2020.3.26学习记录
1.独立与不相关的关系
在数学期望存在的情况下,独立一定不相关,不相关不一定独立。但对于二维正态随机变量 ((X,Y)) , (X) 和 (Y) 相互独立与 (X) 和 (Y) 不相关(即 (ρ_{xy} = 0))是等价的。
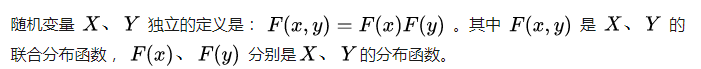
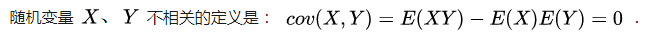
参考博客:独立和不相关的区别
2.等价关系是什么?

参考博客:等价,偏序和全序
3.解释数据结构里的KMP算法与BF算法
KMP算法用来解决字符串匹配问题,举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?一般情况下我们会采用暴力搜索的方法(也称为朴素字符串匹配算法),但是时间复杂度过高,考虑到字符串中已比较串可能和未比较的串重复,所以我们不用从头开始比较,而是借用这个关系跳过来继续向下比较。
BF算法就是我们所说道的暴力搜索算法,即不匹配则后移一位重新比较,时间复杂度比较高,理想时为 (O(n)) ,最坏时为 (O(n*m))
参考博客:字符串匹配的KMP算法
BF算法(串模式匹配算法)C语言详解
4.你在本科做的项目里应用了哪些专业课的知识呢?
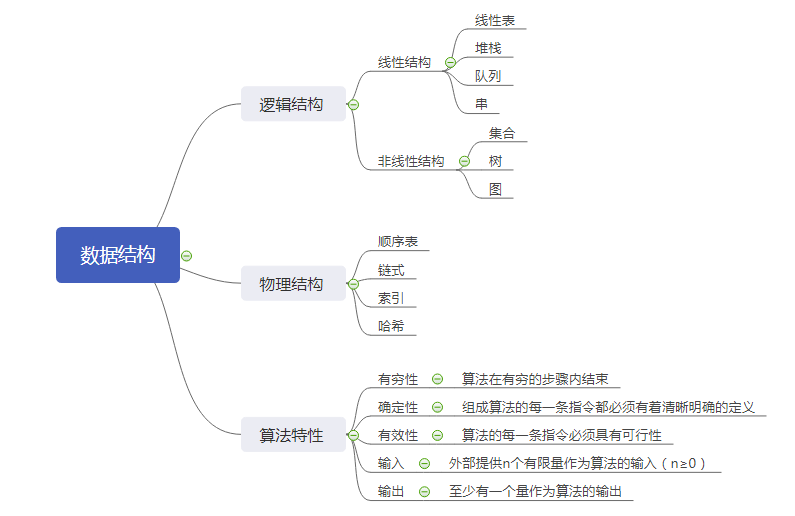
5.数据结构中线性结构和非线性结构有哪些?算法5个基本特性是什么?
