我的代码:
# -*- coding: utf-8 -*- from pandas import read_csv import numpy as np from sklearn.datasets.base import Bunch import pickle # 导入cPickle包并且取一个别名pickle #持久化类 from sklearn.feature_extraction.text import TfidfVectorizer import jieba import operator # 排序用 from sklearn import metrics from sklearn.externals import joblib import xlwt #导入wordcloud模块和matplotlib模块 import wordcloud import matplotlib.pyplot as plt from scipy.misc import imread '''读取停用词''' def _readfile(path): with open(path, "rb") as fp: content = fp.read() return content ''' 读取bunch对象''' def _readbunchobj(path): with open(path, "rb") as file_obj: bunch = pickle.load(file_obj) return bunch '''写入bunch对象''' def _writebunchobj(path, bunchobj): with open(path, "wb") as file_obj: pickle.dump(bunchobj, file_obj) def buildtestbunch(bunch_path, art_test): bunch = Bunch(contents=[])#label=[], # ============================================================================= # for item1 in testlabel: # bunch.label.append(item1) # ============================================================================= # testContentdatasave=[] #存储所有训练和测试数据的分词 for item2 in art_test: item2 = str(item2) item2 = item2.replace(" ", "") item2 = item2.replace(" ", "") content_seg = jieba.cut(item2) save2 = '' for item3 in content_seg: if len(item3) > 1 and item3 != ' ': # testContentdatasave.append(item3) save2 = save2 + "," + item3 bunch.contents.append(save2) with open(bunch_path, "wb") as file_obj: pickle.dump(bunch, file_obj) print("构建测试数据文本对象结束!!!") def vector_space(stopword_path, bunch_path, space_path): stpwrdlst = _readfile(stopword_path).splitlines() # 读取停用词 bunch = _readbunchobj(bunch_path) # 导入分词后的词向量bunch对象 # 构建tf-idf词向量空间对象 tfidfspace = Bunch(label=bunch.label, tdm=[], vocabulary={}) # 权重矩阵tdm,其中,权重矩阵是一个二维矩阵,tdm[i][j]表示,第j个词(即词典中的序号)在第i个类别中的IF-IDF值 # 使用TfidVectorizer初始化向量空间模型 vectorizer = TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.5, min_df=0.0001, use_idf=True, max_features=15000) # print(vectorizer) # 文本转为词频矩阵,单独保存字典文件 tfidfspace.tdm = vectorizer.fit_transform(bunch.contents) tfidfspace.vocabulary = vectorizer.vocabulary_ # 创建词袋的持久化 _writebunchobj(space_path, tfidfspace) print("if-idf词向量空间实例创建成功!!!") def testvector_space(stopword_path, bunch_path, space_path, train_tfidf_path): stpwrdlst = _readfile(stopword_path).splitlines() # 把停用词变成列表 bunch = _readbunchobj(bunch_path) tfidfspace = Bunch(tdm=[], vocabulary={})#label=bunch.label, # 导入训练集的TF-IDF词向量空间 ★★ trainbunch = _readbunchobj(train_tfidf_path) tfidfspace.vocabulary = trainbunch.vocabulary vectorizer= TfidfVectorizer(stop_words=stpwrdlst, sublinear_tf=True, max_df=0.7, vocabulary=trainbunch.vocabulary, min_df=0.001) tfidfspace.tdm = vectorizer.fit_transform(bunch.contents) _writebunchobj(space_path, tfidfspace) print("if-idf词向量空间实例创建成功!!!") if __name__=="__main__": Sdata = [] art = [] '''============================先导入数据==================================''' file_test = 'F:/goverment/text analyse/type_in.csv' dataset = read_csv(file_test) Sdata = dataset.values[:, :] Sdata=Sdata.tolist() for line in Sdata: art.append(line[1])#line[1]为文本 print(len(Sdata)) '''==========================================================tf-idf对Bar进行文本特征提取============================================================================''' # 导入分词后的词向量bunch对象 test_bunch_path = "F:/goverment/text analyse/trainbunch.bat" test_space_path = "F:/goverment/text analyse/traintfdifspace.dat" stopword_path = "F:/goverment/text analyse/hlt_stop_words.txt" '''============================================================tf-idf对Sart进行文本特征提取==============================================================================''' buildtestbunch(test_bunch_path, art) testvector_space(stopword_path, test_bunch_path, test_space_path, test_space_path) test_set = _readbunchobj(test_space_path) '''测试数据''' #获取已知 id 找 文本 txtcut=[] #存放所有词 dic={} for i in test_set.vocabulary.keys(): txtcut.append(i) dic[test_set.vocabulary[i]]=i #print(dic) #print(test_set.tdm) #print(test_set.tdm[0]) #print(dir(test_set)) #print(test_set.vocabulary) #print(dir(test_set.tdm)) #print(Sdata) #print(nonzero[1]) '''final里放的是不超过15的词''' #print(Sdata) final=[] for k in range(len(Sdata)):#遍历每一条文本 nonzero=test_set.tdm[k].nonzero() ls=[] ls.append(Sdata[k][0]) num=0 for i in range(len(nonzero[1])): num=num+1 b=test_set.tdm[k, nonzero[1][i]]*100 #test_set.tdm[k, nonzero[1][i]]是第k条文本中,第i个权重非零的词权重 a= dic[nonzero[1][i]] +" "+str(round(b,2))+"%" ls.append(a) if num==15: break final.append(ls) '''画词云图''' fig = plt.figure(figsize = (15,15)) cloud = wordcloud.WordCloud(font_path='STXINGKA.TTF',mask=imread('water3.png'),mode='RGBA', background_color=None).generate(' '.join(txtcut)) img = imread('water3.png') cloud_colors = wordcloud.ImageColorGenerator(np.array(img)) cloud.recolor(color_func=cloud_colors) plt.imshow(cloud) plt.axis('off') plt.savefig('watercloud3.png',dpi=400) plt.show() myexcel = xlwt.Workbook() sheet = myexcel.add_sheet("sheet1") si=-1 sj=-1 for line in final: si=si+1 sj=-1 for i in line: sj=sj+1 sheet.write(si,sj,str(i)) myexcel.save("各条分词.xls") #把id存好 myexcel = xlwt.Workbook() sheet = myexcel.add_sheet("sheet2") p=0 for i in test_set.vocabulary.keys(): sheet.write(p,0,i) print(i) sheet.write(p,1,str(test_set.vocabulary[i])) p=p+1 myexcel.save("词汇id.xls")
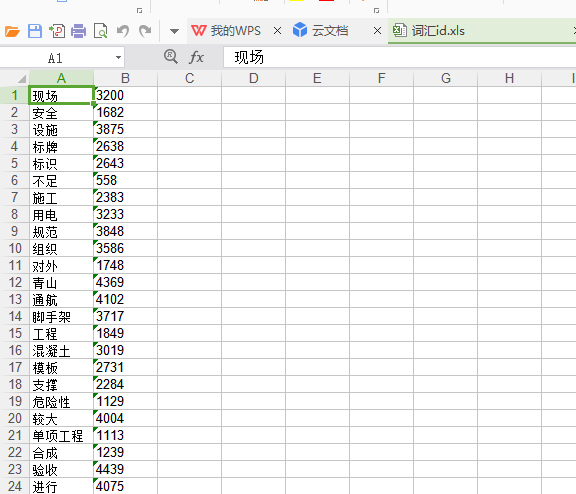
各条分词:
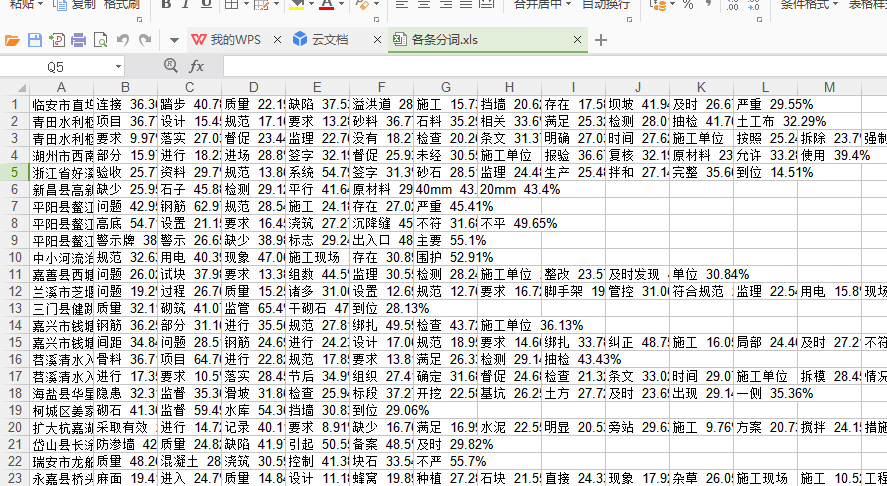
词汇id: