一 、数据备份介绍
1.1 为何要备份
在生产环境中我们数据库可能会遭遇各种各样的不测从而导 致数据丢失, 大概分为以下几种.
-
硬件故障
-
软件故障
-
自然灾害
-
黑客攻击
-
误操作 (占比最大)
须知在生产环境中,服务器的硬件坏了可以维修或者换新, 软件崩溃可以修复或重新安装, 但是如果数据没了那可就毁 了,生产环境中最重要的应该就是数据了。所以, 为了在数 据丢失之后能够恢复数据, 我们就需要定期的备份数据。
1.2 备份什么
我们要备份什么?
-
数据
-
二进制日志, InnoDB事务日志
-
代码(存储过程、存储函数、触发器、事件调度器)
-
服务器配置文件
1.3 备份的类型
1)冷备、温备、热备
按照备份时数据库的运行状态,可以分为三种
1)冷备:停库、停服务来备份
即当数据库进行备份时, 数据库不能进行读写操作, 即数据库要下线
2)温备:不停库、不停服务来备份,会(锁表)阻止用户的写入即当数据库进行备份时, 数据库的读操作可以执行, 但是不能执行写操作
3)热备(建议):不停库、不停服务来备份,也不会(锁表)阻止用户的写入
即当数据库进行备份时, 数据库的读写操作均不是受影响
MySQL中进行不同类型的备份还要考虑存储引擎是否支持
-
MyISAM ---------> 热备 × 温备 √ 冷备 √
-
InnoDB ----------> 热备 √ 温备 √ 冷备 √
2)物理与逻辑
按照备份的内容分,可以分为两种
-
1、物理备份:直接将底层物理文件备份
-
2、逻辑备份:通过特定的工具从数据库中导出sql语句 或者数据,可能会丢失数据精度
3)全量、差异、增量
按照每次备份的数据量,可以分为
-
全量备份/完全备份(Full Backup):备份整个数据集( 即整个数据库 )
-
部分备份:备份部分数据集(例如: 只备份一个表的变化)
而部分备份又分为:差异备份和增量备份两种
# 1、差异备份(Differential Backup)
每次备份时,都是基于第一次完全备份的内容,只备份有差异的数据(新增的、修改的、删除的),例如
第一次备份:完全备份
第二次备份:以当前时间节点的数据为基础,备份与第一次备份内容的差异
第三次备份:以当前时间节点的数据为基础,备份与第一次备份内容的差异
第四次备份:以当前时间节点的数据为基础,备份与第一次备份内容的差异
第五次备份:以当前时间节点的数据为基础,备份与第一次备份内容的差异
# 2、增量备份(Incremental Backup )
每次备份时,都是基于上一次备份的内容(注意是上一次,而不是第一次),只备份有差异的数据(新增的、修改的、删除的),所以增量备份的结果是一条链,例如
第一次备份:完全备份
第二次备份:以当前时间节点的数据为基础,备份与第一次备份内容的差异
第三次备份:以当前时间节点的数据为基础,备份与第二次备份内容的差异
第四次备份:以当前时间节点的数据为基础,备份与第三次备份内容的差异
第五次备份:以当前时间节点的数据为基础,备份与第四次备份内容的差异
针对上述三种备份方案,如何恢复数据呢
# 1、全量备份的数据恢复
只需找出指定时间点的那一个备份文件即可,即只需要找到一个文件即可
# 2、差异备份的数据恢复
需要先恢复第一次备份的结果,然后再恢复最近一次差异备份的结果,即需要找到两个文件
# 3、增量备份的数据恢复
需要先恢复第一次备份的结果,然后再依次恢复每次增量备份,直到恢复到当前位置,即需要找到一条备份链
综上,对比三种备份方案
1、占用空间:全量 > 差异 > 增量
2、恢复数据过程的复杂程度:增量 > 差异 > 全量
1.4 备份的工具
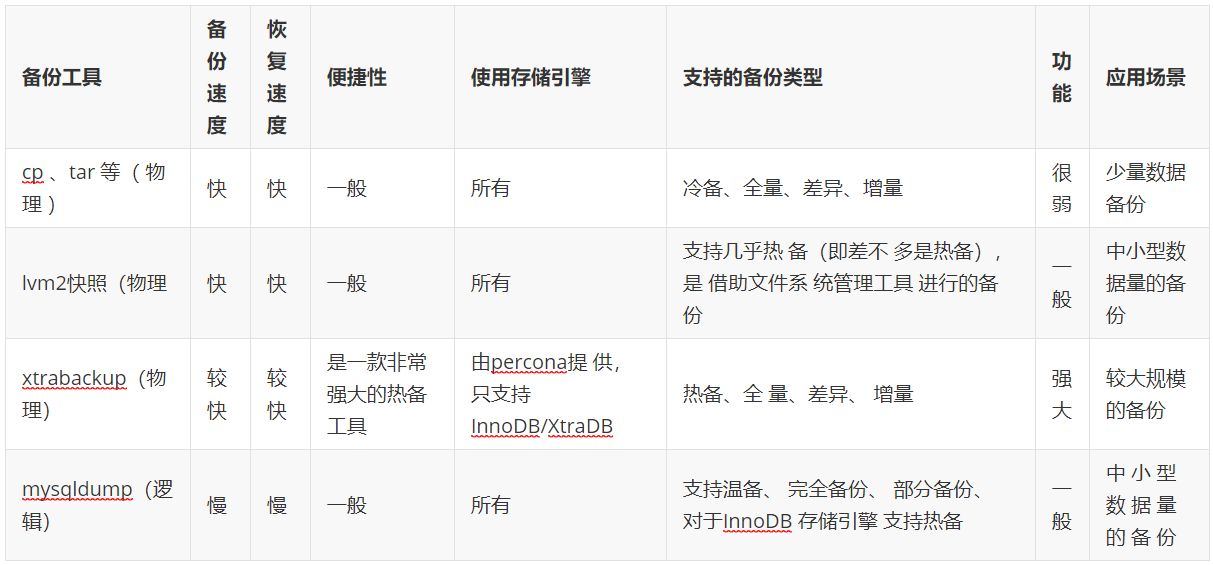
此外,如果考虑到增量备份,还需要结合binlog日志 (binlog只属于增量恢复),需要用到工具mysqlbinlog,, 相当于逻辑备份的一种
二、 设计备份策略
2.1 备份策略设计的参考值
备份数据的策略要根据不同的应用场景进行定制, 大致有几 个参考数值, 我们可以根据这些数值从而定制符合特定环境 中的数据备份策略
-
能够容忍丢失多少数据
-
恢复数据需要多长时间
-
需要恢复哪一些数据
2.2 三种备份策略及应用场景
针对不同的场景下, 我们应该制定不同的备份策略对数据库 进行备份, 一般情况下, 备份策略一般为以下三种
-
1、直接cp,tar复制数据库文件
-
2、mysqldump+复制BIN LOGS
-
3、 lvm2快照+复制BIN LOGS
-
4、xtrabackup
以上的几种解决方案分别针对于不同的场景
- 如果数据量较小, 可以使用第一种方式, 直接复制数据库 文件
- 如果数据量还行, 可以使用第二种方式, 先使用 mysqldump对数据库进行完全备份, 然后定期备份 BINARY LOG达到增量备份的效果
- 如果数据量一般, 而又不过分影响业务运行, 可以使用第 三种方式, 使用lvm2的快照对数据文件进行备份, 而后定 期备份BINARY LOG达到增量备份的效果
- 如果数据量很大, 而又不过分影响业务运行, 可以使用第 四种方式, 使用xtrabackup进行完全备份后, 定期使用 xtrabackup进行增量备份或差异备份
3 逻辑备份和物理备份的比较
1.mysqldump (MDP)
优点:
1.不需要下载安装
2.备份出来的是SQL,文本格式,可读性高,便于备份处理
3.压缩比较高,节省备份的磁盘空间
缺点:
4.依赖于数据库引擎,需要从磁盘把数据读出
然后转换成SQL进行转储,比较耗费资源,数据量大的话效率较低
建议:
100G以内的数据量级,可以使用mysqldump
超过TB以上,我们也可能选择的是mysqldump,配合分布式的系统
1EB =1024 PB =1000000 TB
2.xtrabackup(XBK)
优点:
1.类似于直接cp数据文件,不需要管逻辑结构,相对来说性能较高
缺点:
2.可读性差
3.压缩比低,需要更多磁盘空间
建议:
>100G<TB
3.备份策略
备份方式:
全备:全库备份,备份所有数据
增量:备份变化的数据
逻辑备份=mysqldump+mysqlbinlog
物理备份=xtrabackup_full+xtrabackup_incr+binlog或者xtrabackup_full+binlog
备份周期:
根据数据量设计备份周期
比如:周日全备,周1-周6增量
三、 备份实战
3.1 使用cp进行备份----> 备份步骤
#1、向所有表施加读锁
FLUSH TABLES WITH READ LOCK;
#2、备份数据文件
mkdir /cp_bak
cp -a /var/lib/mysql/* /cp_bak
模拟数据丢失并恢复
# 数据丢失
rm -rf /var/lib/mysql/*
# 恢复数据
cp -a /cp_bak/* /var/lib/mysql
# 重启服务
systemctl restart mysql
3.2 使用mysqldump+复制binary logs备份
mysqldump命令
#==========语法
mysqldump -h 服务器 -u用户名 -p密码 选项与参数
> 备份文件.sql
===选项与参数
-A/--all-databases 所有库
-B/--databases bbs db1 db2 多个数据库
db1 数据库名
db1 t1 t2 db1数据库的表t1、t2
-F 备份的同时刷新binlog
-R 备份存储过程和函数数据(如果开发写了函数和存储过程,就备,没写就不备)
--triggers 备份触发器数据(现在都是开发写触发器)
-E/--events 备份事件调度器
-d 仅表结构
-t 仅数据
--master-data=1 备份文件中 change master语句是没有注释的,默认为1.用于已经制作好了主从,现在想扩展一个从库的时候使用如此备份,扩展添加从库时导入备份文件后便不需要再加mater_pos了
change matser to
master_host='10.0.0.111'
master_user='rep'
master_password=123
master_log_pos=120
master_log_file='master-bin.000001'
--master-data=2 备份文件中 change master语句是被注释的
--lock-all-tables, 提交请求锁定所有数据库中的所有表,以保证数据的一致性。这是一个全局读锁,并且自动关闭--single-transaction 和--lock-tables 选项,他们是互斥的
对于支持事务的表例如InnoDB和BDB,推荐使用--single-transaction选项,因为它根本不需要锁定表
--single-transaction: 快照备份 (搭配--master-data可以做到热备)
**该选项在导出数据之前提交一个BEGIN SQL语句,BEGIN 不会阻塞任何应用程序且能保证导出时数据库的一致性状态。它只适用于多版本存储引擎,仅InnoDB。
本选项和--lock-tables 选项是互斥的,不能同时存在,因为LOCK TABLES 会使任何挂起的事务隐含交。
#==========完整语句
mysqldump -uroot -pcdan@123 -A -R --triggers --master-data=2 –single-transaction >
/backup/full.sql
#====文件太大时可以压缩 gzip ,但是gzip不属于mysql独有的命令,可以利用管道
mysqldump -uroot -pcdan@123 -A -R --triggers --master-data=2 --single-transaction | gzip >/tmp/full$(date +%F).sql.gz
#====导出时压缩了,导入时需要解压,可以使用zcat命令,很方便
zcat /backup/full$(date +%F).sql.gz | mysql -uroot -p123
储备知识:binlog内容很多,如何定位到某个固定的点
===> 1、grep过滤
===> 2、检查事件:依据End_log_pos的提示,来确定某一个事件的起始位置与结束位置