6.死锁相关概念
死锁定义:指多个进程在运行过程中因争夺资源而造成的一种僵局,当进程处于这种僵持状态时,若无外力作用,它们都将无法再向前推进。(例如:当线程A持有独占锁a,并尝试去获取独占锁b的同时,线程B持有独占锁b,并尝试获取独占锁a的情况下,就会发生AB两个线程由于互相持有对方需要的锁,而发生的阻塞现象,我们称为死锁。)
产生原因:a.系统资源的竞争(系统中拥有的不可剥夺资源,数量不足以满足多个进程运行的需要,是的进程在运行过程中,会因为争夺资源而陷入僵局)
b.进程推进顺序非法(1.进程在运行过程中,请求和释放资源的顺序不当,如:二者保持对方需要的资源,有申请对方已占有的资源 2.信号量使用不当,进程彼此间互相等待对方发来的消息,结果也会使得这些进程间无法继续向前推进,如:A等B发消息,B又在等A发消息)
死锁产生的必要条件:a.互斥条件(在一段时间内某资源只能为一个进程所有)
b.不可剥夺条件(进程所占有的资源在未使用完毕之前,不能被其它进程强行夺走,只能是主动释放资源)
c.请求和保持条件(进程已经保持了至少一个资源,并请求新的资源,而新的资源却被其他进程占有)
d.循环等待条件(存在一个资源循环等待链,链中每一个进程已获得的资源同时被链中下一个进程锁请求)
死锁的处理策略:a.死锁预防(破坏死锁的四个必要条件)
b.死锁避免(在资源动态分配过程中,防止系统进入不安全状态 [已用资源 + 还需资源大于 > 系统可提供资源] 、银行家算法(最著名的死锁避免算法)
c.死锁检测(利用死锁定理 [能分配则去掉边,如果图中所有边都消去了,则该图是可完全化简的] 化简资源分配图 [圆圈代表进程,框代表资源,连线代表分配关系] 以检测死锁的存在 [死锁定理:S为死锁的等价条件为S状态的资源分配图是不可完全化简的] )
d.死锁解除(资源剥夺法 [挂起死锁进程,抢夺其资源给其它进程] 、撤销进程法 [强制撤销死锁进程,并剥夺其资源] 、进程回退法 [让一个或多个进程回退到足以回避死锁的地步] )
7.TCP和UDP的区别
a.基于连接与无连接
b.TCP要求系统资源较多,UDP较少;
c.UDP程序结构较简单
d.流模式(TCP)与数据报模式(UDP);
e.TCP保证数据正确性,UDP可能丢包
f.TCP保证数据顺序,UDP不保证
UDP应用场景:
a.面向数据报方式
b.网络数据大多为短消息
c.拥有大量Client
d.对数据安全性无特殊要求
e.网络负担非常重,但对响应速度要求高
TCP和UDP是OSI模型中的运输层中的协议。
UDP补充:
UDP不提供复杂的控制机制,利用IP提供无连接的通信服务。即使是出现网络拥堵的情况下,UDP也无法进行流量控制等避免网络拥塞的行为。此外,传输途中如果出现了丢包,UDP也不负责重发。甚至当出现包的到达顺序乱掉时也没有纠正的功能。如果需要这些细节控制,那么不得不交给由采用UDP的应用程序去处理。换句话说,UDP将部分控制转移到应用程序去处理,自己却只提供作为传输层协议的最基本功能。
TCP补充:
TCP充分实现了数据传输时各种控制功能,可以进行丢包的重发控制,还可以对次序乱掉的分包进行顺序控制。而这些在UDP中都没有。此外,TCP作为一种面向有连接的协议,只有在确认通信对端存在时才会发送数据,从而可以控制通信流量的浪费。TCP通过检验和、序列号、确认应答、重发控制、连接管理以及窗口控制等机制实现可靠性传输。
TCP与UDP区别总结:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的,此外,UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道
8.Socket套接字是什么?
