antlr4
安装
- 安装Java 1.7及以上
- 下载
$ cd /usr/local/lib $ curl -O https://www.antlr.org/download/antlr-4.9-complete.jar
- 添加 antlr-4.9-complete.jar 到CLASSPATH:
- 创建ANTLR Tool, 和 TestRig的别名
$ alias antlr4='java -Xmx500M -cp "/usr/local/lib/antlr-4.9-complete.jar:$CLASSPATH" org.antlr.v4.Tool' $ alias grun='java -Xmx500M -cp "/usr/local/lib/antlr-4.9-complete.jar:$CLASSPATH" org.antlr.v4.gui.TestRig'
使用
运行一下
$ grun Expr prog -tree -gui (Now enter something like the string below) a = 1; b = a + 1; b; (now,do:) ^D
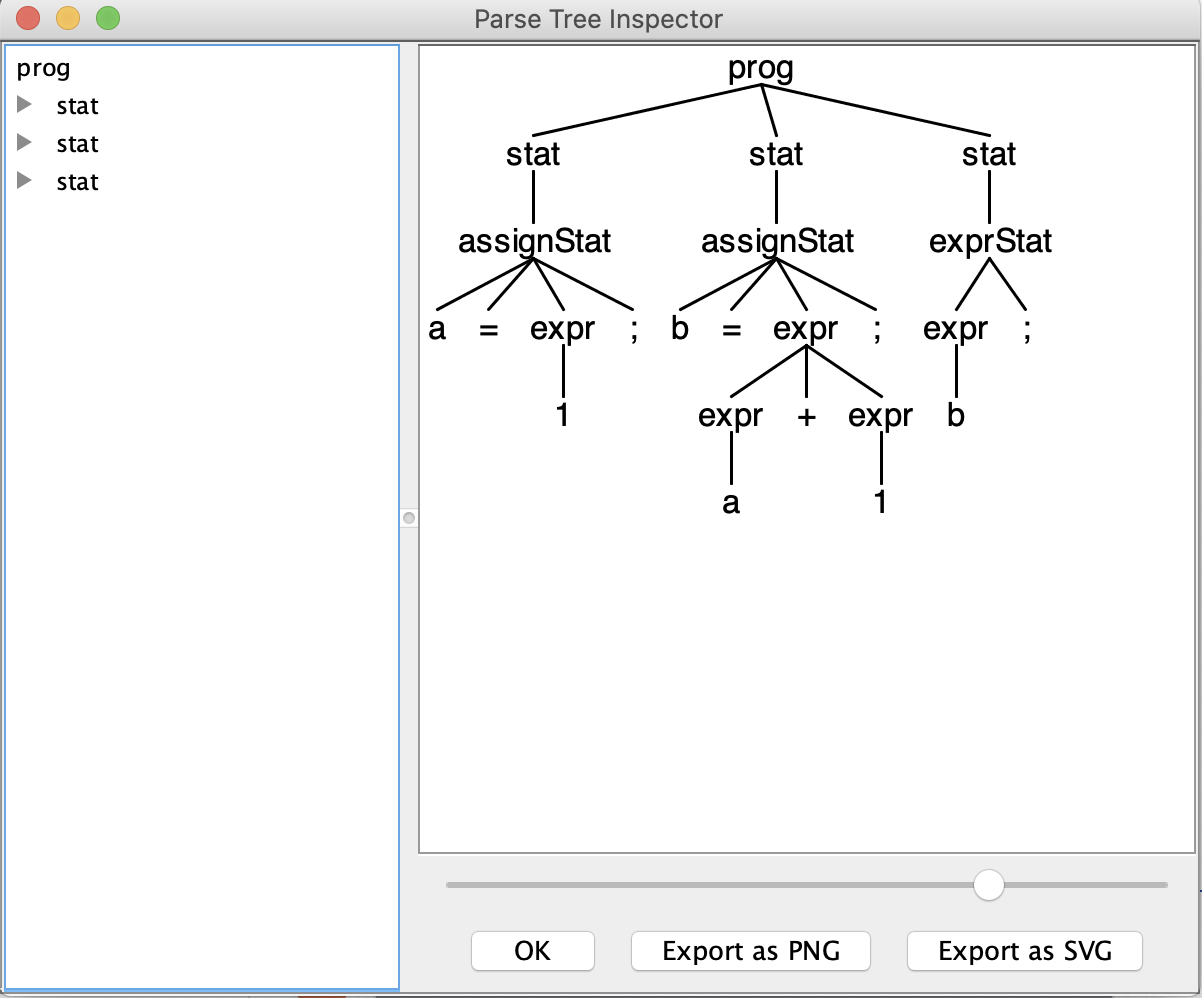
- 使用 ANTLR 4 生成目标编程语言代码的词法分析器(Lexer)和语法分析器(Parser),支持的编程语言有:Java、JavaScript、Python、C 和 C++ 等;
- 遍历 AST(Abstract Syntax Tree 抽象语法树),ANTLR 4 支持两种模式:访问者模式(Visitor)和监听器模式(Listener)
遍历模式
- Listener (观察者模式,通过结点监听,触发处理方法)
1) Listener模式会由ANTLR提供的walker对象自动调用;在遇到不同的节点中,会调用提供的listener的不同方法
2)Listener模式没有返回值,只能用一些变量来存储中间值
3)Listener模式是对整棵树的遍历
- Visitor (访问者模式,主动遍历)
1)visitor需要自己来指定访问特定类型的节点,在使用过程中,只需要对感兴趣的节点实现visit方法即可
2)visitor模式可以自定义返回值
3)visitor模式是对指定节点的访问
使用antlr4默认生成的是listener模式的解析器,如果要生成visitor类型的,需要加-vistor参数
在js中的使用
import antlr4 from 'antlr4'; import Lexer from './ExprLexer.js'); import Parser from './ExprParser.js';
import Listener from './ExprListener.js';
const input = `
a = 1; b = a + 1; b;
` const chars = new antlr4.InputStream(input); const lexer = new Lexer(chars);
const tokens = new antlr4.CommonTokenStream(lexer); const parser = new Parser(tokens);
使用Visitor来访问语法树
为了实现上述的解释过程,我们需要区遍历访问解析器解析出来的语法树,ANTLR提供了两种机制来访问生成的语法树:Listener和Visitor,使用Listener模式来访问语法树时,ANTLR内部的ParserTreeWalker在遍历语法树的节点过程中,在遇到不同的节点中,会调用提供的listener的不同方法;而使用Visitor模式时,visitor需要自己来指定如果访问特定类型的节点,ANTLR生成的解析器源码中包含了默认的Visitor基类/接口ExprVisitor.ts,在使用过程中,只需要对感兴趣的节点实现visit方法即可,比如我们需要访问到exprStat节点,只需要实现如下接口:
export interface ExprVisitor<Result> extends ParseTreeVisitor<Result> { ... /** * Visit a parse tree produced by `ExprParser.exprStat`. * @param ctx the parse tree * @return the visitor result */ visitExprStat?: (ctx: ExprStatContext) => Result; ... }
介绍完了如果使用Visitor来访问语法树中的节点后,我们来实现Expr解释器需要的Visitor:ExprEvalVisitor。
上面提到在访问语法树过程中,我们需要记录遇到的变量和其值、和最后的打印结果,我们使用Visitor内部变量来保存这些中间值:
class ExprEvalVisitor extends AbstractParseTreeVisitor<number> implements ExprVisitor<number> { // 保存执行输出结果 private buffers: string[] = []; // 保存变量 private memory: { [id: string]: number } = {}; }
