大数据第8周
1.Wordcount程序的运行
1.1准备数据
上传到hdfs一个英文的文本文件,尽量不要在根目录下。文件内容也不要太多,可以自己数清楚有几个词,方便检查是否正确。
1.2写入运行参数
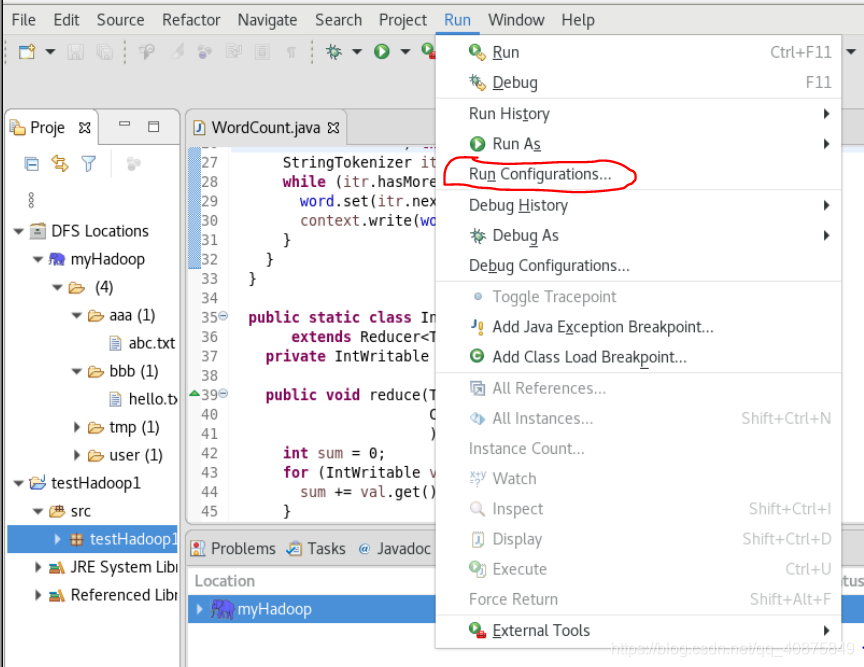
当前界面显示出要运行的程序,然后点击主菜单的“run”。
并选择“Run Configurations”
![]()
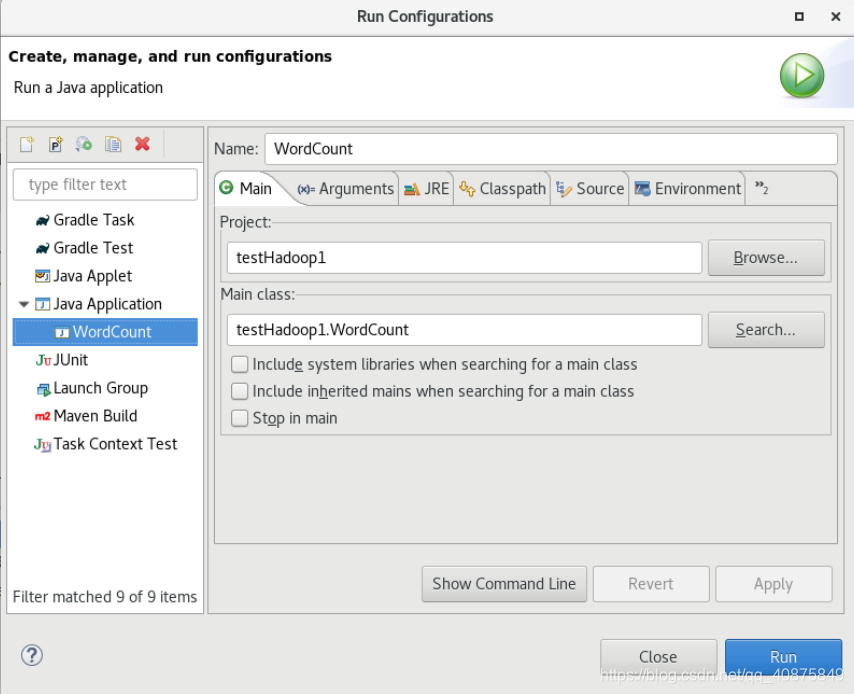
双击右侧“Java Appliction”,会自动显示“WordCount”,在“main”标签页,查看相关信息是否正确,
![]()
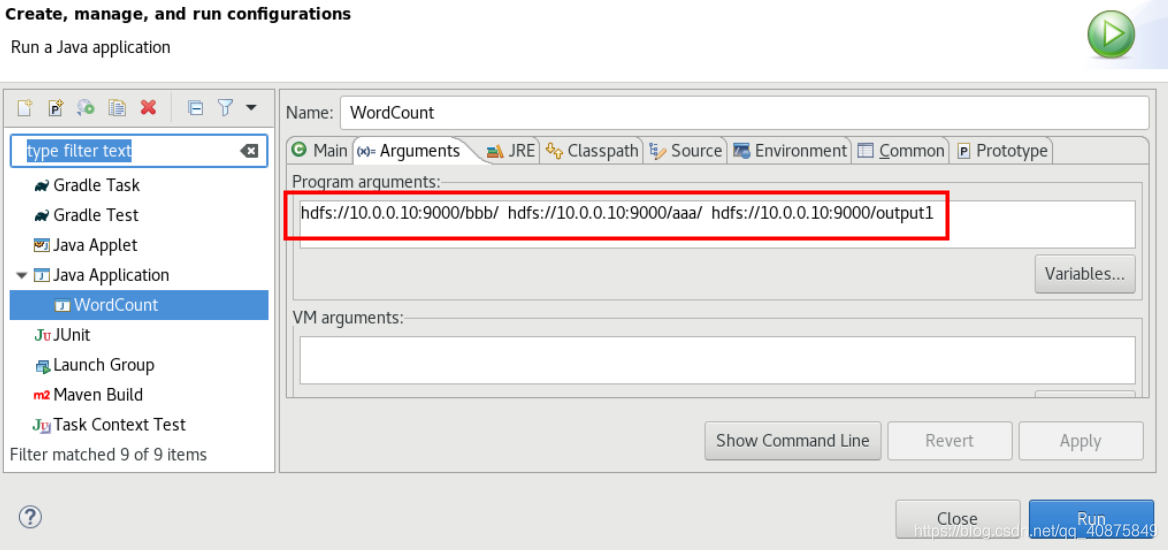
然后选择“Arguments”标签页,写入参数,前面的是输入文件的路径,最后一个是输出文件路径。输出文件路径一定是新路径(就是当前hdfs文件系统中没有的路径)。写好后,点击“Close”,在提示时选择“Save”。
![]()