mysql> show binlog events in'mybinlog.000001';
如果事件很多,可以分段查看
mysql> show binlog events in 'mybinlog.000001'limit 0,30;
mysql> show binlog events in 'mybinlog.000001'limit 30,30;
mysql> show binlog events in 'mybinlog.000001'limit 60,30;
===> 3、利用mysqlbinlog命令
生产中很多库,只有一个库的表被删除,我不可能把所有的库都导出来筛选,因为那样子binlog内容很多,辨别复杂度高,我们可以利用
[root@egon mysql]# mysqlbinlog -d db1 --start-position=123 --stop-position=154
mybinlog.000001 --base64-output=decode-rows -vvv | grep -v 'SET'
参数解释:
1)-d 参数接库名
mysqlbinlog -d database --base64-output=decode-rows -vvv mysql-bin.000002
2)--base64-output 显示模式
3)-vvv 显示详细信息
备份:
# 1、先打开binlog日志
vim /etc/my.cnf
[mysqld]
server_id=1
log-bin=/var/lib/mysql/mybinlog
binlog_format='row' #(row,statement,mixed)
binlog_rows_query_log_events=on
max_binlog_size=100M
# 2、登录数据库,插入测试数据
mysql> reset master; #为了实验,把binlog日志全部删掉
mysql> create database db3;
mysql> use db3;
mysql> create table t1(id int);
mysql> insert t1 values(1),(2),(3);
# 3、在命令行执行命令,进行全量备份
[root@db02 mysql]# mysqldump -uroot -p'Caodan@111' -A -R -F --triggers --master-data=2 --single-transaction | gzip > /tmp/full.sql.gz
##--master-data=2 --single-transaction这2个选项写一起等于热备
# 4、在命令行执行命令,刷新binlog,便于日后查找
[root@db02 mysql]# mysql -uroot -p'Caodan@111' -e"flush logs"
# 5、登录数据库,再插入一些数据,模拟增量,这些数据写入了新的binlog
mysql> use db3;
mysql> insert t1 values(4),(5),(6);
模拟数据损坏恢复
# 模拟数据丢失
mysql> drop database db1;
# 恢复数据
# 1、mysql数据导入时,临时关闭binlog,不要将恢复数据的写操作也记入
mysql> set sql_log_bin=0;
# 2、先恢复全量
mysql> source /tmp/full.sql
如果是压缩包呢,那就这么做
mysql> system zcat /tmp/full.sql.gz | mysql -uroot -pcdan@123
# 3、再恢复增量
导出:注意导出binlog时不要加选项--base64-output
[root@egon mysql]# mysqlbinlog mybinlog.000002--stop-position=531 > /tmp/last_bin.log
导入
mysql> source /tmp/last_bin.log
# 4、开启二进制日志
mysql> SET sql_log_bin=ON;
测试在线热备份 可以先准备一个存储过程,一直保持写入操作,然后验证热 备
#1. 准备库与表
create database if not exists db1;
use db1;
create table s1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
#2. 创建存储过程,每隔3秒插入一条
delimiter $$ #声明存储过程的结束符号为$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<3000000)do
insert into s1
values(i,'egon','male',concat('egon',i,'@oldboy'));
select concat('egon',i,'_ok') as name,sleep(3);
set i=i+1;
end while;
END$$ #$$结束
delimiter ;
#3. 查看存储过程
show create procedure auto_insert1G
