简介
Storm有4个调度器(defaultScheduler/IsolationScheduler/MultitenantScheduler/RAS),Jstorm只有一个调度器,但是其拥有4种模式(defaultScheduler/IsolationScheduler/User-defined Scheduler/The last Scheduler),JStorm的调度模式需要在用ConfigExtension进行配置。
根据官网介绍,storm内置了4种调度器
分别是: DefaultScheduler, IsolationScheduler, MultitenantScheduler, ResourceAwareScheduler.
下面分别进行介绍,
DefaultScheduler是storm默认调度器,默认时,topology内的组件将随机分配至已有资源上。
IsolationScheduler
IsolationScheduler为资源隔离调度器,这个调度器是为了使得topology对服务器节点进行独占。使得不同的topology发布时,占用不同的服务器资源,彼此形成物理隔离。
使用如下:
编辑nimbus所在服务器下的storm.yaml,添加如下配置:

表明,我发布名字为zc1的topology时,此拓扑将独占两台服务器,zc2的topology将独占一台服务器。
之前我一共配备了3台服务器作为从节点。发布后效果如下:


由图可见,虽然我的服务资源里还有worker资源,但是由于zc1,zc2已经独占了3台服务器,所以我的otherTopology无法分配到计算资源。
MultitenantScheduler
官网并没有对此调度器进行说明,只是留下了这个类在github上的位置,我们通过阅读此类的源码,也可以分析出此类的调度规则。



根据代码可知,这种调度模式会为每个topology发布者构造一个自己专属的隔离资源池,之后会通过遍历topology集,通过为资源池分配topology关联来分配节点。
验证:

由图可见,root分配第三个topology时,已经无法分配。(注:storm这个功能不太稳定,不建议使用)
Jstorm的default scheduler不仅仅像Storm那样实现了随机的资源分配,更考虑了稳定性,资源利用以及性能。
1.稳定性
均匀的将每个组件(spout/bolt)的线程(并行度)分配到集群中的各个节点。Jstorm会尽可能的将同一个组件的线程分配到不同的节点及worker上以减少同质竞争(同一个组件线程做的是一样的事情,比如可能都是cup密集型,那么放到不同节点就能提供效率,更好的利用资源)。
举个例子,一个集群有三个节点,node-A有3个worker,node-B有2个worker,node-C有一个worker。当用户提交一个topology(该topology需要4个worker,1个spout(X),一个bolt(Y),spout/bolt各占2个线程)。初始时:在Storm与Jstorm是一样的。
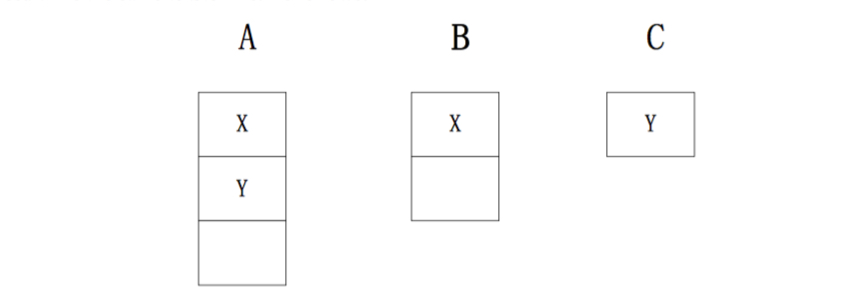
这时,如果node-C挂掉了,那么node-C中的worker必须要重写分配。如果是Storm的默认分配记过如下:
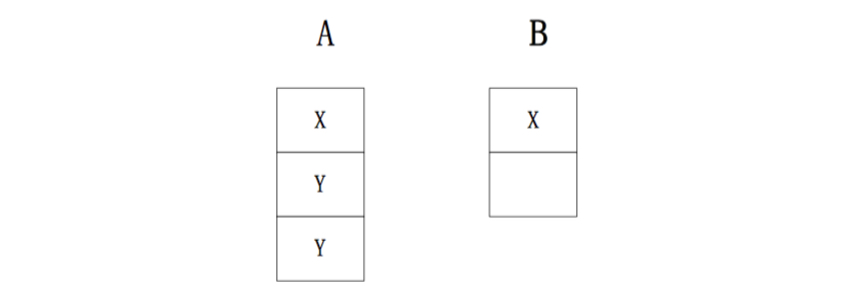
如果是Jstorm的默认调度来进行分配的化,结果如下:
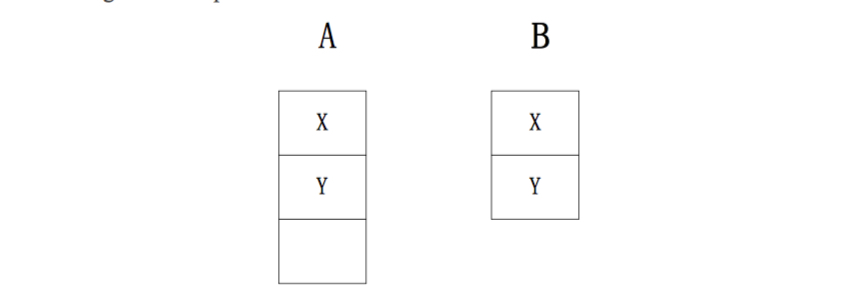
显然,JStorm的默认调度算法比Storm的更加优秀。
2.负载均衡
Jstorm尽量保证每个worker所分得的线程数基本一致,并且worker在各个supervisors之间也尽量分配的均匀。例如,一个集群有3个节点,node-A有3个worker,noder-B有3个woker,node-C与3个woker。用户先提交了一个需要2个woker的topology,然后,又提交了一个需要4个worker的topology。
如果是Storm的默认调度算法来分配这两个topology,结果如下:
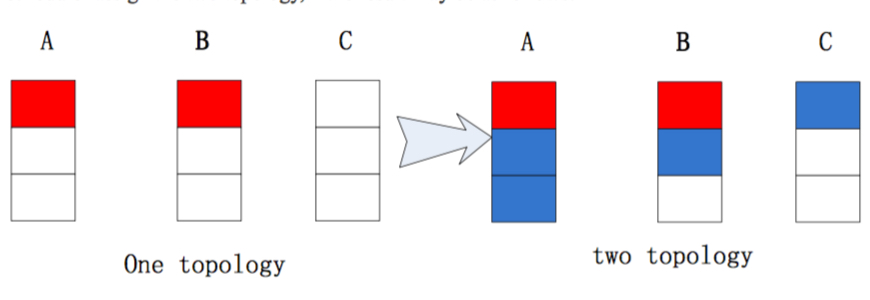
显然可以看出,这个分配是不均匀的。。而Jstorm的默认分配就能得到一个均匀的结果:
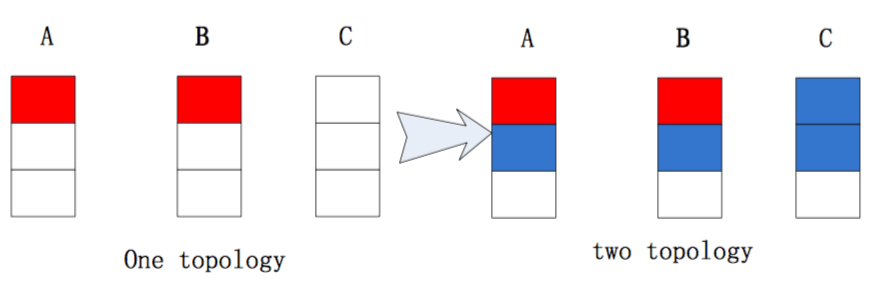
3.性能
Jstorm会试图将两个需要通讯的线程尽量放在一个worker中来减少网络的传输。例如:一个集群中有2个节点,node-A有2个worker,node-B有2个worker。当用户提交一个topology(需要2个worker,1个spout(X),2个bolt(Y、Z),三个组件各一个线程)。整个topology的数据流为X->Y->Z。如果Storm的默认调度算法来分配,可能的结果为:
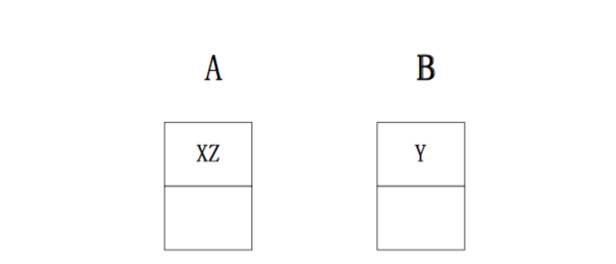
显然中间需要网络间传输,而JStorm的分配就能避免这个问题:
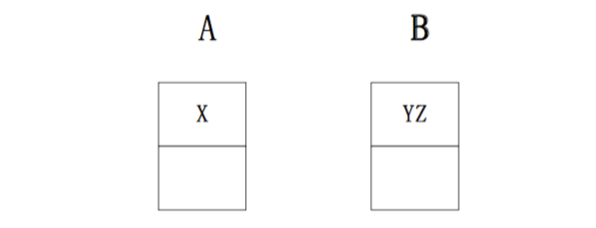
这里Y与Z的通讯是进程间通讯。在进程间通讯,消息不需要序列与反序列化。这样会极大的提高效率。
想要(稳定性/性能/平衡)都同时满足是很困难的。Jstorm对于重要性排序是:稳定性>性能>负债均衡。
高级特性
JStorm具有一些高级特性,我们可以通过配置topology来使用这些功能。
1.IsolationScheduler
与Storm一样,JStorm也有IsolationScheduler。在storm中用户可以配置Nimbus来隔离特定的topology,决定分配多少机器给这些隔离的topology,配置项为Nimbus上的storm.yaml文件中的isolation.scheduler.machines。在隔离的topology分配好之后,那些没有被隔离的就使用剩下的机器。由于Jstorm将IsolationScheduler整合进了DefaultScheduler中,所以,在Jstorm中,我们需要在topology中进行配置,而不是在storm.yaml中。
2.User-defined Assignment Scheduler
顾名思义,用户通过这个可以自己定义分配方式。下面来看看一些需要自己定义分配方式的场景:
a.将Spout与bolt放到一个worker中来达到替代DRPC的目的
spoutA->bolt1->bolt2->resultbolt
我们可以把spoutA与resultbolt放到一个woker中,这样resultbolt的结果就能直接返回给spoutA。
b.将上下游的组件放在一起,避免网络传输。
c.强制将一个组件运行分配到一个特定的机器上。
例如,我们可以将一个操作数据库的组件强制分配到数据库所在的机器上,或者,将需要读kafka数据的组件放到kafka所在的机器上。
d.强制一个组件的不同线程运行在不同的机器中。
当然,用户也可以选择只对部分worker与线程进行自定义分配,那么其他还是使用默认的分配方式。
3.The Last Assignment Scheduler
为什么会有这么个奇怪的分配方式呢,这个分配就是很简单的,与上一次用一样的分布方式。
假设,你上了一个topology,然后,过了一段时间,你re-submit/restart这个topology,这时,如果与上次的分配方式不一样,topology上一次运行在各个节点留下的数据就没用了,而如果采用与上一次一样的分配方式,那么这些数据就能够得到重用。
当然,如果出现一个节点挂了,那么这个节点的woker的重新分配就是默认的分配方式了。
一、任务调度策略
当我们将topology提交到storm集群的时候,任务是怎样分配的呢,这就需要理解storm的任务调度策略,这里主要给大家分享默认的调度策略DefaultScheduler,在storm的1.1.0版本已经支持4种调度策略,分别是DefaultScheduler,IsolationScheduler,MultitenantScheduler,ResourceAwareScheduler。
二、Topology的提交过程
在理解默认的调度策略之前,先看一下我们提交一个topology到集群的整个流程图。
主要分为几步:
1、非本地模式下,客户端通过thrift调用nimbus接口,来上传代码到nimbus并触发提交操作.
2、nimbus进行任务分配,并将信息同步到zookeeper.
3、supervisor定期获取任务分配信息,如果topology代码缺失,会从nimbus下载代码,并根据任务分配信息,同步worker.
4、worker根据分配的tasks信息,启动多个executor线程,同时实例化spout、bolt、acker等组件,此时,等待所有connections(worker和其它机器通讯的网络连接)启动完毕,storm集群即进入工作状态。
5、除非显示调用kill topology,否则spout、bolt等组件会一直运行。
下面我们来看一下整个topolgoy提交过程的源代码
Main方法里面的提交代码
StormSubmitter.submitTopology("one-work",config,builder.createTopology());然后调用下面方法
- public static void submitTopologyAs(String name, Map stormConf, StormTopology topology, SubmitOptions opts, ProgressListener progressListener, String asUser)
- throws AlreadyAliveException, InvalidTopologyException, AuthorizationException, IllegalArgumentException {
- //配置文件必须能够被Json序列化
- if(!Utils.isValidConf(stormConf)) {
- throw new IllegalArgumentException("Storm conf is not valid. Must be json-serializable");
- }
- stormConf = new HashMap(stormConf);
- //将命令行的参数加入stormConf
- stormConf.putAll(Utils.readCommandLineOpts());
- //先加载defaults.yaml, 然后再加载storm.yaml
- Map conf = Utils.readStormConfig();
- conf.putAll(stormConf);
- //设置zookeeper的相关权限
- stormConf.putAll(prepareZookeeperAuthentication(conf));
- validateConfs(conf, topology);
- Map<String,String> passedCreds = new HashMap<>();
- if (opts != null) {
- Credentials tmpCreds = opts.get_creds();
- if (tmpCreds != null) {
- passedCreds = tmpCreds.get_creds();
- }
- }
- Map<String,String> fullCreds = populateCredentials(conf, passedCreds);
- if (!fullCreds.isEmpty()) {
- if (opts == null) {
- opts = new SubmitOptions(TopologyInitialStatus.ACTIVE);
- }
- opts.set_creds(new Credentials(fullCreds));
- }
- try {
- //本地模式
- if(localNimbus!=null) {
- LOG.info("Submitting topology " + name + " in local mode");
- if(opts!=null) {
- localNimbus.submitTopologyWithOpts(name, stormConf, topology, opts);
- } else {
- // this is for backwards compatibility
- localNimbus.submitTopology(name, stormConf, topology);
- }
- LOG.info("Finished submitting topology: " + name);
- //这里重点分析将topology提交到集群模式
- } else {
- //将配置信息转为json字符串
- String serConf = JSONValue.toJSONString(stormConf);
- //校验集群中topology-name是否已经存在
- if(topologyNameExists(conf, name, asUser)) {
- throw new RuntimeException("Topology with name `" + name + "` already exists on cluster");
- }
- //将jar包上传至nimbus,这个时候topology还没有正在跑起来,只是将jar提交到了nimbus,等待后续的任务调度
- String jar = submitJarAs(conf, System.getProperty("storm.jar"), progressListener, asUser);
- try (
- //获取Nimbus client对象
- NimbusClient client = NimbusClient.getConfiguredClientAs(conf, asUser)){
- LOG.info("Submitting topology " + name + " in distributed mode with conf " + serConf);
- //调用submitTopologyWithOpts正式向nimbus提交拓扑,其实所谓的提交拓扑,就是将拓扑的配置信息通过thrift发送到thrift server,并把jar包上传到nimbus,等待nimbus的后续处//理,此时拓扑并未真正起来,直至recv_submitTopology获得成功的返回信息为止
- if (opts != null) {
- client.getClient().submitTopologyWithOpts(name, jar, serConf, topology, opts);
- } else {
- // this is for backwards compatibility
- client.getClient().submitTopology(name, jar, serConf, topology);
- }
- LOG.info("Finished submitting topology: " + name);
- } catch (InvalidTopologyException e) {
- LOG.warn("Topology submission exception: " + e.get_msg());
- throw e;
- } catch (AlreadyAliveException e) {
- LOG.warn("Topology already alive exception", e);
- throw e;
- }
- }
- } catch(TException e) {
- throw new RuntimeException(e);
- }
- invokeSubmitterHook(name, asUser, conf, topology);
- }
继续调用
- public static String submitJarAs(Map conf, String localJar, ProgressListener listener, String asUser) {
- if (localJar == null) {