我们需要访问语法树中的哪些节点呢?首先,为了最后的结果,对表达式语句exprState的访问是最重要的,我们访问表达式语句中的表达式得到表达式的值,并将值打印到执行结果中。由于表达式语句是由表达式加分号组成,我们需要继续访问表达式得到这条语句的值,而对于分号,则忽略:
class ExprEvalVisitor extends AbstractParseTreeVisitor<number> implements ExprVisitor<number> { // 保存执行输出结果 private buffers: string[] = []; // 保存变量 private memory: { [id: string]: number } = {}; // 访问表达式语句 visitExprStat(ctx: ExprStatContext) { const val = this.visit(ctx.expr()); this.buffers.push(`${val}`); return val; } }
上面递归的访问了表达式语句中的表达式节点,那表达式阶段的访问方法是怎样的?回到我们的语法定义Expr.g4,表达式是由5条分支组成的,对于不同的分支,处理方法不一样,因此我们对不同的分支使用不同的访问方法。我们在不同的分支后面添加了不同的注释,这些注释生成的解析器中,可以用来区分不同类型的节点,在生成的Visitor中,由可以看到不同的接口:
export interface ExprVisitor<Result> extends ParseTreeVisitor<Result> { ... /** * Visit a parse tree produced by the `MulDivExpr` * labeled alternative in `ExprParser.expr`. * @param ctx the parse tree * @return the visitor result */ visitMulDivExpr?: (ctx: MulDivExprContext) => Result; /** * Visit a parse tree produced by the `IdExpr` * labeled alternative in `ExprParser.expr`. * @param ctx the parse tree * @return the visitor result */ visitIdExpr?: (ctx: IdExprContext) => Result; /** * Visit a parse tree produced by the `IntExpr` * labeled alternative in `ExprParser.expr`. * @param ctx the parse tree * @return the visitor result */ visitIntExpr?: (ctx: IntExprContext) => Result; /** * Visit a parse tree produced by the `ParenExpr` * labeled alternative in `ExprParser.expr`. * @param ctx the parse tree * @return the visitor result */ visitParenExpr?: (ctx: ParenExprContext) => Result; /** * Visit a parse tree produced by the `AddSubExpr` * labeled alternative in `ExprParser.expr`. * @param ctx the parse tree * @return the visitor result */ visitAddSubExpr?: (ctx: AddSubExprContext) => Result; ... }
所以,在我们的ExprEvalVisitor中,我们通过实现不同的接口来访问不同的表达式分支,对于AddSubExpr分支,实现的访问方法如下:
visitAddSubExpr(ctx: AddSubExprContext) { const left = this.visit(ctx.expr(0)); const right = this.visit(ctx.expr(1)); const op = ctx._op; if (op.type === ExprParser.ADD) { return left + right; } return left - right; }
对于MulDivExpr,访问方法相同。对于IntExpr分支,由于其子节点只有INT节点,我们只需要解析出其中的整数即可:
visitIntExpr(ctx: IntExprContext) { return parseInt(ctx.INT().text, 10); }