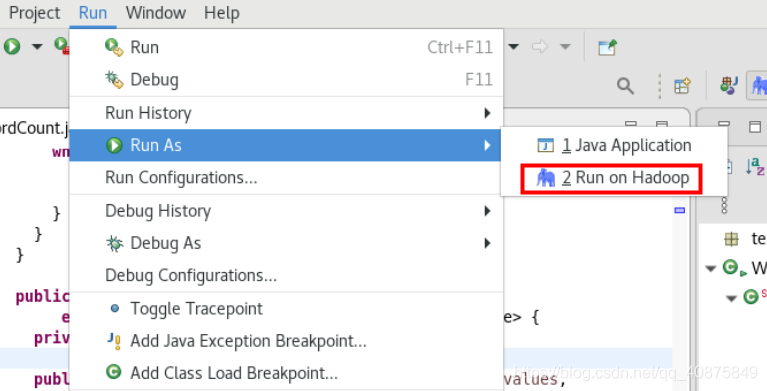
可以选择在菜单中选择“Run As”,或者程序上点击鼠标右键,弹出的快捷菜单里选择“Run As”,“Run on Hadoop”。
![]()
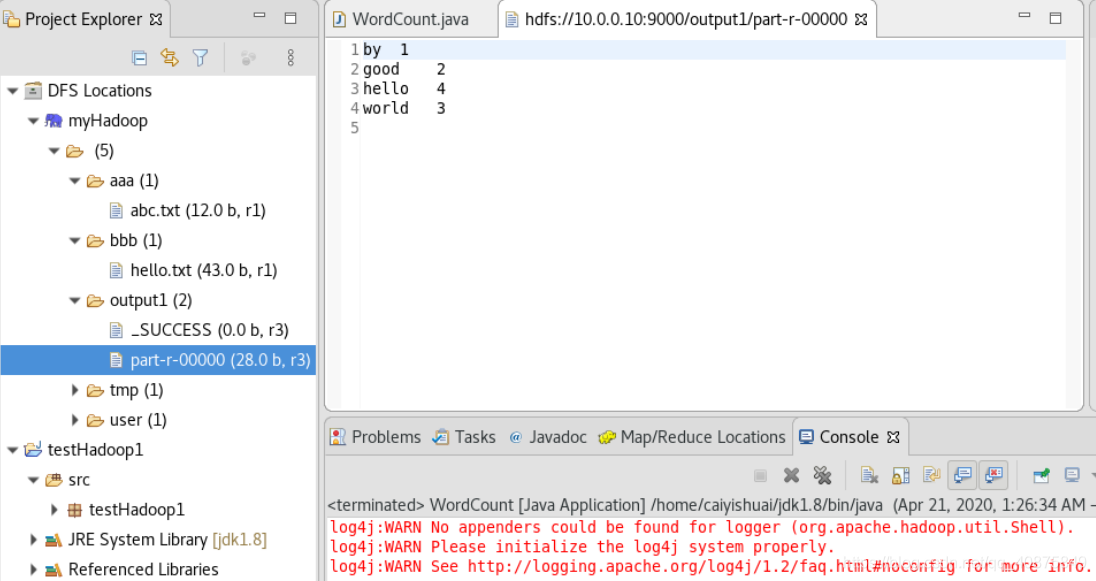
运行后的结果如下,“output1”里的文件将会显示程序的结果。
![]()
2.Spark下载解压及相关信息
下载解压spark2.4.5:tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz。
Spark的开发语言是scala。Scala是运行在jvm虚拟机上的。
在路径/home/user1/spark-2.4.5/bin下运行./spark-shell。
![]()
3.Scala语言环境
下载解压scala2.11.12:tar -zxvf scala-2.11.12.tgz。
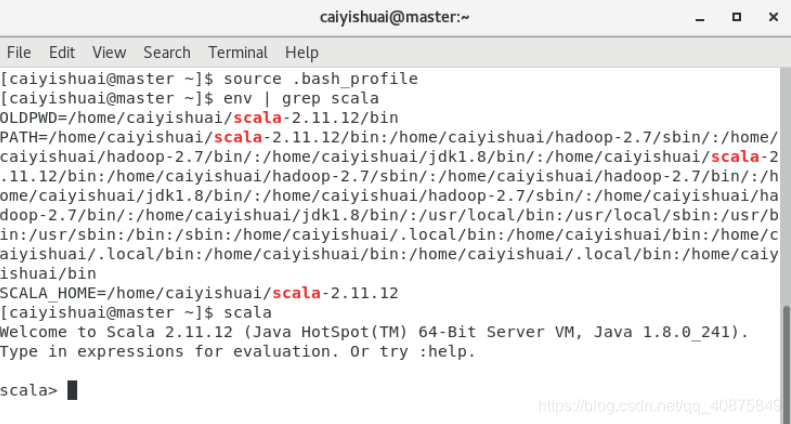