- throw new RuntimeException("Must submit topologies using the 'storm' client script so that StormSubmitter knows which jar to upload.");
- }
- //如果获取了nimbus client
- try (NimbusClient client = NimbusClient.getConfiguredClientAs(conf, asUser)) {
- //获取topology-jar对应的存放地址
- String uploadLocation = client.getClient().beginFileUpload();
- LOG.info("Uploading topology jar " + localJar + " to assigned location: " + uploadLocation);
- BufferFileInputStream is = new BufferFileInputStream(localJar, THRIFT_CHUNK_SIZE_BYTES);
- long totalSize = new File(localJar).length();
- if (listener != null) {
- listener.onStart(localJar, uploadLocation, totalSize);
- }
- long bytesUploaded = 0;
- while(true) {
- byte[] toSubmit = is.read();
- bytesUploaded += toSubmit.length;
- if (listener != null) {
- listener.onProgress(localJar, uploadLocation, bytesUploaded, totalSize);
- }
- if(toSubmit.length==0) break;
- //一块一块的提交jar
- client.getClient().uploadChunk(uploadLocation, ByteBuffer.wrap(toSubmit));
- }
- //完成jar包提交
- client.getClient().finishFileUpload(uploadLocation);
- if (listener != null) {
- listener.onCompleted(localJar, uploadLocation, totalSize);
- }
- LOG.info("Successfully uploaded topology jar to assigned location: " + uploadLocation);
- //返回存放jar的位置
- return uploadLocation;
- } catch(Exception e) {
- throw new RuntimeException(e);
- }
- }
- public void submitTopology(String name, String uploadedJarLocation, String jsonConf, StormTopology topology) throws AlreadyAliveException, InvalidTopologyException, AuthorizationException, org.apache.thrift.TException
- {
- //发送topology相关信息到nimbus
- send_submitTopology(name, uploadedJarLocation, jsonConf, topology);
- //接收返回结果
- recv_submitTopology();
- }
- public void send_submitTopology(String name, String uploadedJarLocation, String jsonConf, StormTopology topology) throws org.apache.thrift.TException{
- submitTopology_args args = new submitTopology_args();
- args.set_name(name);
- args.set_uploadedJarLocation(uploadedJarLocation);
- args.set_jsonConf(jsonConf);
- args.set_topology(topology);
- sendBase("submitTopology", args);
- }
- public void recv_submitTopology() throws AlreadyAliveException, InvalidTopologyException, AuthorizationException, org.apache.thrift.TException
- {
- submitTopology_result result = new submitTopology_result();
- receiveBase(result, "submitTopology");
- if (result.e != null) {
- throw result.e;
- }
- if (result.ite != null) {
- throw result.ite;
- }
