关于
- 深入理解 Java 8 Lambda(语言篇——lambda,方法引用,目标类型和默认方法)
- 深入理解 Java 8 Lambda(类库篇——Streams API,Collector 和并行)
- 深入理解 Java 8 Lambda(原理篇——Java 编译器如何处理 lambda)
本文是深入理解 Java 8 Lambda 系列的第一篇,主要介绍 Java 8 新增的语言特性(比如 lambda 和方法引用),语言概念(比如目标类型和变量捕获)以及设计思路。
本文是对 Brian Goetz 的 State of Lambda 一文的翻译,那么问题来了:
为什么要翻译这个系列?
- 工作之后,我开始大量使用 Java
- 公司将会在不久的未来使用 Java 8
- 作为资质平庸的开发者,我需要打一点提前量,以免到时拙计
- 为了学习Java 8(主要是其中的 lambda 及相关库),我先后阅读了Oracle的 官方文档,Cay Horstmann(Core Java的作者)的 Java 8 for the Really Impatient 和Richard Warburton的 Java 8 Lambdas
- 但我感到并没有多大收获,Oracle的官方文档涉及了 lambda 表达式的每一个概念,但都是点到辄止;后两本书(尤其是Java 8 Lambdas)花了大量篇幅介绍 Java lambda 及其类库,但实质内容不多,读完了还是没有对Java lambda产生一个清晰的认识
- 关键在于这些文章和书都没有解决我对Java lambda的困惑,比如:
- Java 8 中的 lambda 为什么要设计成这样?(为什么要一个 lambda 对应一个接口?而不是 Structural Typing?)
- lambda 和匿名类型的关系是什么?lambda 是匿名对象的语法糖吗?
- Java 8 是如何对 lambda 进行类型推导的?它的类型推导做到了什么程度?
- Java 8 为什么要引入默认方法?
- Java 编译器如何处理 lambda?
- 等等……
- 之后我在 Google 搜索这些问题,然后就找到 Brian Goetz 的三篇关于Java lambda的文章(State of Lambda,State of Lambda libraries version 和 Translation of lambda),读完之后上面的问题都得到了解决
- 为了加深理解,我决定翻译这一系列文章
警告(Caveats)
如果你不知道什么是函数式编程,或者不了解 map,filter,reduce 这些常用的高阶函数,那么你不适合阅读本文,请先学习函数式编程基础(比如 这本书)。
State of Lambda by Brian Goetz
The high-level goal of Project Lambda is to enable programming patterns that require modeling code as data to be convenient and idiomatic in Java.
关于
本文介绍了 Java SE 8 中新引入的 lambda 语言特性以及这些特性背后的设计思想。这些特性包括:
- lambda 表达式(又被成为“闭包”或“匿名方法”)
- 方法引用和构造方法引用
- 扩展的目标类型和类型推导
- 接口中的默认方法和静态方法
1. 背景
Java 是一门面向对象编程语言。面向对象编程语言和函数式编程语言中的基本元素(Basic Values)都可以动态封装程序行为:面向对象编程语言使用带有方法的对象封装行为,函数式编程语言使用函数封装行为。但这个相同点并不明显,因为Java 对象往往比较“重量级”:实例化一个类型往往会涉及不同的类,并需要初始化类里的字段和方法。
不过有些 Java 对象只是对单个函数的封装。例如下面这个典型用例:Java API 中定义了一个接口(一般被称为回调接口),用户通过提供这个接口的实例来传入指定行为,例如:
|
public interface ActionListener { void actionPerformed(ActionEvent e); } |
这里并不需要专门定义一个类来实现 ActionListener,因为它只会在调用处被使用一次。用户一般会使用匿名类型把行为内联(inline):
|
1 2 3 4 5 |
button.addActionListener(new ActionListener() { public void actionPerformed(ActionEvent e) { ui.dazzle(e.getModifiers()); } }); |
很多库都依赖于上面的模式。对于并行 API 更是如此,因为我们需要把待执行的代码提供给并行 API,并行编程是一个非常值得研究的领域,因为在这里摩尔定律得到了重生:尽管我们没有更快的 CPU 核心(core),但是我们有更多的 CPU 核心。而串行 API 就只能使用有限的计算能力。
随着回调模式和函数式编程风格的日益流行,我们需要在Java中提供一种尽可能轻量级的将代码封装为数据(Model code as data)的方法。匿名内部类并不是一个好的 选择,因为:
- 语法过于冗余
- 匿名类中的
this和变量名容易使人产生误解 - 类型载入和实例创建语义不够灵活
- 无法捕获非
final的局部变量 - 无法对控制流进行抽象
上面的多数问题均在Java SE 8中得以解决:
- 通过提供更简洁的语法和局部作用域规则,Java SE 8 彻底解决了问题 1 和问题 2
- 通过提供更加灵活而且便于优化的表达式语义,Java SE 8 绕开了问题 3
- 通过允许编译器推断变量的“常量性”(finality),Java SE 8 减轻了问题 4 带来的困扰
不过,Java SE 8 的目标并非解决所有上述问题。因此捕获可变变量(问题 4)和非局部控制流(问题 5)并不在 Java SE 8的范畴之内。(尽管我们可能会在未来提供对这些特性的支持)
2. 函数式接口(Functional interfaces)
尽管匿名内部类有着种种限制和问题,但是它有一个良好的特性,它和Java类型系统结合的十分紧密:每一个函数对象都对应一个接口类型。之所以说这个特性是良好的,是因为:
- 接口是 Java 类型系统的一部分
- 接口天然就拥有其运行时表示(Runtime representation)
- 接口可以通过 Javadoc 注释来表达一些非正式的协定(contract),例如,通过注释说明该操作应可交换(commutative)
上面提到的 ActionListener 接口只有一个方法,大多数回调接口都拥有这个特征:比如 Runnable接口和 Comparator 接口。我们把这些只拥有一个方法的接口称为 函数式接口。(之前它们被称为 SAM类型,即 单抽象方法类型(Single Abstract Method))
我们并不需要额外的工作来声明一个接口是函数式接口:编译器会根据接口的结构自行判断(判断过程并非简单的对接口方法计数:一个接口可能冗余的定义了一个 Object 已经提供的方法,比如 toString(),或者定义了静态方法或默认方法,这些都不属于函数式接口方法的范畴)。不过API作者们可以通过 @FunctionalInterface 注解来显式指定一个接口是函数式接口(以避免无意声明了一个符合函数式标准的接口),加上这个注解之后,编译器就会验证该接口是否满足函数式接口的要求。
实现函数式类型的另一种方式是引入一个全新的 结构化 函数类型,我们也称其为“箭头”类型。例如,一个接收 String 和 Object 并返回 int 的函数类型可以被表示为 (String, Object) -> int。我们仔细考虑了这个方式,但出于下面的原因,最终将其否定:
- 它会为Java类型系统引入额外的复杂度,并带来 结构类型(Structural Type) 和 指名类型(Nominal Type) 的混用。(Java 几乎全部使用指名类型)
- 它会导致类库风格的分歧——一些类库会继续使用回调接口,而另一些类库会使用结构化函数类型
- 它的语法会变得十分笨拙,尤其在包含受检异常(checked exception)之后
- 每个函数类型很难拥有其运行时表示,这意味着开发者会受到 类型擦除(erasure) 的困扰和局限。比如说,我们无法对方法
m(T->U)和m(X->Y)进行重载(Overload)
所以我们选择了“使用已知类型”这条路——因为现有的类库大量使用了函数式接口,通过沿用这种模式,我们使得现有类库能够直接使用 lambda 表达式。例如下面是 Java SE 7 中已经存在的函数式接口:
- java.lang.Runnable
- java.util.concurrent.Callable
- java.security.PrivilegedAction
- java.util.Comparator
- java.io.FileFilter
- java.beans.PropertyChangeListener
除此之外,Java SE 8中增加了一个新的包:java.util.function,它里面包含了常用的函数式接口,例如:
Predicate<T>——接收T并返回booleanConsumer<T>——接收T,不返回值Function<T, R>——接收T,返回RSupplier<T>——提供T对象(例如工厂),不接收值UnaryOperator<T>——接收T对象,返回TBinaryOperator<T>——接收两个T,返回T
除了上面的这些基本的函数式接口,我们还提供了一些针对原始类型(Primitive type)的特化(Specialization)函数式接口,例如 IntSupplier 和 LongBinaryOperator。(我们只为 int、long 和 double 提供了特化函数式接口,如果需要使用其它原始类型则需要进行类型转换)同样的我们也提供了一些针对多个参数的函数式接口,例如 BiFunction<T, U, R>,它接收 T 对象和 U对象,返回 R 对象。
3. lambda表达式(lambda expressions)
匿名类型最大的问题就在于其冗余的语法。有人戏称匿名类型导致了“高度问题”(height problem):比如前面 ActionListener 的例子里的五行代码中仅有一行在做实际工作。
lambda表达式是匿名方法,它提供了轻量级的语法,从而解决了匿名内部类带来的“高度问题”。
下面是一些lambda表达式:
|
1 2 3 |
(int x, int y) -> x + y () -> 42 (String s) -> { System.out.println(s); } |
第一个 lambda 表达式接收 x 和 y 这两个整形参数并返回它们的和;第二个 lambda 表达式不接收参数,返回整数 ‘42’;第三个 lambda 表达式接收一个字符串并把它打印到控制台,不返回值。
lambda 表达式的语法由参数列表、箭头符号 -> 和函数体组成。函数体既可以是一个表达式,也可以是一个语句块:
- 表达式:表达式会被执行然后返回执行结果。
- 语句块:语句块中的语句会被依次执行,就像方法中的语句一样——
return语句会把控制权交给匿名方法的调用者break和continue只能在循环中使用- 如果函数体有返回值,那么函数体内部的每一条路径都必须返回值
表达式函数体适合小型 lambda 表达式,它消除了 return 关键字,使得语法更加简洁。
lambda 表达式也会经常出现在嵌套环境中,比如说作为方法的参数。为了使 lambda 表达式在这些场景下尽可能简洁,我们去除了不必要的分隔符。不过在某些情况下我们也可以把它分为多行,然后用括号包起来,就像其它普通表达式一样。
下面是一些出现在语句中的 lambda 表达式:
|
1 2 3 4 5 6 7 8 |
FileFilter java = (File f) -> f.getName().endsWith("*.java"); String user = doPrivileged(() -> System.getProperty("user.name")); new Thread(() -> { connectToService(); sendNotification(); }).start(); |
4. 目标类型(Target typing)
需要注意的是,函数式接口的名称并不是 lambda 表达式的一部分。那么问题来了,对于给定的 lambda 表达式,它的类型是什么?答案是:它的类型是由其上下文推导而来。例如,下面代码中的 lambda 表达式类型是 ActionListener:
|
1 |
ActionListener l = (ActionEvent e) -> ui.dazzle(e.getModifiers()); |
这就意味着同样的 lambda 表达式在不同上下文里可以拥有不同的类型:
|
1 2 3 |
Callable<String> c = () -> "done"; PrivilegedAction<String> a = () -> "done"; |
第一个 lambda 表达式 () -> "done" 是 Callable 的实例,而第二个 lambda 表达式则是 PrivilegedAction 的实例。
编译器负责推导 lambda 表达式类型。它利用 lambda 表达式所在上下文 所期待的类型 进行推导,这个 被期待的类型 被称为 目标类型。lambda 表达式只能出现在目标类型为函数式接口的上下文中。
当然,lambda 表达式对目标类型也是有要求的。编译器会检查 lambda 表达式的类型和目标类型的方法签名(method signature)是否一致。当且仅当下面所有条件均满足时,lambda 表达式才可以被赋给目标类型 T:
T是一个函数式接口- lambda 表达式的参数和
T的方法参数在数量和类型上一一对应 - lambda 表达式的返回值和
T的方法返回值相兼容(Compatible) - lambda 表达式内所抛出的异常和
T的方法throws类型相兼容
由于目标类型(函数式接口)已经“知道” lambda 表达式的形式参数(Formal parameter)类型,所以我们没有必要把已知类型再重复一遍。也就是说,lambda 表达式的参数类型可以从目标类型中得出:
|
1 |
Comparator<String> c = (s1, s2) -> s1.compareToIgnoreCase(s2); |
在上面的例子里,编译器可以推导出 s1 和 s2 的类型是 String。此外,当 lambda 的参数只有一个而且它的类型可以被推导得知时,该参数列表外面的括号可以被省略:
|
1 2 3 |
FileFilter java = f -> f.getName().endsWith(".java"); button.addActionListener(e -> ui.dazzle(e.getModifiers())); |
这些改进进一步展示了我们的设计目标:“不要把高度问题转化成宽度问题。”我们希望语法元素能够尽可能的少,以便代码的读者能够直达 lambda 表达式的核心部分。
lambda 表达式并不是第一个拥有上下文相关类型的 Java 表达式:泛型方法调用和“菱形”构造器调用也通过目标类型来进行类型推导:
|
1 2 3 4 5 |
List<String> ls = Collections.emptyList(); List<Integer> li = Collections.emptyList(); Map<String, Integer> m1 = new HashMap<>(); Map<Integer, String> m2 = new HashMap<>(); |
5. 目标类型的上下文(Contexts for target typing)
之前我们提到 lambda 表达式智能出现在拥有目标类型的上下文中。下面给出了这些带有目标类型的上下文:
- 变量声明
- 赋值
- 返回语句
- 数组初始化器
- 方法和构造方法的参数
- lambda 表达式函数体
- 条件表达式(
? :) - 转型(Cast)表达式
在前三个上下文(变量声明、赋值和返回语句)里,目标类型即是被赋值或被返回的类型:
|
1 2 3 4 5 6 7 8 |
Comparator<String> c; c = (String s1, String s2) -> s1.compareToIgnoreCase(s2); public Runnable toDoLater() { return () -> { System.out.println("later"); } } |
数组初始化器和赋值类似,只是这里的“变量”变成了数组元素,而类型是从数组类型中推导得知:
|
1 2 3 4 |
filterFiles( new FileFilter[] { f -> f.exists(), f -> f.canRead(), f -> f.getName().startsWith("q") }); |
方法参数的类型推导要相对复杂些:目标类型的确认会涉及到其它两个语言特性:重载解析(Overload resolution)和参数类型推导(Type argument inference)。
重载解析会为一个给定的方法调用(method invocation)寻找最合适的方法声明(method declaration)。由于不同的声明具有不同的签名,当 lambda 表达式作为方法参数时,重载解析就会影响到 lambda 表达式的目标类型。编译器会通过它所得之的信息来做出决定。如果 lambda 表达式具有 显式类型(参数类型被显式指定),编译器就可以直接 使用lambda 表达式的返回类型;如果lambda表达式具有 隐式类型(参数类型被推导而知),重载解析则会忽略 lambda 表达式函数体而只依赖 lambda 表达式参数的数量。
如果在解析方法声明时存在二义性(ambiguous),我们就需要利用转型(cast)或显式 lambda 表达式来提供更多的类型信息。如果 lambda 表达式的返回类型依赖于其参数的类型,那么 lambda 表达式函数体有可能可以给编译器提供额外的信息,以便其推导参数类型。
|
1 2 |
List<Person> ps = ... Stream<String> names = ps.stream().map(p -> p.getName()); |
在上面的代码中,ps 的类型是 List<Person>,所以 ps.stream() 的返回类型是 Stream<Person>。map() 方法接收一个类型为 Function<T, R> 的函数式接口,这里 T 的类型即是 Stream 元素的类型,也就是 Person,而 R 的类型未知。由于在重载解析之后 lambda 表达式的目标类型仍然未知,我们就需要推导 R 的类型:通过对 lambda 表达式函数体进行类型检查,我们发现函数体返回 String,因此 R 的类型是 String,因而 map() 返回 Stream<String>。绝大多数情况下编译器都能解析出正确的类型,但如果碰到无法解析的情况,我们则需要:
- 使用显式 lambda 表达式(为参数
p提供显式类型)以提供额外的类型信息 - 把 lambda 表达式转型为
Function<Person, String> - 为泛型参数
R提供一个实际类型。(.<String>map(p -> p.getName()))
lambda 表达式本身也可以为它自己的函数体提供目标类型,也就是说 lambda 表达式可以通过外部目标类型推导出其内部的返回类型,这意味着我们可以方便的编写一个返回函数的函数:
|
1 |
Supplier<Runnable> c = () -> () -> { System.out.println("hi"); }; |
类似的,条件表达式可以把目标类型“分发”给其子表达式:
|
1 |
Callable<Integer> c = flag ? (() -> 23) : (() -> 42); |
最后,转型表达式(Cast expression)可以显式提供 lambda 表达式的类型,这个特性在无法确认目标类型时非常有用:
|
1 2 |
// Object o = () -> { System.out.println("hi"); }; 这段代码是非法的 Object o = (Runnable) () -> { System.out.println("hi"); }; |
除此之外,当重载的方法都拥有函数式接口时,转型可以帮助解决重载解析时出现的二义性。
目标类型这个概念不仅仅适用于 lambda 表达式,泛型方法调用和“菱形”构造方法调用也可以从目标类型中受益,下面的代码在 Java SE 7 是非法的,但在 Java SE 8 中是合法的:
|
1 2 3 |
List<String> ls = Collections.checkedList(new ArrayList<>(), String.class); Set<Integer> si = flag ? Collections.singleton(23) : Collections.emptySet(); |
6. 词法作用域(Lexical scoping)
在内部类中使用变量名(以及 this)非常容易出错。内部类中通过继承得到的成员(包括来自 Object 的方法)可能会把外部类的成员掩盖(shadow),此外未限定(unqualified)的 this 引用会指向内部类自己而非外部类。
相对于内部类,lambda 表达式的语义就十分简单:它不会从超类(supertype)中继承任何变量名,也不会引入一个新的作用域。lambda 表达式基于词法作用域,也就是说 lambda 表达式函数体里面的变量和它外部环境的变量具有相同的语义(也包括 lambda 表达式的形式参数)。此外,’this’ 关键字及其引用在 lambda 表达式内部和外部也拥有相同的语义。
为了进一步说明词法作用域的优点,请参考下面的代码,它会把 "Hello, world!" 打印两遍:
|
1 2 3 4 5 6 7 8 9 10 11 |
public class Hello { Runnable r1 = () -> { System.out.println(this); } Runnable r2 = () -> { System.out.println(toString()); } public String toString() { return "Hello, world"; } public static void main(String... args) { new Hello().r1.run(); new Hello().r2.run(); } } |
与之相类似的内部类实现则会打印出类似 Hello$1@5b89a773 和 Hello$2@537a7706 之类的字符串,这往往会使开发者大吃一惊。
基于词法作用域的理念,lambda 表达式不可以掩盖任何其所在上下文中的局部变量,它的行为和那些拥有参数的控制流结构(例如 for 循环和 catch 从句)一致。
个人补充:这个说法很拗口,所以我在这里加一个例子以演示词法作用域:
|
1 2 3 4 5 |
int i = 0; int sum = 0; for (int i = 1; i < 10; i += 1) { //这里会出现编译错误,因为i已经在for循环外部声明过了 sum += i; } |
7. 变量捕获(Variable capture)
在 Java SE 7 中,编译器对内部类中引用的外部变量(即捕获的变量)要求非常严格:如果捕获的变量没有被声明为 final 就会产生一个编译错误。我们现在放宽了这个限制——对于 lambda 表达式和内部类,我们允许在其中捕获那些符合 有效只读(Effectively final)的局部变量。
简单的说,如果一个局部变量在初始化后从未被修改过,那么它就符合有效只读的要求,换句话说,加上 final 后也不会导致编译错误的局部变量就是有效只读变量。
|
1 2 3 4 |
Callable<String> helloCallable(String name) { String hello = "Hello"; return () -> (hello + ", " + name); } |
对 this 的引用,以及通过 this 对未限定字段的引用和未限定方法的调用在本质上都属于使用 final 局部变量。包含此类引用的 lambda 表达式相当于捕获了 this 实例。在其它情况下,lambda 对象不会保留任何对 this 的引用。
这个特性对内存管理是一件好事:内部类实例会一直保留一个对其外部类实例的强引用,而那些没有捕获外部类成员的 lambda 表达式则不会保留对外部类实例的引用。要知道内部类的这个特性往往会造成内存泄露。
尽管我们放宽了对捕获变量的语法限制,但试图修改捕获变量的行为仍然会被禁止,比如下面这个例子就是非法的:
|
1 2 |
int sum = 0; list.forEach(e -> { sum += e.size(); }); |
为什么要禁止这种行为呢?因为这样的 lambda 表达式很容易引起 race condition。除非我们能够强制(最好是在编译时)这样的函数不能离开其当前线程,但如果这么做了可能会导致更多的问题。简而言之,lambda 表达式对 值 封闭,对 变量 开放。
个人补充:lambda 表达式对 值 封闭,对 变量 开放的原文是:lambda expressions close over values, not variables,我在这里增加一个例子以说明这个特性:
|
1 2 3 4 5 |
int sum = 0; list.forEach(e -> { sum += e.size(); }); // Illegal, close over values List<Integer> aList = new List<>(); list.forEach(e -> { aList.add(e); }); // Legal, open over variables |
lambda 表达式不支持修改捕获变量的另一个原因是我们可以使用更好的方式来实现同样的效果:使用规约(reduction)。java.util.stream 包提供了各种通用的和专用的规约操作(例如 sum、min 和 max),就上面的例子而言,我们可以使用规约操作(在串行和并行下都是安全的)来代替 forEach:
|
1 2 3 4 |
int sum = list.stream() .mapToInt(e -> e.size()) .sum(); |
sum() 等价于下面的规约操作:
|
1 2 3 4 |
int sum = list.stream() .mapToInt(e -> e.size()) .reduce(0 , (x, y) -> x + y); |
规约需要一个初始值(以防输入为空)和一个操作符(在这里是加号),然后用下面的表达式计算结果:
|
1 |
0 + list[0] + list[1] + list[2] + ... |
规约也可以完成其它操作,比如求最小值、最大值和乘积等等。如果操作符具有可结合性(associative),那么规约操作就可以容易的被并行化。所以,与其支持一个本质上是并行而且容易导致 race condition 的操作,我们选择在库中提供一个更加并行友好且不容易出错的方式来进行累积(accumulation)。
8. 方法引用(Method references)
lambda 表达式允许我们定义一个匿名方法,并允许我们以函数式接口的方式使用它。我们也希望能够在 已有的 方法上实现同样的特性。
方法引用和 lambda 表达式拥有相同的特性(例如,它们都需要一个目标类型,并需要被转化为函数式接口的实例),不过我们并不需要为方法引用提供方法体,我们可以直接通过方法名称引用已有方法。
以下面的代码为例,假设我们要按照 name 或 age 为 Person 数组进行排序:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
class Person { private final String name; private final int age; public int getAge() { return age; } public String getName() {return name; } ... } Person[] people = ... Comparator<Person> byName = Comparator.comparing(p -> p.getName()); Arrays.sort(people, byName); |
在这里我们可以用方法引用代替lambda表达式:
|
1 |
Comparator<Person> byName = Comparator.comparing(Person::getName); |
这里的 Person::getName 可以被看作为 lambda 表达式的简写形式。尽管方法引用不一定(比如在这个例子里)会把语法变的更紧凑,但它拥有更明确的语义——如果我们想要调用的方法拥有一个名字,我们就可以通过它的名字直接调用它。
因为函数式接口的方法参数对应于隐式方法调用时的参数,所以被引用方法签名可以通过放宽类型,装箱以及组织到参数数组中的方式对其参数进行操作,就像在调用实际方法一样:
|
1 2 3 4 |
Consumer<Integer> b1 = System::exit; // void exit(int status) Consumer<String[]> b2 = Arrays:sort; // void sort(Object[] a) Consumer<String> b3 = MyProgram::main; // void main(String... args) Runnable r = Myprogram::mapToInt // void main(String... args) |
9. 方法引用的种类(Kinds of method references)
方法引用有很多种,它们的语法如下:
- 静态方法引用:
ClassName::methodName - 实例上的实例方法引用:
instanceReference::methodName - 超类上的实例方法引用:
super::methodName - 类型上的实例方法引用:
ClassName::methodName - 构造方法引用:
Class::new - 数组构造方法引用:
TypeName[]::new
对于静态方法引用,我们需要在类名和方法名之间加入 :: 分隔符,例如 Integer::sum
对于具体对象上的实例方法引用,我们则需要在对象名和方法名之间加入分隔符:
|
1 2 |
Set<String> knownNames = ... Predicate<String> isKnown = knownNames::contains; |
这里的隐式 lambda 表达式(也就是实例方法引用)会从 knownNames 中捕获 String 对象,而它的方法体则会通过Set.contains 使用该 String 对象。
有了实例方法引用,在不同函数式接口之间进行类型转换就变的很方便:
|
1 2 |
Callable<Path> c = ... Privileged<Path> a = c::call; |
引用任意对象的实例方法则需要在实例方法名称和其所属类型名称间加上分隔符:
|
1 |
Function<String, String> upperfier = String::toUpperCase; |
这里的隐式 lambda 表达式(即 String::toUpperCase 实例方法引用)有一个 String 参数,这个参数会被 toUpperCase 方法使用。
如果类型的实例方法是泛型的,那么我们就需要在 :: 分隔符前提供类型参数,或者(多数情况下)利用目标类型推导出其类型。
需要注意的是,静态方法引用和类型上的实例方法引用拥有一样的语法。编译器会根据实际情况做出决定。
一般我们不需要指定方法引用中的参数类型,因为编译器往往可以推导出结果,但如果需要我们也可以显式在 :: 分隔符之前提供参数类型信息。
和静态方法引用类似,构造方法也可以通过 new 关键字被直接引用:
|
1 |
SocketImplFactory factory = MySocketImpl::new; |
如果类型拥有多个构造方法,那么我们就会通过目标类型的方法参数来选择最佳匹配,这里的选择过程和调用构造方法时的选择过程是一样的。
如果待实例化的类型是泛型的,那么我们可以在类型名称之后提供类型参数,否则编译器则会依照”菱形”构造方法调用时的方式进行推导。
数组的构造方法引用的语法则比较特殊,为了便于理解,你可以假想存在一个接收 int 参数的数组构造方法。参考下面的代码:
|
1 2 |
IntFunction<int[]> arrayMaker = int[]::new; int[] array = arrayMaker.apply(10) // 创建数组 int[10] |
10. 默认方法和静态接口方法(Default and static interface methods)
lambda 表达式和方法引用大大提升了 Java 的表达能力(expressiveness),不过为了使把 代码即数据 (code-as-data)变的更加容易,我们需要把这些特性融入到已有的库之中,以便开发者使用。
Java SE 7 时代为一个已有的类库增加功能是非常困难的。具体的说,接口在发布之后就已经被定型,除非我们能够一次性更新所有该接口的实现,否则向接口添加方法就会破坏现有的接口实现。默认方法(之前被称为 虚拟扩展方法 或 守护方法)的目标即是解决这个问题,使得接口在发布之后仍能被逐步演化。
这里给出一个例子,我们需要在标准集合 API 中增加针对 lambda 的方法。例如 removeAll 方法应该被泛化为接收一个函数式接口 Predicate,但这个新的方法应该被放在哪里呢?我们无法直接在 Collection 接口上新增方法——不然就会破坏现有的 Collection 实现。我们倒是可以在 Collections 工具类中增加对应的静态方法,但这样就会把这个方法置于“二等公民”的境地。
默认方法 利用面向对象的方式向接口增加新的行为。它是一种新的方法:接口方法可以是 抽象的 或是 默认的。默认方法拥有其默认实现,实现接口的类型通过继承得到该默认实现(如果类型没有覆盖该默认实现)。此外,默认方法不是抽象方法,所以我们可以放心的向函数式接口里增加默认方法,而不用担心函数式接口的单抽象方法限制。
下面的例子展示了如何向 Iterator 接口增加默认方法 skip:
|
1 2 3 4 5 6 7 8 9 |
interface Iterator<E> { boolean hasNext(); E next(); void remove(); default void skip(int i) { for ( ; i > 0 && hasNext(); i -= 1) next(); } } |
根据上面的 Iterator 定义,所有实现 Iterator 的类型都会自动继承 skip 方法。在使用者的眼里,skip 不过是接口新增的一个虚拟方法。在没有覆盖 skip 方法的 Iterator 子类实例上调用 skip 会执行 skip 的默认实现:调用 hasNext 和 next 若干次。子类可以通过覆盖 skip 来提供更好的实现——比如直接移动游标(cursor),或是提供为操作提供原子性(Atomicity)等。
当接口继承其它接口时,我们既可以为它所继承而来的抽象方法提供一个默认实现,也可以为它继承而来的默认方法提供一个新的实现,还可以把它继承而来的默认方法重新抽象化。
除了默认方法,Java SE 8 还在允许在接口中定义 静态 方法。这使得我们可以从接口直接调用和它相关的辅助方法(Helper method),而不是从其它的类中调用(之前这样的类往往以对应接口的复数命名,例如 Collections)。比如,我们一般需要使用静态辅助方法生成实现 Comparator 的比较器,在Java SE 8中我们可以直接把该静态方法定义在 Comparator 接口中:
|
1 2 3 4 |
public static <T, U extends Comparable<? super U>> Comparator<T> comparing(Function<T, U> keyExtractor) { return (c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2)); } |
11. 继承默认方法(Inheritance of default methods)
和其它方法一样,默认方法也可以被继承,大多数情况下这种继承行为和我们所期待的一致。不过,当类型或者接口的超类拥有多个具有相同签名的方法时,我们就需要一套规则来解决这个冲突:
- 类的方法(class method)声明优先于接口默认方法。无论该方法是具体的还是抽象的。
- 被其它类型所覆盖的方法会被忽略。这条规则适用于超类型共享一个公共祖先的情况。
为了演示第二条规则,我们假设 Collection 和 List 接口均提供了 removeAll 的默认实现,然后 Queue 继承并覆盖了 Collection 中的默认方法。在下面的 implement 从句中,List 中的方法声明会优先于 Queue 中的方法声明:
|
1 |
class LinkedList<E> implements List<E>, Queue<E> { ... } |
当两个独立的默认方法相冲突或是默认方法和抽象方法相冲突时会产生编译错误。这时程序员需要显式覆盖超类方法。一般来说我们会定义一个默认方法,然后在其中显式选择超类方法:
|
1 2 3 |
interface Robot implements Artist, Gun { default void draw() { Artist.super.draw(); } } |
super 前面的类型必须是有定义或继承默认方法的类型。这种方法调用并不只限于消除命名冲突——我们也可以在其它场景中使用它。
最后,接口在 inherits 和 extends 从句中的声明顺序和它们被实现的顺序无关。
12. 融会贯通(Putting it together)
我们在设计lambda时的一个重要目标就是新增的语言特性和库特性能够无缝结合(designed to work together)。接下来,我们通过一个实际例子(按照姓对名字列表进行排序)来演示这一点:
比如说下面的代码:
|
1 2 3 4 5 6 |
List<Person> people = ... Collections.sort(people, new Comparator<Person>() { public int compare(Person x, Person y) { return x.getLastName().compareTo(y.getLastName()); } }) |
冗余代码实在太多了!
有了lambda表达式,我们可以去掉冗余的匿名类:
|
1 2 |
Collections.sort( people, (Person x, Person y) -> x.getLastName().compareTo(y.getLastName())); |
尽管代码简洁了很多,但它的抽象程度依然很差:开发者仍然需要进行实际的比较操作(而且如果比较的值是原始类型那么情况会更糟),所以我们要借助 Comparator 里的 comparing 方法实现比较操作:
|
1 |
Collections.sort(people, Comparator.comparing((Person p) -> p.getLastName())); |
在类型推导和静态导入的帮助下,我们可以进一步简化上面的代码:
|
1 |
Collections.sort(people, comparing(p -> p.getLastName())); |
我们注意到这里的 lambda 表达式实际上是 getLastName 的代理(forwarder),于是我们可以用方法引用代替它:
|
1 |
Collections.sort(people, comparing(Person::getLastName)); |
最后,使用 Collections.sort 这样的辅助方法并不是一个好主意:它不但使代码变的冗余,也无法为实现 List 接口的数据结构提供特定(specialized)的高效实现,而且由于 Collections.sort 方法不属于 List 接口,用户在阅读 List 接口的文档时不会察觉在另外的 Collections 类中还有一个针对 List 接口的排序(sort())方法。
默认方法可以有效的解决这个问题,我们为 List 增加默认方法 sort(),然后就可以这样调用:
|
1 |
people.sort(comparing(Person::getLastName));; |
此外,如果我们为 Comparator 接口增加一个默认方法 reversed()(产生一个逆序比较器),我们就可以非常容易的在前面代码的基础上实现降序排序。
|
1 |
people.sort(comparing(Person::getLastName).reversed());; |
13. 小结(Summary)
Java SE 8 提供的新语言特性并不算多——lambda 表达式,方法引用,默认方法和静态接口方法,以及范围更广的类型推导。但是把它们结合在一起之后,开发者可以编写出更加清晰简洁的代码,类库编写者可以编写更加强大易用的并行类库。
===============================================================================================
本文是深入理解 Java 8 Lambda 系列的第二篇,主要介绍 Java 8 针对新增语言特性而新增的类库(例如 Streams API、Collectors 和并行)。
本文是对 Brian Goetz的State of the Lambda: Libraries Edition 一文的翻译。
Java SE 8 增加了新的语言特性(例如 lambda 表达式和默认方法),为此 Java SE 8 的类库也进行了很多改进,本文简要介绍了这些改进。在阅读本文前,你应该先阅读 深入浅出Java 8 Lambda(语言篇),以便对 Java SE 8 的新增特性有一个全面了解。
背景(Background)
自从lambda表达式成为Java语言的一部分之后,Java集合(Collections)API就面临着大幅变化。而 JSR 355(规定了 Java lambda 表达式的标准)的正式启用更是使得 Java 集合 API 变的过时不堪。尽管我们可以从头实现一个新的集合框架(比如“Collection II”),但取代现有的集合框架是一项非常艰难的工作,因为集合接口渗透了 Java 生态系统的每个角落,将它们一一换成新类库需要相当长的时间。因此,我们决定采取演化的策略(而非推倒重来)以改进集合 API:
- 为现有的接口(例如
Collection,List和Stream)增加扩展方法; - 在类库中增加新的 流(stream,即
java.util.stream.Stream)抽象以便进行聚集(aggregation)操作; - 改造现有的类型使之可以提供流视图(stream view);
- 改造现有的类型使之可以容易的使用新的编程模式,这样用户就不必抛弃使用以久的类库,例如
ArrayList和HashMap(当然这并不是说集合 API 会常驻永存,毕竟集合 API 在设计之初并没有考虑到 lambda 表达式。我们可能会在未来的 JDK 中添加一个更现代的集合类库)。
除了上面的改进,还有一项重要工作就是提供更加易用的并行(Parallelism)库。尽管 Java 平台已经对并行和并发提供了强有力的支持,然而开发者在实际工作(将串行代码并行化)中仍然会碰到很多问题。因此,我们希望 Java 类库能够既便于编写串行代码也便于编写并行代码,因此我们把编程的重点从具体执行细节(how computation should be formed)转移到抽象执行步骤(what computation should be perfomed)。除此之外,我们还需要在将并行变的 容易(easier)和将并行变的 不可见(invisible)之间做出抉择,我们选择了一个折中的路线:提供 显式(explicit)但 非侵入(unobstrusive)的并行。(如果把并行变的透明,那么很可能会引入不确定性(nondeterminism)以及各种数据竞争(data race)问题)
内部迭代和外部迭代(Internal vs external iteration)
集合类库主要依赖于 外部迭代(external iteration)。Collection 实现 Iterable 接口,从而使得用户可以依次遍历集合的元素。比如我们需要把一个集合中的形状都设置成红色,那么可以这么写:
|
2 3 |
for (Shape shape : shapes) { shape.setColor(RED); } |
这个例子演示了外部迭代:for-each 循环调用 shapes 的 iterator() 方法进行依次遍历。外部循环的代码非常直接,但它有如下问题:
- Java 的 for 循环是串行的,而且必须按照集合中元素的顺序进行依次处理;
- 集合框架无法对控制流进行优化,例如通过排序、并行、短路(short-circuiting)求值以及惰性求值改善性能。
尽管有时 for-each 循环的这些特性(串行,依次)是我们所期待的,但它对改善性能造成了阻碍。
我们可以使用 内部迭代(internal iteration)替代外部迭代,用户把对迭代的控制权交给类库,并向类库传递迭代时所需执行的代码。
下面是前例的内部迭代代码:
|
1 |
shapes.forEach(s -> s.setColor(RED)); |
尽管看起来只是一个小小的语法改动,但是它们的实际差别非常巨大。用户把对操作的控制权交还给类库,从而允许类库进行各种各样的优化(例如乱序执行、惰性求值和并行等等)。总的来说,内部迭代使得外部迭代中不可能实现的优化成为可能。
外部迭代同时承担了 做什么(把形状设为红色)和 怎么做(得到 Iterator 实例然后依次遍历)两项职责,而内部迭代只负责 做什么,而把 怎么做 留给类库。通过这样的职责转变:用户的代码会变得更加清晰,而类库则可以进行各种优化,从而使所有用户都从中受益。
流(Stream)
流 是 Java SE 8 类库中新增的关键抽象,它被定义于 java.util.stream(这个包里有若干流类型:Stream<T> 代表对象引用流,此外还有一系列特化(specialization)流,比如 IntStream 代表整形数字流)。每个流代表一个值序列,流提供一系列常用的聚集操作,使得我们可以便捷的在它上面进行各种运算。集合类库也提供了便捷的方式使我们可以以操作流的方式使用集合、数组以及其它数据结构。
流的操作可以被组合成 流水线(Pipeline)。以前面的例子为例,如果我们只想把蓝色改成红色:
|
1 2 3 |
shapes.stream() .filter(s -> s.getColor() == BLUE) .forEach(s -> s.setColor(RED)); |
在 Collection 上调用 stream() 会生成该集合元素的流视图(stream view),接下来 filter()操作会产生只包含蓝色形状的流,最后,这些蓝色形状会被 forEach 操作设为红色。
如果我们想把蓝色的形状提取到新的 List 里,则可以:
|
1 2 3 4 |
List<Shape> blue = shapes.stream() .filter(s -> s.getColor() == BLUE) .collect(Collectors.toList()); |
collect() 操作会把其接收的元素聚集(aggregate)到一起(这里是 List),collect() 方法的参数则被用来指定如何进行聚集操作。在这里我们使用 toList() 以把元素输出到 List 中。(如需更多 collect() 方法的细节,请阅读 Collectors 一节)
如果每个形状都被保存在 Box 里,然后我们想知道哪个盒子至少包含一个蓝色形状,我们可以这么写:
|
1 2 3 4 5 |
Set<Box> hasBlueShape = shapes.stream() .filter(s -> s.getColor() == BLUE) .map(s -> s.getContainingBox()) .collect(Collectors.toSet()); |
map() 操作通过映射函数(这里的映射函数接收一个形状,然后返回包含它的盒子)对输入流里面的元素进行依次转换,然后产生新流。
如果我们需要得到蓝色物体的总重量,我们可以这样表达:
|
1 2 3 4 5 |
int sum = shapes.stream() .filter(s -> s.getColor() == BLUE) .mapToInt(s -> s.getWeight()) .sum(); |
这些例子演示了流框架的设计,以及如何使用流框架解决实际问题。
流和集合(Streams vs Collections)
集合和流尽管在表面上看起来很相似,但它们的设计目标是不同的:集合主要用来对其元素进行有效(effective)的管理和访问(access),而流并不支持对其元素进行直接操作或直接访问,而只支持通过声明式操作在其上进行运算然后得到结果。除此之外,流和集合还有一些其它不同:
- 无存储:流并不存储值;流的元素源自数据源(可能是某个数据结构、生成函数或 I/O 通道等等),通过一系列计算步骤得到;
- 天然的函数式风格(Functional in nature):对流的操作会产生一个结果,但流的数据源不会被修改;
- 惰性求值:多数流操作(包括过滤、映射、排序以及去重)都可以以惰性方式实现。这使得我们可以用一遍遍历完成整个流水线操作,并可以用短路操作提供更高效的实现;
- 无需上界(Bounds optional):不少问题都可以被表达为无限流(infinite stream):用户不停地读取流直到满意的结果出现为止(比如说,枚举 完美数 这个操作可以被表达为在所有整数上进行过滤)。集合是有限的,但流不是(操作无限流时我们必需使用短路操作,以确保操作可以在有限时间内完成);
从API的角度来看,流和集合完全互相独立,不过我们可以既把集合作为流的数据源(Collection拥有 stream() 和 parallelStream() 方法),也可以通过流产生一个集合(使用前例的 collect() 方法)。Collection 以外的类型也可以作为 stream 的数据源,比如JDK中的 BufferedReader、Random 和 BitSet 已经被改造可以用做流的数据源,Arrays.stream() 则产生给定数组的流视图。事实上,任何可以用 Iterator 描述的对象都可以成为流的数据源,如果有额外的信息(比如大小、是否有序等特性),库还可以进行进一步的优化。
惰性(Laziness)
过滤和映射这样的操作既可以被 急性求值(以 filter 为例,急性求值需要在方法返回前完成对所有元素的过滤),也可以被 惰性求值(用 Stream 代表过滤结果,当且仅当需要时才进行过滤操作)在实际中进行惰性运算可以带来很多好处。比如说,如果我们进行惰性过滤,我们就可以把过滤和流水线里的其它操作混合在一起,从而不需要对数据进行多遍遍历。相类似的,如果我们在一个大型集合里搜索第一个满足某个条件的元素,我们可以在找到后直接停止,而不是继续处理整个集合。(这一点对无限数据源是很重要,惰性求值对于有限数据源起到的是优化作用,但对无限数据源起到的是决定作用,没有惰性求值,对无限数据源的操作将无法终止)
对于过滤和映射这样的操作,我们很自然的会把它当成是惰性求值操作,不过它们是否真的是惰性取决于它们的具体实现。另外,像 sum() 这样生成值的操作和 forEach() 这样产生副作用的操作都是“天然急性求值”,因为它们必须要产生具体的结果。
以下面的流水线为例:
|
1 2 3 4 5 |
int sum = shapes.stream() .filter(s -> s.getColor() == BLUE) .mapToInt(s -> s.getWeight()) .sum(); |
这里的过滤操作和映射操作是惰性的,这意味着在调用 sum() 之前,我们不会从数据源提取任何元素。在 sum 操作开始之后,我们把过滤、映射以及求和混合在对数据源的一遍遍历之中。这样可以大大减少维持中间结果所带来的开销。
大多数循环都可以用数据源(数组、集合、生成函数以及I/O管道)上的聚合操作来表示:进行一系列惰性操作(过滤和映射等操作),然后用一个急性求值操作(forEach,toArray 和 collect等操作)得到最终结果——例如过滤—映射—累积,过滤—映射—排序—遍历等组合操作。惰性操作一般被用来计算中间结果,这在Streams API设计中得到了很好的体现——与其让 filter 和 map 返回一个集合,我们选择让它们返回一个新的流。在 Streams API 中,返回流对象的操作都是惰性操作,而返回非流对象的操作(或者无返回值的操作,例如 forEach())都是急性操作。绝大多数情况下,潜在的惰性操作会被用于聚合,这正是我们想要的——流水线中的每一轮操作都会接收输入流中的元素,进行转换,然后把转换结果传给下一轮操作。
在使用这种 数据源—惰性操作—惰性操作—急性操作 流水线时,流水线中的惰性几乎是不可见的,因为计算过程被夹在数据源和最终结果(或副作用操作)之间。这使得API的可用性和性能得到了改善。
对于 anyMatch(Predicate) 和 findFirst() 这些急性求值操作,我们可以使用短路(short-circuiting)来终止不必要的运算。以下面的流水线为例:
|
1 2 3 4 |
Optional<Shape> firstBlue = shapes.stream() .filter(s -> s.getColor() == BLUE) .findFirst(); |
由于过滤这一步是惰性的,findFirst 在从其上游得到一个元素之后就会终止,这意味着我们只会处理这个元素及其之前的元素,而不是所有元素。findFirst() 方法返回 Optional 对象,因为集合中有可能不存在满足条件的元素。Optional 是一种用于描述可缺失值的类型。
在这种设计下,用户并不需要显式进行惰性求值,甚至他们都不需要了解惰性求值。类库自己会选择最优化的计算方式。
并行(Parallelism)
流水线既可以串行执行也可以并行执行,并行或串行是流的属性。除非你显式要求使用并行流,否则JDK总会返回串行流。(串行流可以通过 parallel() 方法被转化为并行流)
尽管并行是显式的,但它并不需要成为侵入式的。利用 parallelStream(),我们可以轻松的把之前重量求和的代码并行化:
|
1 2 3 4 5 |
int sum = shapes.parallelStream() .filter(s -> s.getColor = BLUE) .mapToInt(s -> s.getWeight()) .sum(); |
并行化之后和之前的代码区别并不大,然而我们可以很容易看出它是并行的(此外我们并不需要自己去实现并行代码)。
因为流的数据源可能是一个可变集合,如果在遍历流时数据源被修改,就会产生干扰(interference)。所以在进行流操作时,流的数据源应保持不变(held constant)。这个条件并不难维持,如果集合只属于当前线程,只要 lambda 表达式不修改流的数据源就可以。(这个条件和遍历集合时所需的条件相似,如果集合在遍历时被修改,绝大多数的集合实现都会抛出ConcurrentModificationException)我们把这个条件称为无干扰性(non-interference)。
我们应避免在传递给流方法的 lambda 产生副作用。一般来说,打印调试语句这种输出变量的操作是安全的,然而在 lambda 表达式里访问可变变量就有可能造成数据竞争或是其它意想不到的问题,因为 lambda 在执行时可能会同时运行在多个线程上,因而它们所看到的元素有可能和正常的顺序不一致。无干扰性有两层含义:
- 不要干扰数据源;
- 不要干扰其它 lambda 表达式,当一个 lambda 在修改某个可变状态而另一个 lambda 在读取该状态时就会产生这种干扰。
只要满足无干扰性,我们就可以安全的进行并行操作并得到可预测的结果,即便对线程不安全的集合(例如 ArrayList)也是一样。
实例(Examples)
下面的代码源自 JDK 中的 Class 类型(getEnclosingMethod 方法),这段代码会遍历所有声明的方法,然后根据方法名称、返回类型以及参数的数量和类型进行匹配:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
for (Method method : enclosingInfo.getEnclosingClass().getDeclaredMethods()) { if (method.getName().equals(enclosingInfo.getName())) { Class<?>[] candidateParamClasses = method.getParameterTypes(); if (candidateParamClasses.length == parameterClasses.length) { boolean matches = true; for (int i = 0; i < candidateParamClasses.length; i += 1) { if (!candidateParamClasses[i].equals(parameterClasses[i])) { matches = false; break; } } if (matches) { // finally, check return type if (method.getReturnType().equals(returnType)) { return method; } } } } } throw new InternalError("Enclosing method not found"); |
通过使用流,我们不但可以消除上面代码里面所有的临时变量,还可以把控制逻辑交给类库处理。通过反射得到方法列表之后,我们利用 Arrays.stream 将它转化为 Stream,然后利用一系列过滤器去除类型不符、参数不符以及返回值不符的方法,然后通过调用 findFirst 得到 Optional<Method>,最后利用 orElseThrow 返回目标值或者抛出异常。
|
1 2 3 4 5 6 |
return Arrays.stream(enclosingInfo.getEnclosingClass().getDeclaredMethods()) .filter(m -> Objects.equals(m.getName(), enclosingInfo.getName())) .filter(m -> Arrays.equals(m.getParameterTypes(), parameterClasses)) .filter(m -> Objects.equals(m.getReturnType(), returnType)) .findFirst() .orElseThrow(() -> new InternalError("Enclosing method not found")); |
相对于未使用流的代码,这段代码更加紧凑,可读性更好,也不容易出错。
流操作特别适合对集合进行查询操作。假设有一个“音乐库”应用,这个应用里每个库都有一个专辑列表,每张专辑都有其名称和音轨列表,每首音轨表都有名称、艺术家和评分。
假设我们需要得到一个按名字排序的专辑列表,专辑列表里面的每张专辑都至少包含一首四星及四星以上的音轨,为了构建这个专辑列表,我们可以这么写:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
List<Album> favs = new ArrayList<>(); for (Album album : albums) { boolean hasFavorite = false; for (Track track : album.tracks) { if (track.rating >= 4) { hasFavorite = true; break; } } if (hasFavorite) favs.add(album); } Collections.sort(favs, new Comparator<Album>() { public int compare(Album a1, Album a2) { return a1.name.compareTo(a2.name); } }); |
我们可以用流操作来完成上面代码中的三个主要步骤——识别一张专辑是否包含一首评分大于等于四星的音轨(使用 anyMatch);按名字排序;以及把满足条件的专辑放在一个 List 中:
|
1 2 3 4 5 |
List<Album> sortedFavs = albums.stream() .filter(a -> a.tracks.anyMatch(t -> (t.rating >= 4))) .sorted(Comparator.comparing(a -> a.name)) .collect(Collectors.toList()); |
Compartor.comparing 方法接收一个函数(该函数返回一个实现了 Comparable 接口的排序键值),然后返回一个利用该键值进行排序的 Comparator(请参考下面的 比较器工厂 一节)。
收集器(Collectors)
在之前的例子中,我们利用 collect() 方法把流中的元素聚合到 List 或 Set 中。collect() 接收一个类型为 Collector 的参数,这个参数决定了如何把流中的元素聚合到其它数据结构中。Collectors 类包含了大量常用收集器的工厂方法,toList() 和 toSet() 就是其中最常见的两个,除了它们还有很多收集器,用来对数据进行对复杂的转换。
Collector 的类型由其输入类型和输出类型决定。以 toList() 收集器为例,它的输入类型为 T,输出类型为 List<T>,toMap 是另外一个较为复杂的 Collector,它有若干个版本。最简单的版本接收一对函数作为输入,其中一个函数用来生成键(key),另一个函数用来生成值(value)。toMap 的输入类型是 T,输出类型是 Map<K, V>,其中 K 和 V 分别是前面两个函数所生成的键类型和值类型。(复杂版本的 toMap 收集器则允许你指定目标 Map 的类型或解决键冲突)。举例来说,下面的代码以目录数字为键值创建一个倒排索引:
|
1 2 3 |
Map<Integer, Album> albumsByCatalogNumber = albums.stream() .collect(Collectors.toMap(a -> a.getCatalogNumber(), a -> a)); |
groupingBy 是一个与 toMap 相类似的收集器,比如说我们想要把我们最喜欢的音乐按歌手列出来,这时我们就需要这样的 Collector:它以 Track 作为输入,以 Map<Artist, List<Track>>作为输出。groupingBy 收集器就可以胜任这个工作,它接收分类函数(classification function),然后根据这个函数生成 Map,该 Map 的键是分类函数的返回结果,值是该分类下的元素列表。
|
1 2 3 4 |
Map<Artist, List<Track>> favsByArtist = tracks.stream() .filter(t -> t.rating >= 4) .collect(Collectors.groupingBy(t -> t.artist)); |
收集器可以通过组合和复用来生成更加复杂的收集器,简单版本的 groupingBy 收集器把元素按照分类函数为每个元素计算出分类键值,然后把输入元素输出到对应的分类列表中。除了这个版本,还有一个更加通用(general)的版本允许你使用 其它 收集器来整理输入元素:它接收一个分类函数以及一个下流(downstream)收集器(单参数版本的 groupingBy 使用 toList() 作为其默认下流收集器)。举例来说,如果我们想把每首歌曲的演唱者收集到 Set 而非 List 中,我们可以使用 toSet 收集器:
|
1 2 3 4 5 |
Map<Artist, Set<Track>> favsByArtist = tracks.stream() .filter(t -> t.rating >= 4) .collect(Collectors.groupingBy(t -> t.artist, Collectors.toSet())); |
如果我们需要按照歌手和评分来管理歌曲,我们可以生成多级 Map:
|
1 2 3 4 |
Map<Artist, Map<Integer, List<Track>>> byArtistAndRating = tracks.stream() .collect(groupingBy(t -> t.artist, groupingBy(t -> t.rating))); |
在最后的例子里,我们创建了一个歌曲标题里面的词频分布。我们首先使用 Stream.flatMap() 得到一个歌曲流,然后用 Pattern.splitAsStream 把每首歌曲的标题打散成词流;接下来我们用 groupingBy 和 String.toUpperCase 对这些词进行不区分大小写的分组,最后使用 counting()收集器计算每个词出现的次数(从而无需创建中间集合)。
|
1 2 3 4 5 |
Pattern pattern = Pattern.compile("\s+"); Map<String, Integer> wordFreq = tracks.stream() .flatMap(t -> pattern.splitAsStream(t.name)) // Stream<String> .collect(groupingBy(s -> s.toUpperCase(), counting())); |
flatMap 接收一个返回流(这里是歌曲标题里的词)的函数。它利用这个函数将输入流中的每个元素转换为对应的流,然后把这些流拼接到一个流中。所以上面代码中的 flatMap 会返回所有歌曲标题里面的词,接下来我们不区分大小写的把这些词分组,并把词频作为值(value)储存。
Collectors 类包含大量的方法,这些方法被用来创造各式各样的收集器,以便进行查询、列表(tabulation)和分组等工作,当然你也可以实现一个自定义 Collector。
并行的实质(Parallelism under the hood)
Java SE 7 引入了 Fork/Join 模型,以便高效实现并行计算。不过,通过 Fork/Join 编写的并行代码和同功能的串行代码的差别非常巨大,这使改写串行代码变的非常困难。通过提供串行流和并行流,用户可以在串行操作和并行操作之间进行便捷的切换(无需重写代码),从而使得编写正确的并行代码变的更加容易。
为了实现并行计算,我们一般要把计算过程递归分解(recursive decompose)为若干步:
- 把问题分解为子问题;
- 串行解决子问题从而得到部分结果(partial result);
- 合并部分结果合为最终结果。
这也是 Fork/Join 的实现原理。
为了能够并行化任意流上的所有操作,我们把流抽象为 Spliterator,Spliterator 是对传统迭代器概念的一个泛化。分割迭代器(spliterator)既支持顺序依次访问数据,也支持分解数据:就像 Iterator 允许你跳过一个元素然后保留剩下的元素,Spliterator 允许你把输入元素的一部分(一般来说是一半)转移(carve off)到另一个新的 Spliterator 中,而剩下的数据则会被保存在原来的 Spliterator 里。(这两个分割迭代器还可以被进一步分解)除此之外,分割迭代器还可以提供源的元数据(比如元素的数量,如果已知的话)和其它一系列布尔值特征(比如说“元素是否被排序”这样的特征),Streams 框架可以利用这些数据来进行优化。
上面的分解方法也同样适用于其它数据结构,数据结构的作者只需要提供分解逻辑,然后就可以直接享用并行流操作带来的遍历。
大多数用户无需去实现 Spliterator 接口,因为集合上的 stream() 方法往往就足够了。但如果你需要实现一个集合或一个流,那么你可能需要手动实现 Spliterator 接口。Spliterator 接口的API如下所示:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public interface Spliterator<T> { // Element access boolean tryAdvance(Consumer< ? super T> action); void forEachRemaining(Consumer< ? super T> action); // Decomposition Spliterator<T> trySplit(); //Optional metadata long estimateSize(); int characteristics(); Comparator< ? super T> getComparator(); } |
集合库中的基础接口 Collection 和 Iterable 都实现了正确但相对低效的 spliterator() 实现,但派生接口(例如 Set)和具体实现类(例如 ArrayList)均提供了高效的分割迭代器实现。分割迭代器的实现质量会影响到流操作的执行效率;如果在 split() 方法中进行良好(平衡)的划分,CPU 的利用率会得到改善;此外,提供正确的特性(characteristics)和大小(size)这些元数据有利于进一步优化。
出现顺序(Encounter order)
多数数据结构(例如列表,数组和I/O通道)都拥有 自然出现顺序(natural encounter order),这意味着它们的元素出现顺序是可预测的。其它的数据结构(例如 HashSet)则没有一个明确定义的出现顺序(这也是 HashSet 的 Iterator 实现中不保证元素出现顺序的原因)。
是否具有明确定义的出现顺序是 Spliterator 检查的特性之一(这个特性也被流使用)。除了少数例外(比如 Stream.forEach() 和 Stream.findAny()),并行操作一般都会受到出现顺序的限制。这意味着下面的流水线:
|
1 2 3 4 |
List<String> names = people.parallelStream() .map(Person::getName) .collect(toList()); |
代码中名字出现的顺序必须要和流中的 Person 出现的顺序一致。一般来说,这是我们所期待的结果,而且它对多大多数的流实现都不会造成明显的性能损耗。从另外的角度来说,如果源数据是 HashSet,那么上面代码中名字就可以以任意顺序出现。
JDK 中的流和 lambda(Streams and lambdas in JDK)
Stream 在 Java SE 8 中非常重要,我们希望可以在 JDK 中尽可能广的使用 Stream。我们为 Collection 提供了 stream() 和 parallelStream(),以便把集合转化为流;此外数组可以通过 Arrays.stream() 被转化为流。
除此之外,Stream 中还有一些静态工厂方法(以及相关的原始类型流实现),这些方法被用来创建流,例如 Stream.of(),Stream.generate 以及 IntStream.range。其它的常用类型也提供了流相关的方法,例如 String.chars,BufferedReader.lines,Pattern.splitAsStream,Random.ints 和 BitSet.stream。
最后,我们提供了一系列API用于构建流,类库的编写者可以利用这些API来在流上实现其它聚集操作。实现 Stream 至少需要一个 Iterator,不过如果编写者还拥有其它元数据(例如数据大小),类库就可以通过 Spliterator 提供一个更加高效的实现(就像 JDK 中所有的集合一样)。
比较器工厂(Comparator factories)
我们在 Comparator 接口中新增了若干用于生成比较器的实用方法:
静态方法 Comparator.comparing() 接收一个函数(该函数返回一个实现 Comparable 接口的比较键值),返回一个 Comparator,它的实现十分简洁:
|
1 2 3 4 |
public static <T, U extends Comparable< ? super U>> Compartor<T> comparing( Function< ? super T, ? extends U> keyExtractor) { return (c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2)); } |
我们把这种方法称为 高阶函数 ——以函数作为参数或是返回值的函数。我们可以使用高阶函数简化代码:
|
1 2 |
List<Person> people = ... people.sort(comparing(p -> p.getLastName())); |
这段代码比“过去的代码”(一般要定义一个实现 Comparator 接口的匿名类)要简洁很多。但是它真正的威力在于它大大改进了可组合性(composability)。举例来说,Comparator 拥有一个用于逆序的默认方法。于是,如果想把列表按照姓进行反序排序,我们只需要创建一个和之前一样的比较器,然后调用反序方法即可:
|
1 |
people.sort(comparing(p -> p.getLastName()).reversed()); |
与之类似,默认方法 thenComparing 允许你去改进一个已有的 Comparator:在原比较器返回相等的结果时进行进一步比较。下面的代码演示了如何按照姓和名进行排序:
|
1 2 3 4 |
Comparator<Person> c = Comparator.comparing(p -> p.getLastName()) .thenComparing(p -> p.getFirstName()); people.sort(c); |
可变的集合操作(Mutative collection operation)
集合上的流操作一般会生成一个新的值或集合。不过有时我们希望就地修改集合,所以我们为集合(例如 Collection,List 和 Map)提供了一些新的方法,比如 Iterable.forEach(Consumer),Collection.removeAll(Predicate),List.replaceAll(UnaryOperator),List.sort(Comparator) 和 Map.computeIfAbsent()。除此之外,ConcurrentMap 中的一些非原子方法(例如 replace 和 putIfAbsent)被提升到 Map 之中。
小结(Summary)
引入 lambda 表达式是 Java 语言的巨大进步,但这还不够——开发者每天都要使用核心类库,为了开发者能够尽可能方便的使用语言的新特性,语言的演化和类库的演化是不可分割的。Stream 抽象作为新增类库特性的核心,提供了强大的数据集合操作功能,并被深入整合到现有的集合类和其它的 JDK 类型中。
转自:http://lucida.me/blog/java-8-lambdas-insideout-language-features/
============================================================================================
Java 8支持动态语言,看到了很酷的Lambda表达式,对一直以静态类型语言自居的Java,让人看到了Java虚拟机可以支持动态语言的目标。
刚看到这个表达式,感觉java的处理方式是属于内部匿名类的方式
public class Lambda {
static {
System.setProperty("jdk.internal.lambda.dumpProxyClasses", ".");
}
public static void main(String[] args) {
Consumer<String> c = new Consumer<String>(){
@Override
public void accept(String s) {
System.out.println(s);
}
};
c.accept("hello lambda");
}
}
编译的结果应该是Lambda.class , Lambda$1.class 猜测在支持动态语言java换汤不换药,在最后编译的时候生成我们常见的方式。
但是结果不是这样的,只是产生了一个Lambda.class
反编译吧,来看看真相是什么?