对于IdExpr分支,其子节点只有变量ID,这个时候就需要在我们的保存的变量中去查找这个变量,并取出它的值:
visitIdExpr(ctx: IdExprContext) { const id = ctx.ID().text; if (this.memory[id] !== undefined) { return this.memory[id]; } return 0; }
对于最后一个分支ParenExpr,它的访问方法很简单,只需要访问到括号内的表达式即可:
visitParenExpr(ctx: ParenExprContext) { return this.visit(ctx.expr()); }
到这里,你可以发现了,我们上述的访问方法加起来,我们只有从memory读取变量的过程,没有想memory写入变量的过程,这就需要我们访问赋值表达式assignExpr节点了:对于赋值表达式,需要识别出等号左边的变量名,和等号右边的表达式,最后将变量名和右边表达式的值保存到memory中:
visitAssignStat(ctx: AssignStatContext) { const id = ctx.ID().text; const val = this.visit(ctx.expr()); this.memory[id] = val; return val; }
解释执行Expr语言
至此,我们的VisitorExprEvalVisitor已经准备好了,我们只需要在对指定的输入代码,使用visitor来访问解析出来的语法树,就可以实现Expr代码的解释执行了:
// Expr代码解释执行函数 // 输入code // 返回执行结果 function execute(code: string): string { const input = new ANTLRInputStream(code); const lexer = new ExprLexer(input); const tokens = new CommonTokenStream(lexer); const parser = new ExprParser(tokens); const visitor = new ExprEvalVisitor(); const prog = parser.prog(); visitor.visit(prog); return visitor.print(); }
六、Expr代码前缀表达式翻译器
通过前面的介绍,我们已经通过通过ANTLR来解释执行Expr代码了。结合ANTLR的介绍:ANTLR是用来读取、处理、执行和翻译结构化的文本。那我们能不能用ANTLR来翻译输入的Expr代码呢?在Expr语言中,表达式是我们常见的中缀表达式,我们能将它们翻译成前缀表达式吗?还记得数据结构课程中如果利用出栈、入栈将中缀表达式转换成前缀表达式的吗?不记得么关系,利用ANTLR生成的解析器,我们也可以简单的换成转换。
举例,对如下Expr代码:
a = 2; b = 3; c = a * (b + 2); c;
我们转换之后的结果如下,我们支队表达式做转换,而对赋值表达式则不做抓换,即代码中出现的表达式都会转换成:
a = 2; b = 3; c = * a + b 2; c;
前缀翻译Visitor
同样,这里我们使用Visitor模式来访问语法树,这次,我们直接visit根节点prog,并返回翻译后的代码:
class ExprTranVisitor extends AbstractParseTreeVisitor<string> implements ExprVisitor<string> { defaultResult() { return ''; } visitProg(ctx: ProgContext) { let val = ''; for (let i = 0; i < ctx.childCount; i++) { val += this.visit(ctx.stat(i)); } return val; } ... }
这里假设我们的visitor在visitor语句stat的时候,已经返回了翻译的代码,所以visitProg只用简单的拼接每条语句翻译后的代码即可。对于语句,前面提到了,语句我们不做翻译,所以它们的visit访问也很简单:对于表达式语句,直接打印翻译后的表达式,并加上分号;对于赋值语句,则只需将等号右边的表达式翻译即可:
visitExprStat(ctx: ExprStatContext) { const val = this.visit(ctx.expr()); return `${val}; `; } visitAssignStat(ctx: AssignStatContext) { const id = ctx.ID().text; const val = this.visit(ctx.expr()); return `${id} = ${val}; `; }
下面看具体如何翻译各种表达式。对于AddSubExpr和MulDivExpr的翻译,是整个翻译器的逻辑,即将操作符前置:
visitAddSubExpr(ctx: AddSubExprContext) { const left = this.visit(ctx.expr(0)); const right = this.visit(ctx.expr(1)); const op = ctx._op; if (op.type === ExprParser.ADD) { return `+ ${left} ${right}`; } return `- ${left} ${right}`; } visitMulDivExpr(ctx: MulDivExprContext) { const left = this.visit(ctx.expr(0)); const right = this.visit(ctx.expr(1)); const op = ctx._op; if (op.type === ExprParser.MUL) { return `* ${left} ${right}`; } return `/ ${left} ${right}`; }
由于括号在前缀表达式中是不必须的,所以的ParenExpr的访问,只需要去处括号即可:
visitParenExpr(ctx: ParenExprContext) { const val = this.visit(ctx.expr()); return val; }
对于其他的节点,不需要更多的处理,只需要返回节点对应的标记的文本即可:
visitIdExpr(ctx: IdExprContext) { const parent = ctx.parent; const id = ctx.ID().text; return id; } visitIntExpr(ctx: IntExprContext) { const parent = ctx.parent; const val = ctx.INT().text; return val; }
执行代码的前缀翻译
至此,我们代码前缀翻译的Visitor就准备好了,同样,执行过程也很简单,对输入的代码,解析生成得到语法树,使用ExprTranVisitor反问prog根节点,即可返回翻译后的代码:
function execute(code: string): string { const input = new ANTLRInputStream(code); const lexer = new ExprLexer(input); const tokens = new CommonTokenStream(lexer); const parser = new ExprParser(tokens); const visitor = new ExprTranVisitor(); const prog = parser.prog(); const result = visitor.visit(prog); return result; }
对输入代码:
A * B + C / D ; A * (B + C) / D ; A * (B + C / D) ; (5 - 6) * 7 ;
执行输出为:
+ * A B / C D; / * A + B C D; * A + B / C D; * - 5 6 7;
tree-sitter
- 足以解析任何编程语言
- 速度足以解析文本编辑器中的每一次击键
- 足够健壮,即使出现语法错误也能提供有用的结果
- 无依赖性,这样运行时库(用纯C编写)就可以嵌入到任何应用程序中
使用
npm install tree-sitter npm install tree-sitter-javascript const Parser = require('tree-sitter');const JavaScript = require('tree-sitter-javascript');const parser = new Parser();parser.setLanguage(JavaScript); const sourceCode = 'let x = 1; console.log(x);';const tree = parser.parse(sourceCode); console.log(tree.rootNode.toString()); // (program // (lexical_declaration // (variable_declarator (identifier) (number))) // (expression_statement // (call_expression // (member_expression (identifier) (property_identifier)) // (arguments (identifier))))) const callExpression = tree.rootNode.child(1).firstChild; console.log(callExpression); // { type: 'call_expression', // startPosition: {row: 0, column: 16}, // endPosition: {row: 0, column: 30}, // startIndex: 0, // endIndex: 30 }
参考

喜欢这篇文章?欢迎打赏~~