- if (result.aze != null) {
- throw result.aze;
- }
- return;
- }
三、任务分配
在上面我们已经将topology提交到到nimbus了,下一步就是任务分配,strom默认4种分配策略。
DefaultScheduler策略,DefaultScheduler其实主要有几步
1、首先是获取当前集群中需要进行任务分配的topology
2、获取整个集群可用的slot
3、获取当前topology需要分配的executor信息
4、计算当前集群可释放的slot
5、统计可释放的solt和空闲的solt
6、执行topology分配
下面我们用一个列子来说明
比如初始状态下,集群的状态如下:2个supervisor,每个supervisor有4个可用的端口,这里我已A,B分别代表2个supervisor,那么初始情况下整个集群可用的端口地址就是:
A-6700,A-6701,A-6703,A-6704,B-6700,B-6701,B6702,B-6703。
Step1:现在我提交一个topology到集群,这个拓扑我给他分配2个worker端口,6个executor线程,每个线程默认运行一个任务就是6个task。当我们提交这个拓扑的时候,首先集群会将可用的solts进行排序如上可用端口的顺序,然后计算线程和任务的对应关系,这里都是6个,格式为[start-task-id end-task-id]就[1,1][2,2][3,3],[4,4],[5,5],[6,6]然后分配到2个worker上,那么每个worker分别跑3个线程即分配状态为[3,3]。
综上:分配的结果为:
[1,1],[2,2],[3,3] --->worker1
[4,4],[5,5],[6,6] --->worker2
而非常重要的是storm为了合理利用资源,在将可用slots排序后,依次选择worker来运行任务,也就是worker1对应A--6700,worker2对应B--6700。
下面我们来看一下storm集群的日志文件
首先提交topology
然后看一下nimbus.log日志
- 2017-04-09 22:00:12.502 o.a.s.d.common [INFO] Started statistics report plugin...
- 2017-04-09 22:00:12.575 o.a.s.d.nimbus [INFO] Starting nimbus server for storm version '1.0.0'
- 2017-04-09 22:03:13.661 o.a.s.d.nimbus [INFO] Uploading file from client to /bigdata/storm/datas/nimbus/inbox/stormjar-f16a2908-869a-418d-a589-ff6c7968724f.jar
- 2017-04-09 22:03:16.163 o.a.s.d.nimbus [INFO] Finished uploading file from client: /bigdata/storm/datas/nimbus/inbox/stormjar-f16a2908-869a-418d-a589-ff6c7968724f.jar
- 2017-04-09 22:03:16.328 o.a.s.d.nimbus [INFO] Received topology submission for testTopologySubmit with conf {"topology.max.task.parallelism" nil, "topology.submitter.principal" "", "topology.acker.executors" nil, "topology.eventlogger.executors" 0, "topology.workers" 2, "topology.debug" false, "storm.zookeeper.superACL" nil, "topology.users" (), "topology.submitter.user" "root", "topology.kryo.register" nil, "topology.kryo.decorators" (), "storm.id" "testTopologySubmit-1-1491800596", "topology.name" "testTopologySubmit"}
- 2017-04-09 22:03:16.335 o.a.s.d.nimbus [INFO] uploadedJar /bigdata/storm/datas/nimbus/inbox/stormjar-f16a2908-869a-418d-a589-ff6c7968724f.jar
获取集群可用的solts:

可以看到分配到了slave1和slave2的6700端口
slave1--132机器

slave2-134机器

Step2:现在整个集群还有A-6701,A-6702,A-6703,B-6701,B-6702,B-6703,现在假如我要提交一个新的topology,然后只有1个worker,那么它会分配到A-6701,那么如果后面每次都提交只需要一个worker的topology,那么会导致A机器端口已经被分配完了,而B机器还有3个可用的端口,所有storm的任务调度也不是很公平的,A机器已经满载了,B机器还有3个可用端口。