一.索引
索引主要是为了提高查询速度,能够提高查询速度的原因是将无序的数据变成有序(相对)
索引分聚集索引,非聚集索引
B+树索引,Hash索引
聚集索引:一般主键索引就是聚集索引,聚集索引的叶子节点存储表中的数据
非聚集索引:又称二级索引,非主键索引都称为非聚集索引,非聚集索引的叶子节点存储的是主键(为什么存储的主键,而不是记录所在地址呢,理由相当简单,因为记录所在地址并不能保证一定不会变,但主键可以保证。)
通过非聚集索引查找数据时,要先去找叶子节点的主键,再通过主键去查找所要的数据,这个过程叫做回表
这就引出了另一种索引
覆盖索引:从索引中直接查找结果,即要查询的字段和索引是对应的,避免了回表
B+树索引:一种平衡树,从根节点到叶子节点一层一层的查找数据,InnoDB默认就是B+树索引
Hash索引:对索引键值做hash运算,然后通过hash值查找所需的数据,很适合等值查询
重复值比较多的话,就不适合用Hash索引了
二.锁
数据库锁定机制简单来说就是数据库为了保证数据的一致性而使各种共享资源在被并发访问访问变得有序所设计的一种规则。下图来源于http://database.51cto.com/art/201810/585002.htm
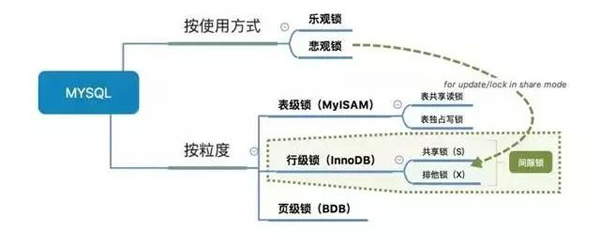
使用方式来分类:悲观锁和乐观锁
悲观锁是在使用数据之前,加行锁(使用 select * from tablename where id=2 for update手动加锁)
乐观锁是一种逻辑或者说一种思想,它不是数据库层面上的锁,要手动添加,一般额外加一个version字段
锁的粒度分类:表级锁,行级锁,页级锁
用的比较多的是表级锁和行级锁
表级锁:开销小,加锁快;不会出现死锁(因为MyISAM会一次性获得SQL所需的全部锁);锁定粒度大,发生锁冲突的概率最高,并发度最低。
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
MySIAM只支持表级锁,
InnoDB支持表级锁和行级锁
行锁跟索引有关,如果某行上没有索引,则会自动变为表锁
锁的类型分类:共享锁,排他锁,意向共享锁,意向排它锁
共享锁,排它锁按照锁的粒度都是行级锁
意向共享锁,意向排它锁 都是表级锁,主要是用来标记一个事务对于这张表操作的一个意向
共享锁:一般是查询的时候加共享锁,其他事务可以读,但是不能更改
排他锁:一般是修改操作时,加排他锁
意向共享锁:一个事务对某张表的一行加共享锁之前,必须加一个意向共享锁或者更强的锁
意向排他锁:一个事务对某张表的一行加排他锁之前,必须加一个意向排他锁
其他的锁还有间隙锁,记录锁,临键锁
间隙锁:锁住的是一个索引的范围,启用它有一个前置条件,就是数据库隔离级别必须是Repeatable Read(可重复读),这也是InnoDB的默认隔离级别,假设我们将隔离级别降到Read Committed(读提交),间隙锁将会自动失效。
间隙锁的使用,能够有效的防止幻读。
记录锁:锁住一条记录,这是Read Committed(读提交)事务级别的默认锁级别。记录锁是作用于索引的,所以,当查询不是作用于索引上时,系统会创建一个隐式的聚集索引,然后作用在索引上。
共享记录锁:select * from tablename where id=1 lock in share mode
排他记录锁:select * from tablename where id=1 for update
临键锁:临键锁就是记录锁+间隙锁的组合方式。这是Repeatable Read(可重复读)隔离级别的默认锁级别。使用临键锁有一个好处,就是,假设我们执行一个查询
select * from tablename where id = 1;
如果id是唯一索引,那么临键锁就会降级为记录锁,锁住这条记录,而不是去锁住一个范围。
这里引出两个概念:
锁等待:由于资源不足引起的排队等待现象
死锁:两个或多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环。
一般的处理方式是将持有最少行级锁的事务进行回滚。