本文主要讲一些 HTTP头部的信息
首先看一段 惊为天人 的文章。 来自于 《淘宝技术这十年》
你发现快要过年了,于是想给你的女朋友买一件毛衣,你打开了www.taobao.com。这时你的浏览器首先查询DNS服务器,将www.taobao.com转换成ip地址。不过首先你会发现,你在不同的地区或者不同的网络(电信、联通、移动)的情况下,转换后的ip地址很可能是不一样的,这首先涉及到负载均衡的第一步,通过DNS解析域名时将你的访问分配到不同的入口,同时尽可能保证你所访问的入口是所有入口中可能较快的一个(这和后文的CDN不一样)。
完整版在这里
总结一下就是,优秀的产品,每个细节都充满着技术。
这里具体阐述一下关于前端历程:
- 打开 www.taobao.com -> 浏览器查询 DNS 服务器(转换为IP地址)
但是不同的地方网速是不一样的。所以,涉及了 负载均衡 第一步,通过DNS解析域名的时候,将我们的访问 分配到不同的路口。尽可能保证我们每个人的 访问入口 是较快的那一个。
- 成功访问,则我们产生了一个 PV(page view-页面访问).
页面访问量是一个网站规模的重要指标。
- 很多人一起访问,负载均衡 变得尤为重要。
- HTML内容生成。浏览器准备加载 css、js、图片等样式、脚本和资源文件。
浏览器在同一个域名下 并发加载的资源数量 是有限的。例如 IE6 2个,IE8 6个,Chrome某个旧版本 6个。若访问淘宝网需要 126 个资源,如此小的并发量将会导致页面加载 非常慢。
- 所以我们需要 CDN。
通过保证 CDN 是我们家最近的 来提升速度。因为 不同地区 不同网络,距离服务器的远近,都会导致 速度变化。
大厂果然不容易。
接下来进入正题,HTTP 头部怎么看?这里其实看一次很容易就忘了。。基本上只有经验多了,才能够熟悉
来吧,让我们去百度 搜一搜 前端有什么 鸟东西?他妈的真多,越学越多。无底洞!
当我在百度的 搜索框 输入了 前端 的时候
当我 加了个 1,但是并没有点搜索
我又加了个 2
同时我们还发现了 百度 人道的黑科技,那就是我们 还没有点 搜索 其实,百度已经在发送请求了。这就是 预读的技术!! 监听了用户的输入
下面停止我的 小学生 似的惊讶。成熟。成熟。我们开始 分析 HTTP 头部,它主要由四部分组成。
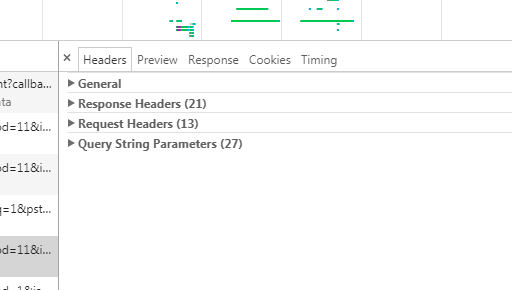
- 通用头部
- 响应头部
- 请求头部