javap -v -p Lambda.class 注意 -p 这个参数 -p 参数会显示所有的方法,而不带默认是不会反编译private 的方法的
public Lambda();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #21 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 3: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this LLambda;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=1
0: invokedynamic #30, 0 // InvokeDynamic #0:accept:()Ljava/util/function/Consumer;
5: astore_1
6: aload_1
7: ldc #31 // String hello lambda
9: invokeinterface #33, 2 // InterfaceMethod java/util/function/Consumer.accept:(Ljava/lang/Object;)V
14: return
LineNumberTable:
line 8: 0
line 9: 6
line 10: 14
LocalVariableTable:
Start Length Slot Name Signature
0 15 0 args [Ljava/lang/String;
6 9 1 c Ljava/util/function/Consumer;
LocalVariableTypeTable:
Start Length Slot Name Signature
6 9 1 c Ljava/util/function/Consumer<Ljava/lang/String;>;
private static void lambda$0(java.lang.String);
descriptor: (Ljava/lang/String;)V
flags: ACC_PRIVATE, ACC_STATIC, ACC_SYNTHETIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #46 // Field java/lang/System.out:Ljava/io/PrintStream;
3: aload_0
4: invokevirtual #50 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
7: return
LineNumberTable:
line 8: 0
LocalVariableTable:
Start Length Slot Name Signature
0 8 0 s Ljava/lang/String;
}
SourceFile: "Lambda.java"
BootstrapMethods:
0: #66 invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;
Method arguments:
#67 (Ljava/lang/Object;)V
#70 invokestatic Lambda.lambda$0:(Ljava/lang/String;)V
#71 (Ljava/lang/String;)V
InnerClasses:
public static final #77= #73 of #75; //Lookup=class java/lang/invoke/MethodHandles$Lookup of class java/lang/invoke/MethodHandles
在这里我们发现了几个与我们常见的java不太一样的地方,由于常量定义太多了,文章中就不贴出了
1. Invokedynamic 指令
Java的调用函数的四大指令(invokevirtual、invokespecial、invokestatic、invokeinterface),通常方法的符号引用在静态类型语言编译时就能产生,而动态类型语言只有在运行期才能确定接收者类型,改变四大指令的语意对java的版本有很大的影响,所以在JSR 292 《Supporting Dynamically Typed Languages on the Java Platform》添加了一个新的指令
Invokedynamic
0: invokedynamic #30, 0 // InvokeDynamic #0:accept:()Ljava/util/function/Consumer;
#30 是代表常量#30 也就是后面的注释InvokeDynamic #0:accept:()Ljava/util/function/Consumer;
0 是占位符号,目前无用
2. BootstrapMethods
每一个invokedynamic指令的实例叫做一个动态调用点(dynamic call site), 动态调用点最开始是未链接状态(unlinked:表示还未指定该调用点要调用的方法), 动态调用点依靠引导方法来链接到具体的方法. 引导方法是由编译器生成, 在运行期当JVM第一次遇到invokedynamic指令时, 会调用引导方法来将invokedynamic指令所指定的名字(方法名,方法签名)和具体的执行代码(目标方法)链接起来, 引导方法的返回值永久的决定了调用点的行为.引导方法的返回值类型是java.lang.invoke.CallSite, 一个invokedynamic指令关联一个CallSite, 将所有的调用委托到CallSite当前的target(MethodHandle)
InvokeDynamic #0 就是BootstrapMethods表示#0的位置
0: #66 invokestatic java/lang/invoke/LambdaMetafactory.metafactory:(Ljava/lang/invoke/MethodHandles$Lookup;Ljava/lang/String;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodType;Ljava/lang/invoke/MethodHandle;Ljava/lang/invoke/MethodType;)Ljava/lang/invoke/CallSite;
Method arguments:
#67 (Ljava/lang/Object;)V
#70 invokestatic Lambda.lambda$0:(Ljava/lang/String;)V
#71 (Ljava/lang/String;)V
我们看到调用了LambdaMetaFactory.metafactory 的方法
参数:
LambdaMetafactory.metafactory(Lookup, String, MethodType, MethodType, MethodHandle, MethodType)有六个参数, 按顺序描述如下
1. MethodHandles.Lookup caller : 代表查找上下文与调用者的访问权限, 使用invokedynamic指令时, JVM会自动自动填充这个参数
2. String invokedName : 要实现的方法的名字, 使用invokedynamic时, JVM自动帮我们填充(填充内容来自常量池InvokeDynamic.NameAndType.Name), 在这里JVM为我们填充为 "apply", 即Consumer.accept方法名.
3. MethodType invokedType : 调用点期望的方法参数的类型和返回值的类型(方法signature). 使用invokedynamic指令时, JVM会自动自动填充这个参数(填充内容来自常量池InvokeDynamic.NameAndType.Type), 在这里参数为String, 返回值类型为Consumer, 表示这个调用点的目标方法的参数为String, 然后invokedynamic执行完后会返回一个即Consumer实例.
4. MethodType samMethodType : 函数对象将要实现的接口方法类型, 这里运行时, 值为 (Object)Object 即 Consumer.accept方法的类型(泛型信息被擦除).#67 (Ljava/lang/Object;)V
5. MethodHandle implMethod : 一个直接方法句柄(DirectMethodHandle), 描述在调用时将被执行的具体实现方法 (包含适当的参数适配, 返回类型适配, 和在调用参数前附加上捕获的参数), 在这里为 #70 invokestatic Lambda.lambda$0:(Ljava/lang/String;)V 方法的方法句柄.
6. MethodType instantiatedMethodType : 函数接口方法替换泛型为具体类型后的方法类型, 通常和 samMethodType 一样, 不同的情况为泛型:
比如函数接口方法定义为 void accept(T t) T为泛型标识, 这个时候方法类型为(Object)Void, 在编译时T已确定, 即T由String替换, 这时samMethodType就是 (Object)Void, 而instantiatedMethodType为(String)Void.
第4, 5, 6 三个参数来自class文件中的. 如上面引导方法字节码中Method arguments后面的三个参数就是将应用于4, 5, 6的参数.
Method arguments:
#67 (Ljava/lang/Object;)V
#70 invokestatic Lambda.lambda$0:(Ljava/lang/String;)V
#71 (Ljava/lang/String;)V我们来看metafactory 的方法里的实现代码
public static CallSite metafactory(MethodHandles.Lookup caller,
String invokedName,
MethodType invokedType,
MethodType samMethodType,
MethodHandle implMethod,
MethodType instantiatedMethodType)
throws LambdaConversionException {
AbstractValidatingLambdaMetafactory mf;
mf = new InnerClassLambdaMetafactory(caller, invokedType,
invokedName, samMethodType,
implMethod, instantiatedMethodType,
false, EMPTY_CLASS_ARRAY, EMPTY_MT_ARRAY);
mf.validateMetafactoryArgs();
return mf.buildCallSite();
}
在buildCallSite的函数中
CallSite buildCallSite() throws LambdaConversionException {
final Class<?> innerClass = spinInnerClass();函数spinInnerClass 构建了这个内部类,也就是生成了一个Lambda$$Lambda$1/716157500 这样的内部类,这个类是在运行的时候构建的,并不会保存在磁盘中,如果想看到这个构建的类,可以通过设置环境参数
System.setProperty("jdk.internal.lambda.dumpProxyClasses", ".");会在你指定的路径 . 当前运行路径上生成这个内部类
3.静态类
Java在编译表达式的时候会生成lambda$0静态私有类,在这个类里实现了表达式中的方法块 system.out.println(s);
private static void lambda$0(java.lang.String);
descriptor: (Ljava/lang/String;)V
flags: ACC_PRIVATE, ACC_STATIC, ACC_SYNTHETIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #46 // Field java/lang/System.out:Ljava/io/PrintStream;
3: aload_0
4: invokevirtual #50 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
7: return
LineNumberTable:
line 8: 0
LocalVariableTable:
Start Length Slot Name Signature
0 8 0 s Ljava/lang/String;
当然了在上一步通过设置的jdk.internal.lambda.dumpProxyClasses里生成的Lambda$$Lambda$1.class
public void accept(java.lang.Object);
descriptor: (Ljava/lang/Object;)V
flags: ACC_PUBLIC
Code:
stack=1, locals=2, args_size=2
0: aload_1
1: checkcast #15 // class java/lang/String
4: invokestatic #21 // Method Lambda.lambda$0:(Ljava/lang/String;)V
7: return
RuntimeVisibleAnnotations:
0: #13()调用了Lambda.lambda$0静态函数,也就是表达式中的函数块
总结
这样就完成的实现了Lambda表达式,使用invokedynamic指令,运行时调用LambdaMetafactory.metafactory动态的生成内部类,实现了接口,内部类里的调用方法块并不是动态生成的,只是在原class里已经编译生成了一个静态的方法,内部类只需要调用该静态方法
1.Lambda相关概念与特性
Lambda 表达式是一个匿名函数,源于数学λ演算。是闭包函数,但闭包并不一定是Lambda 函数。 它可以赋值给变量,作为函数参数,作为函数返回值。
2.在Java8中Lambda的语法
List<Integer> integers = Arrays.asList(2, 4, 6, 8);
//老的方式
for (Integer x : integers) {
System.out.println(x);
}
//1.8 非lambda
integers.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer x) {
System.out.print(x);
}
});
integers.forEach((x) -> System.out.println(x));
integers.forEach(x -> System.out.println(x));
//可以赘述其参数类型
integers.forEach((Integer x) -> System.out.println(x));
//多行实现
integers.forEach((x) -> {
x = x * 10;
System.out.println(x);
});
// 本地变量
integers.forEach((x) -> {
int y = x + 10;
System.out.println(y);
});
Lambda 表达式的生命周期(Java 8)
那么Java 8是如何处理和支持Lambda表达式的呢?
