urllib是一个包,这个包收集了几个用于处理URLs的模块
urllib.request 用于打开和读取URLs urllib.error 用于触发请求的异常 urllib.parse 用于分析URLs urllib.robotparser 用于分析robots.txt格式的文件
URLOPEN练习


import urllib.request response = urllib.request.urlopen("http://www.baidu.com") print(response.read().decode("utf-8"))
import urllib.request import urllib.parse data = bytes(urllib.parse.urlencode({"word":"hello"}),encoding="utf8") response = urllib.request.urlopen("http://httpbin.org/post",data=data) print(response.read())
import urllib.request response = urllib.request.urlopen("http://httpbin.org/get",timeout=1) print(response.read())
import socket import urllib.request import urllib.error try: response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.1) except urllib.error.URLError as e: if isinstance(e.reason,socket.timeout): print("TIME OUT")
响应练习
import urllib.request response = urllib.request.urlopen("https://www.python.org") print(type(response))
import urllib.request response = urllib.request.urlopen("https://www.python.org") print(response.status) print(response.getheaders()) print(response.getheader("Server"))
import urllib.request request = urllib.request.Request("https://www.python.org") response = urllib.request.urlopen(request) print(response.read().decode("utf-8"))
请求练习
import urllib.request request = urllib.request.Request("https://python.org") response = urllib.request.urlopen(request) print(response.read().decode("utf-8"))
from urllib import request,parse url = "http://httpbin.org/post" headers = { "User-Agent":"Mozilla/4.0(compatible;MSIE 5.5;Windows NT)", "Host":"httpbin.org" } dict = { "name":"Germey" } data = bytes(parse.urlencode(dict),encoding="utf8") req = request.Request(url=url,data=data,headers=headers,method="POST") response = request.urlopen(req) print(response.read().decode("utf-8"))
from urllib import request,parse url = "http://httpbin.org/post" dict = { "name":"Germey" } data = bytes(parse.urlencode(dict),encoding="utf8") req = request.Request(url=url,data=data,method="POST") req.add_header("User-Agent","Mozilla/4.0(compatible;MSIE 5.5;Windows NT)") response = request.urlopen(req) print(response.read().decode("utf-8"))
代理HANDLER
import urllib.request proxy_handler = urllib.request.ProxyHandler({ "http":"http://127.0.0.1:9743", "https":"https://127.0.0.1:9743" }) opener = urllib.request.build_opener(proxy_handler) response = opener.open("http://www.douyu.com") print(response.read())
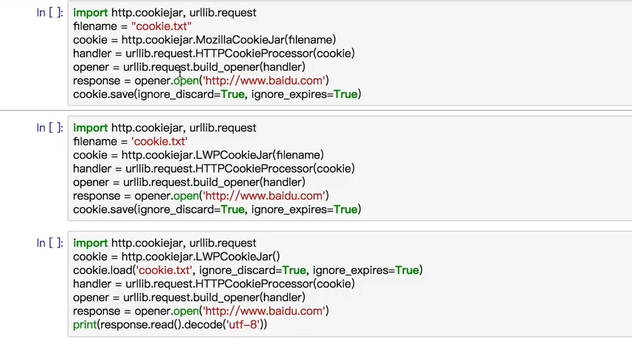
cookie
import http.cookiejar,urllib.request cookie = http.cookiejar.CookieJar() handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open("http://www.baidu.com") for item in cookie: print(item.name+"="+item.value)
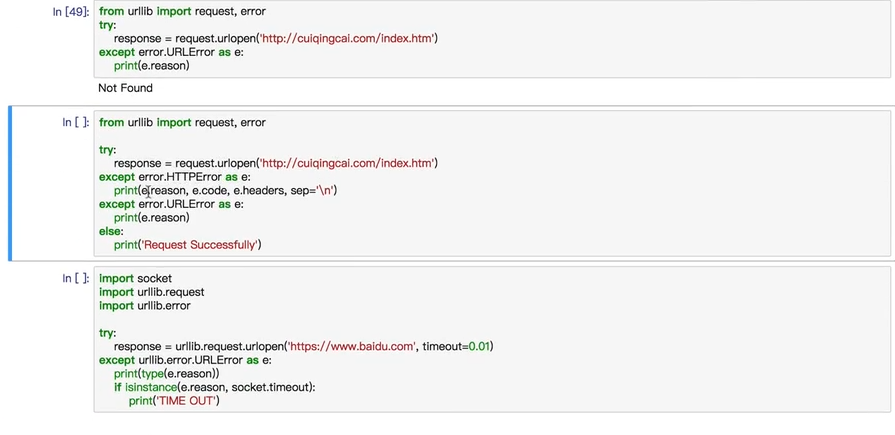
异常处理
from urllib import request,error try: response = request.urlopen("http://chuiqingcai.com/index.htm") except error.URLError as e: print(e.reason)
URL解析
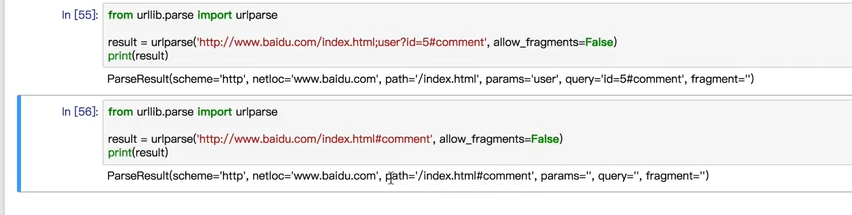
1.URlPARSE
urllib.parse.urlparse(urlstring,scheme="",allow_fragments=True)
from urllib.parse import urlparse result = urlparse("http://www.baidu.com/index.html;user?id=5#comment") print(type(result),result)
from urllib.parse import urlparse result = urlparse("www.baidu.com/index.html;user?id=5#comment",scheme="https") print(result)
2.URLUNPARSE
from urllib.parse import urlunparse data = ["http","www.baidu.com","index.html","user","a=6","comment"] print(urlunparse(data))
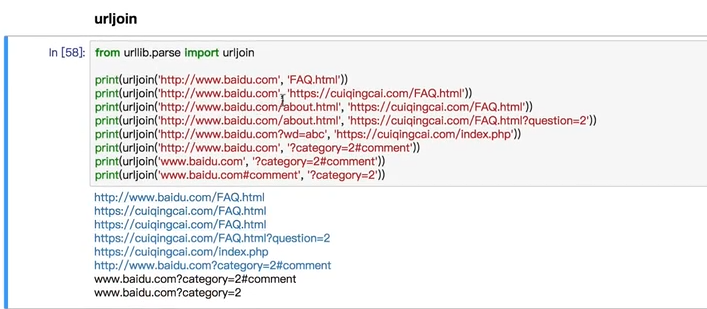
3.URLJOIN
4.URLENCODE