- 查询字符串参数(有时候没有,不信你看看我这篇文章有没有,可能是你得点搜索)
1. 通用头部
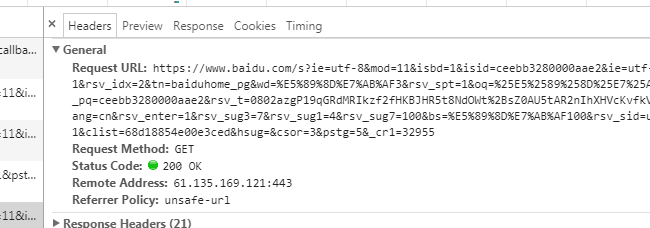
- Request URL 请求的URL地址
- Request Method 请求方式
- Status Code 状态码
- Remote Address 路由地址
- Referrer Policy 常用于 分析用户来源信息,也是 不安全因素。暴露了。
2. 响应头部
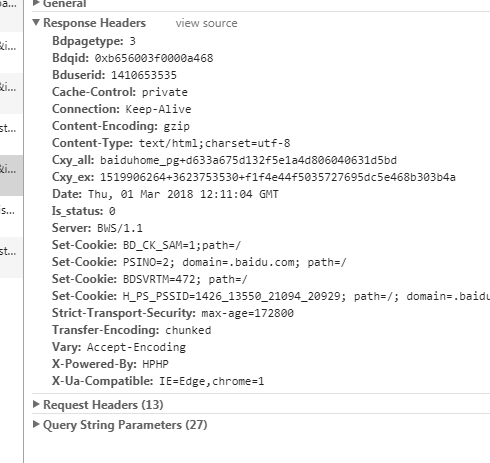
- Cache-Control 服务器应该遵循的缓存机制
- public 可以用 Cached 内容回应 任何用户
- private 只能用缓存内容 回应 先前请求该内容的那个用户
- no-cache 可以缓存,但只有 web 服务器验证了 有效之后,才返回给客户端
- max-age 本响应包含的对象的过期时间
- ALL no-store(不允许缓存)
- Connection 是否需要 持久链接
- close 连接已经关闭
- keepalive 连接保持,等待后续连接
- keep-Alive 如果浏览器保持连接,头部希望 Web 服务器有确定的时间。比如
Keep-Alive: 300
- Content-Encoding 服务器表明自己使用了什么 压缩方法 压缩响应中的对象
- Content-Type 服务器表明自己响应的对象类型
3. 请求头部
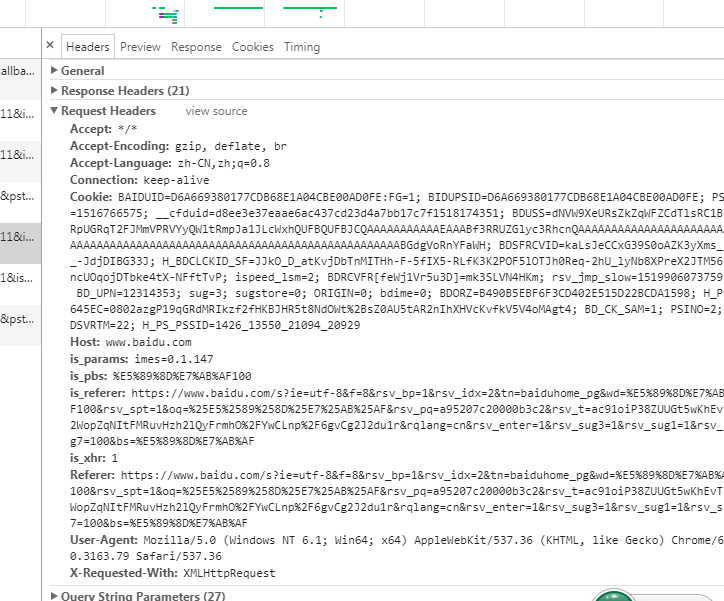
- Accept 告诉Web服务器自己接受什么介质类型。
*/*表示任何类型 - Accept-Encoding 浏览器申明自己接受的编码方法
- Accept-Charset 浏览器申明自己接受的字符集。
- Accept-Language 浏览器申明自己接受的语言。
语言!==字符集。语言和字符集的区别:中文是语言,中文有多种字符集。
- Connection 表示是否需要持久连接。具体同上。
- Cookie 这是最重要的 请求头信息之一
- Host 发送请求页面所在域
- Referer 发送请求页面URL。浏览器告诉Web服务器自己从 哪个网页 获得/点击 的网址/URL。
- User-Agent 浏览器表明自己的身份。
4. 查询头部
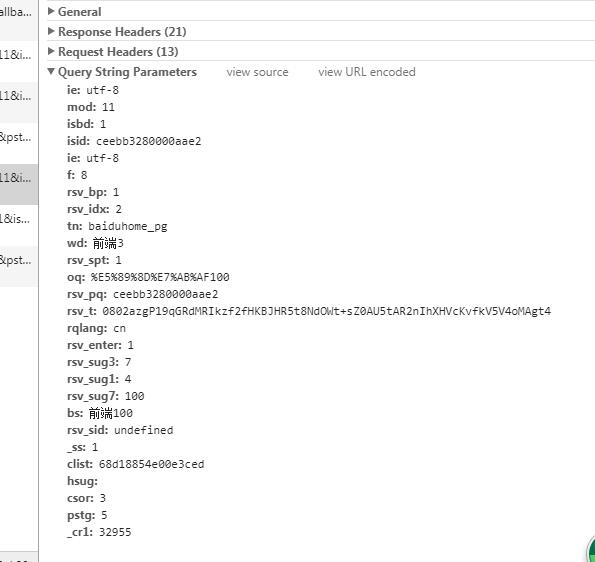
这里主要 定义 被传送资源的信息。