在通信过程中,采用端口号和IP地址绑定使用,端口号和IP地址绑定后形成的标识称为插口(Socket),表示为 Socket=(IP Address:Port Number)
参考博客:简单理解Socket
9.UML统一建模语言(Unified Modeling Language)的9种建模图
9个图包括:用例图、类图、对象图、顺序图、协作图、状态图、活动图、构件图、部署图
参考博客:UML中的9种图
10.哈希函数的概念
为什么需要哈希:我们通常使用数组或者链表来存储元素,一旦存储的内容数量特别多,需要占用很大的空间,而且在查找某个元素是否存在的过程中,数组和链表都需要挨个循环比较,而通过 哈希 计算,可以大大减少比较次数。哈希 其实是随机存储的一种优化,先进行分类,然后查找时按照这个对象的分类去找。
哈希通过一次计算大幅度缩小查找范围,自然比从全部数据里查找速度要快。
例如: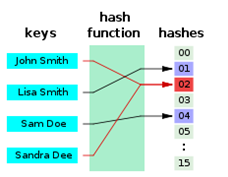
哈希函数举例:直接定址法(取关键字或关键字的某个线性函数值为散列地址)
除留余数法(取关键字被某个不大于散列表长度 m 的数 p 求余,得到的作为散列地址)
数学分析法(当关键字的位数大于地址的位数,对关键字的各位分布进行分析,选出分布均匀的任意几位作为散列地址)
平方取中法(先计算出关键字值的平方,然后取平方值中间几位作为散列地址)
随机数法(选择一个随机函数,把关键字的随机函数值作为它的哈希值)
解决哈希冲突:拉链法(将所有关键字为同义词的结点链接在同一个单链表中,如:凡是散列地址为 i 的结点,均插入到以 T[i] 为头指针的单链表中。)
开放定址法:当冲突发生时,使用某种探查(亦称探测)技术在散列表中寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到。
a.线性探查法(探查时从地址 d 开始,首先探查 T[d],然后依次探查 T[d+1],…,直到 T[m-1],此后又循环到 T[0],T[1],…,直到探查到 有空余地址 或者到 T[d-1]为止。)
b.二次探查法(探查时从地址 d 开始,首先探查 T[d],然后依次探查 T[d+12],T[d+22],T[d+3^2],…,等,直到探查到 有空余地址 或者到 T[d-1]为止)
c.双重散列法(探查时从地址 d 开始,首先探查 T[d],然后依次探查 T[d+h1(d)], T[d + 2*h1(d)],…,等。该方法使用了两个散列函数 h(key) 和 h1(key),故也称为双散列函数探查法)
参考博客:哈希函数
参考博客:哈希函数的构造方法
11.最短路径问题可用什么算法解决?
a.迪杰斯特拉算法(Dijkstra算法)
参考博客:复试专业课知识记录(3)
12.介绍一下DFS和BFS算法
a.DFS(深度优先搜索)
b.BFS(广度优先搜索)
参考博客:图的广度优先搜索(BFS)和深度优先搜索(DFS)算法解析
13.最小生成树是什么?怎么寻找?
一个有N个点的图,边一定是大于等于N-1条的。图的最小生成树,就是在这些边中选择N-1条出来,连接所有的N个点。这N-1条边的边权之和是所有方案中最小的。
解决什么问题:如何用最小的“代价”用N-1条边连接N个点的问题。(例如:城市管道连接)
生成算法:
a.Prim算法(普里姆算法)
b.Kruskal算法
参考博客:最小生成树-Prim算法和Kruskal算法
14.平衡二叉树是什么?
平衡二叉树建立在二叉排序树的基础上,目的是使二叉排序树的平均查找长度更小,即让各结点的深度尽可能小,因此,树中每个结点的两棵子树的深度不要偏差太大。
平衡二叉树的递归定义:平衡二叉树是一棵二叉树,其可以为空,或满足如下2个性质:①左右子树深度之差的绝对值不大于1。②左右子树都是平衡二叉树。
平衡因子的概念:结点的平衡因子 = 结点的左子树深度 — 结点的右子树深度。
最低不平衡结点的概念:用A表示最低不平衡结点,则A的祖先结点可能有不平衡的,但其所有后代结点都是平衡的。
实现平衡二叉树过程是通过在一棵平衡二叉树中依次插入元素(按照二叉排序树的方式),若出现不平衡,则要根据新插入的结点与最低不平衡结点的位置关系进行相应的调整。分为LL型、RR型、LR型和RL型4种类型
参考博客:平衡二叉树的实现原理
15.读一读意向导师的论文(最好有一两篇英文的,有可能被问到本科所做方向的顶级期刊名字和最近看的一篇英语论文以及它尚需改善的地方是什么等等。)
16.了解一些操作系统前沿的知识、信息