在路径/home/user1/scala-2.11.12/bin下运行./scala。
![]()
配置scala路径:vi .bash_profile,添加如下内容:
export SCALA_HOME=/home/caiyishuai/scala-2.11.12
export PATH=$SCALA_HOME/bin:$PATH
![]()
然后执行:source .bash_profile。
可以通过env | grep scala命令检查是否配置成功。
再直接执行:scala看是否能运行。

![]()
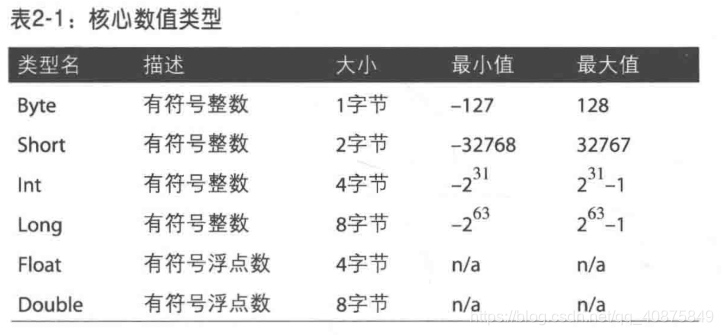
4.scala语言简介
4.1值和变量
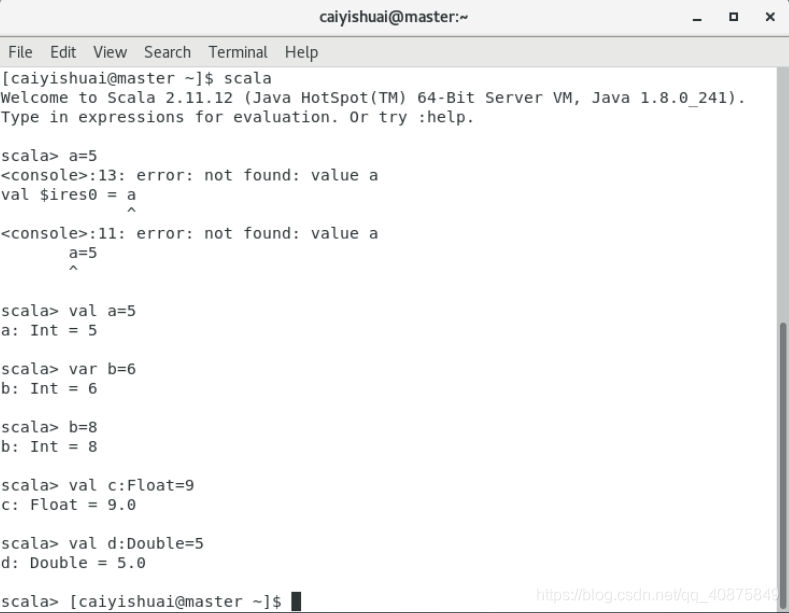
值:val
变量:var
“值”类型声明后不可以更改数值,而“变量”类型可以。
声明时可以指定数值类型,也可以不指定,不指定时系统会自动判定。
指定类型方式:用冒号“:”:例如:val c:Float=5
注意对大小写敏感。
![]()
![]()