- 编译器在类中生成一个静态函数;
- 运行时调用该静态函数;(invokeStatic?)
x -> System.out.println(x);
编译为:
public static void generatedNameOfLambadaFunction(Integer x){
System.out.println(x)
}
举个简单的例子,代码例子如下:
public class LifeCycleExample {
public static void main(String[] args) {
List<Integer> integers = Arrays.asList(2, 4, 6, 8);
integers.forEach(x -> System.out.println(x));
}
}
先编译为字节码,然后用反汇编工具对class文件执行“javap -private”显示private可见性以上的主要的类和成员,
java8demo git:(master) javap -private target/classes/org/luyi/lambda/syntax/LifeCycleExample.class
Compiled from "LifeCycleExample.java"
public class org.luyi.lambda.syntax.LifeCycleExample {
public org.luyi.lambda.syntax.LifeCycleExample();
public static void main(java.lang.String[]);
private static void lambda$main$6(java.lang.Integer);
}
除了构造函数和 main 函数,多了一个对应 Lambda 表达式的私有静态方法,最后该方法会被调用执行。
但是如果编译后是“invokestatic”虚拟机命令,返回类型又是void,那么Lambda 表达式是什么类型呢?后面会继续说明,这里我们可以先看下实际的字节码,
39: invokedynamic #5, 0 // InvokeDynamic #0:accept:()Ljava/util/function/Consumer;
invokeDynamic( 从JDK7 开始提供的,为了支持动态类型语言在运行时才能确定接收者的类型的场景)方法调用,运行时首次解析,生成一个匿名内部类。可以dump内存看看到该类
由”java.lang.invoke.LambdaMetafactory”的静态方法生成
public static CallSite metafactory(MethodHandles.Lookup caller,
String invokedName,
MethodType invokedType,
MethodType samMethodType,
MethodHandle implMethod,
MethodType instantiatedMethodType)
那一个Lambda表达式是什么类型呢?primitve,Object?
许多语言有专门的函数(数据)类型,但是Java8 处于向前兼容,和避免类型复杂化等多种原因考虑没有引入新类型;
3.Functional Interface 函数式接口
Functional Interface是只提供一个方法的普通接口。
public interface Consumer<T> {
void accept(T t);
...
}
在 Java8 前,JDK 已经提供哪些函数式接口了,
@FunctionalInterface
public interface Runnable {
public abstract void run();
}
java.lang.Runnable,
java.lang.Comparable,
java.util.concurrent.Callable;
JDK8 又新增了哪些通用的?你知道他们各自的使用场景吗?
java.util.function.Consumer<T>,
java.util.function.Supplier<T>,
java.util.function.Predicate<T>,
java.util.function.Function<T,R>,
为什么需要函数式接口?
它表达了 Lambda 表达式的类型,函数式接口是方法签名(signature),lambda表达式是方法body,两者组成了一个整体。
可以将 Lambda 表达式赋值给函数接口的局部变量
Consumer<Integer> consumer=x -> System.out.println(x);
integers.forEach(consumer);
注解 @FuncationalInterface 推荐使用(考虑向前兼容又非必须),Java8 编译器会帮你保证;
lambda git:(master) javac Echo.java
syntax/Echo.java:6: error: Unexpected @FunctionalInterface annotation
@FunctionalInterface
^
Echo is not a functional interface
multiple non-overriding abstract methods found in interface Echo
1 error
所以lambda 表达式的类型是函数式接口类型,前面不是说lambda 是个静态函数,为啥能赋值给个函数式接口;
那么是不是lambda的实现是基于匿名内部类的形式?No(但本质来说可以说 YES);
4.变量捕捉(Capture 本地变量,静态类属性,实例属性)
List<Integer> integers = Arrays.asList(2, 4, 6, 8);
int var=1;
integers.forEach(x -> System.out.println(x+var));
会有编译异常吗?
实际上,如果JDK8前的编译器下的匿名内部类会编译不通过;
int var=0;
Runnable r=new Runnable() {
@Override
public void run() {
System.out.print(var+2);
}
};
javac 1.7.0_79
lambda git:(master) javac CaptureExample.java
CaptureExample.java:22: error: local variable var is accessed from within inner class; needs to be declared final
System.out.print(var+2);
^
但是使用 JDK8的编译器是通过的。声明final是个推荐的,但即使不声明,若实际效果是final也行。
如果我们尝试改变其值呢?
int var=1;
integers.forEach(x -> {
var++;
System.out.println(x+var);});
}
会得到编译异常,这和匿名内部类情况下约束是类似的,
lambda git:(master) javac CaptureExample.java
CaptureExample.java:15: error: local variables referenced from a lambda expression must be final or effectively final
var++;
^
Lambda如何处理捕捉到的变量的呢?反编译后,我们发现静态的lambda函数增加了一个对应类型的参数;
private static void lambda$main$6(int, java.lang.Integer);
关于Lambda 表达式内的this指针; 指向谁呢?
首先看先静态方法中使用this指针,
public static void main(String[] args) {
integers.forEach(x -> {
System.out.println(this.toString());
System.out.println(x);
});
integers.forEach(new Consumer<Integer>() {
@Override
public void accept(Integer integer) {
System.out.println(this.toString());
}
});
}
前者会有编译异常,
ThisPointerExample.java:15: error: non-static variable this cannot be referenced from a static context
System.out.println(this.toString());
而匿名内部类形式和以前JDK保持兼容,表示的是Consumer这个new的实例“org.luyi.lambda.ThisPointerExample$1@3cd1a2f1”。
现在讲整数遍历方法作为一个实例方法,然后再调用
public class ThisPointerExample {
public void doSth() {
List<Integer> integers = Arrays.asList(2, 4, 6, 8);
integers.forEach(x -> {
System.out.println(this.toString());
System.out.println(x);
});
}
public static void main(String[] args) {
new ThisPointerExample().doSth();
}
}
执行结果可以发现,Lambda 表达式内部的this指针是指向其 enclosing Class;
那么,Lambda 表达 与 匿名内部类的区别可以总结了下了:
- 后者可以有实例的属性变量(状态);
- 后者可以含有多个方法;
- 方法体内的this指针的指向;
5.方法引用
Lambda 虽然很方便构造个匿名功能函数,但是有些功能函数的实现已经存在,还要重新在写个Lambda或者去使用对应的方法? 方法引用提供了便捷的处理方式;
引用一个静态方法;
integers.forEach(x -> {
// old style
//System.out.println(String.valueOf(x));
Function<Integer, String> i2s = String::valueOf;
System.out.println(i2s.apply(x));
});
要求:被引用方法的签名需要与函数接口签名匹配;
引用一个构造函数;
// System.out.println(new Integer("11"));
Function<String,Integer> s2i=Integer::new;
System.out.println(s2i.apply("11"));
引用一个实例方法;
Consumer<Object> sysout = System.out::println;
sysout.accept("hello world");
6.默认方法(Default Method)
问题背景,接口进化演进的问题,修改任何一个接口,比如增加个接口方法,那么所有以前接口的实现都要做响应的调整,破坏了原有稳定。 比如JDK8希望在集合类型(List,Set…)中增加新遍历方法“forEach(Consumer<? super T> action)” =>默认方法。
public interface Iterable<T> {
Iterator<T> iterator();
default void forEach(Consumer<? super T> action) {
Objects.requireNonNull(action);
for (T t : this) {
action.accept(t);
}
}
default Spliterator<T> spliterator() {
return Spliterators.spliteratorUnknownSize(iterator(), 0);
}
静态方法,有实现并且能够被接口实现类所继承;
默认方法被继承
public interface Test {
default void doSth(){
System.out.println("hello");
}
}
public class DefaultMethodExample implements Test {
public static void main(String[] args) {
DefaultMethodExample impl = new DefaultMethodExample();
impl.doSth();//hello
}
}
覆写默认方法
public class DefaultMethodExample implements Test {
@Override
public void doSth() {
System.out.println("hi");
}
public static void main(String[] args) {
DefaultMethodExample impl = new DefaultMethodExample();
impl.doSth();//hi
}
}
多级继承覆盖
public interface Test2 extends Test {
@Override
default void doSth() {
System.out.println("hello2");
}
}
public class DefaultMethodExample implements Test2 {
public static void main(String[] args) {
DefaultMethodExample impl = new DefaultMethodExample();
impl.doSth();//hello2
}
}
冲突
public interface A {
default void doSth(){
System.out.println("a");
}
}
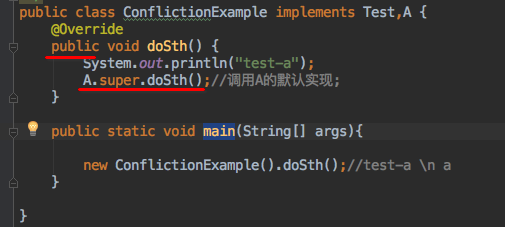
public class ConflictionExample implements Test,A {
}
接口A也提供了doSth的默认方法,如果一个实现类同时实现Test,A两个接口,那么编译器会报错误
Error:(6, 8) java: 类 org.luyi.lambda.defmtd.ConflictionExample从类型 org.luyi.lambda.defmtd.Test 和 org.luyi.lambda.defmtd.A 中继承了doSth() 的不相关默认值
解决冲突的方式是,实现类中重新覆写doSth方法,可以重新写实现,也可以使用任务一个父实现;