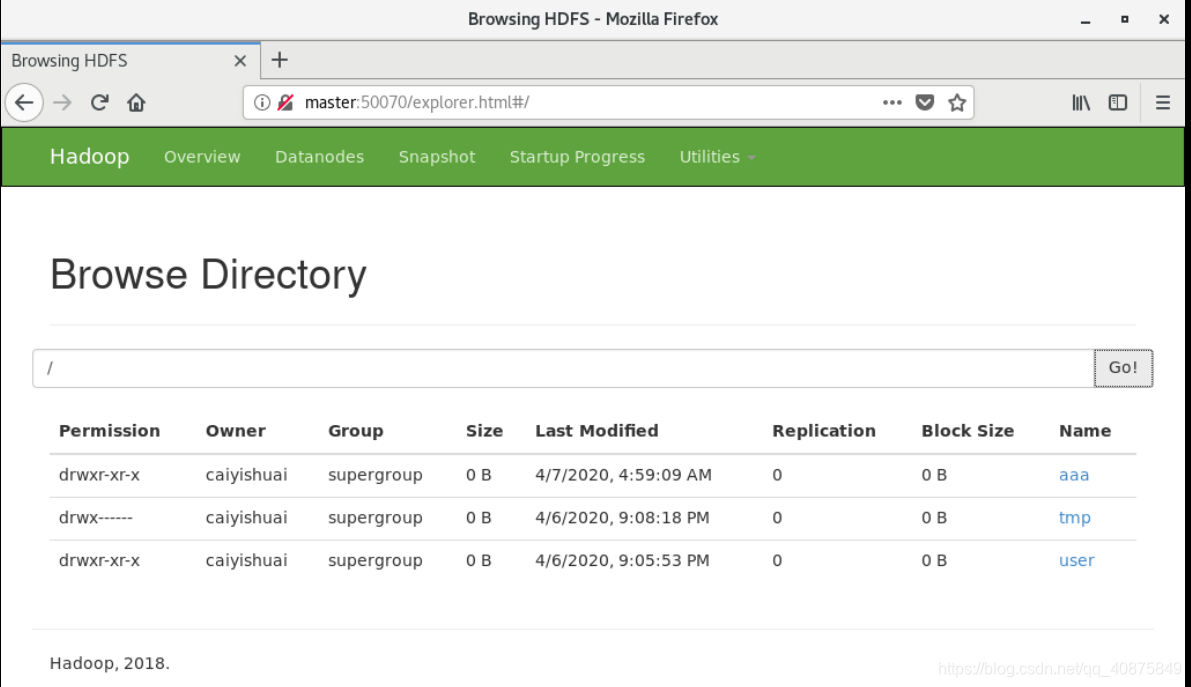
![]()
新建一个有内容的文件,上传至hdfs文件系统。
echo hello world >> abc.txt
hadoop fs -put abc.txt /aaa/
查找存储的具体位置,理解hdfs的工作基本原理。

![]()
也可以通过命令查看上传在即群里的文件。
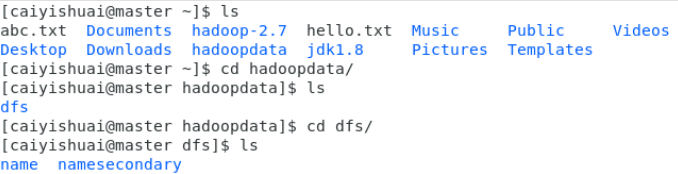
![]()

![]()
在master节点里存储的是文件的存储位置,在相应节点里可以找到上传的文件。

![]()
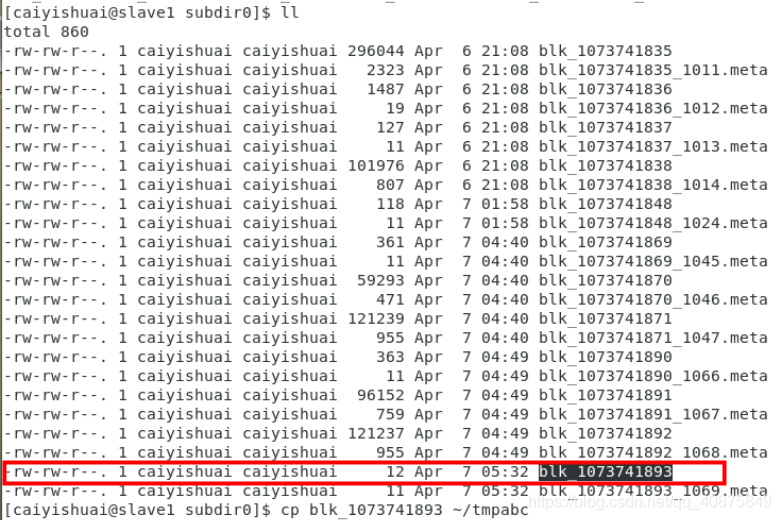
![]()
我们猜测它就是我们刚才上传的文件。将它拷贝到家目录下查看:
cp blk_1073741893 ~/tmpabc
再回到家目录查看刚才的文件,如图:
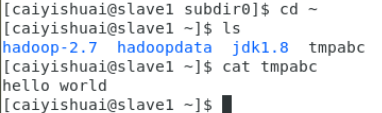
![]()
上传一个超过块大小的文件(当前块大小是128MB),查找具体位置和分块情况,并将分块重新组合,理解hdfs分块存储的原理。

![]()
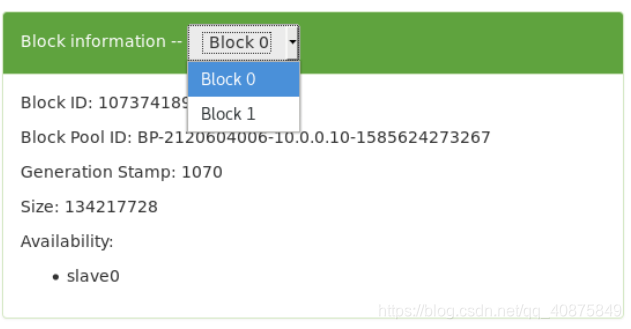
![]()
对hdfs文件系统,在哪个节点上操作没有区别,在非集群的主机上也可以操作hdfs文件系统。
2.在非集群的主机上操作hdfs文件系统
在进行操作的主机上需要有hadoop软件包,否则,hadoop命令没有解释器;hadoop包里必须有与集群配置相同的配置文件。
需要有与集群配置相同的jdk。
需要配置相应路径。
与集群内主机操作完全相同。
下面拿Ubuntu做实验。先配置jdk,解压并再.bashrc里配置环境变量。
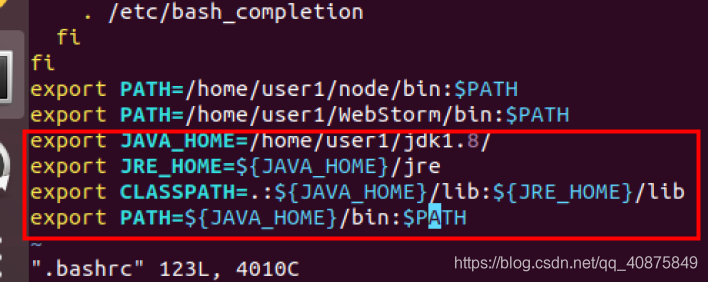
![]()

![]()
hadoop集群下程序开发
3.1拷贝解压eclipse软件
tar -zxvf eclipse-java-2020-03-R-linux-gtk-x86_64.tar.gz