备份:
# 1、先打开binlog日志
# 1、先打开binlog日志
vim /etc/my.cnf
[mysqld]
server_id=1
log-bin=/var/lib/mysql/mybinlog
binlog_format='row' #(row,statement,mixed)
binlog_rows_query_log_events=on
max_binlog_size=100M
# 2、登录数据库,执行存储过程
mysql> use db1;
mysql> call auto_insert1();
若想杀死存储过程
mysql> show processlist; -- 查出id
mysql> kill id号;
# 3、在命令行执行下述命令,进行全量备份
[root@egon mysql]# mysqldump -uroot -pCdan@111 -A -R --triggers --master-data=2 --single-transaction | gzip > /tmp/full.sql.gz
# 4、全量备份完毕后的一段时间里,数据依然插入,写入了
mybinlog.000001中
# 然后我们在命令行刷新binlog,产生了新的mybinlog.000002
[root@egon mysql]# mysql -uroot -pCdan@111 -e "flush logs"
# 5、此时数据依然在插入,但都写入了最新的mybinlog.000002中,所以需要知道的是,增量的数据在mysqlbinlog.000001与mybinlog.000002中都有我们登录数据库,杀掉存储过程,观察到最新的数据插到了id=55的行
mysql> show processlist; -- 查出id
mysql> kill id号;
删除数据
drop database db1;
恢复数据
# 登录数据库,先恢复全量
mysql> set sql_log_bin=0;
mysql> system zcat /tmp/full.sql.gz | mysql -uroot -pCdan@111;
mysql> select * from db1.s1; -- 查看恢复到了id=28,剩下的去增量里恢复
# 在命令行导出mybinlog.000001中的增量,然后登录库进行恢复查找位置,发现@1=29即第一列等于29,即id=29的下一个position是10275
mysql> show binlog events in'mybinlog.000001';
[root@egon mysql]# mysqlbinlog mybinlog.000001--start-position=10038 --stop-position=11340--base64-output=decode-rows -vvv | grep -v'SET' | less
在命令行中执行导出
[root@egon mysql]# mysqlbinlog mybinlog.000001--start-position=10275 > /tmp/1.sql
在库内执行导入,发现恢复到了39
mysql> source /tmp/1.sql -- 最好是在库内恢复,因为sql_log_bin=0,导入操作不会记录
mysql> select * from db1.s1;
# 在命令行导出mybinlog.000002中的增量,然后登录库进行恢复上面恢复到了id=39,我们接着找id=40的进行恢复,查找位置
发现@1=40的position是432
发现@1=55的position是6464
mysql> show binlog events in'mybinlog.000002';
[root@egon mysql]# mysqlbinlog --base64-output=decode-rows -vvv mybinlog.000002|grep -v 'SET'|grep -C20 -w '@1=40'
[root@egon mysql]# mysqlbinlog --base64-output=decode-rows -vvv mybinlog.000002|grep -v 'SET'|grep -C20 -w '@1=55'
导出
[root@egon mysql]# mysqlbinlog mybinlog.000002--start-position=432 --stop-position=6464>/tmp/2.sql
在库内执行导入,发现恢复到了55
mysql> source /tmp/2.sql
mysql> select * from db1.s1;
# 开启binlog
mysql> SET sql_log_bin=ON;
问题:能否利用binlog做全量恢复
可以,但直接使用binlog做全量恢复,成本很高,我们只用起来做增量恢复。
正确的方案是:全备+binlog增量
每天或者每周全备一次,全备之后,那个位置点之前的binlog全都可以删除,不可能一年有上百个binlog的库都导出来筛选,因为那样子binlog内容很多,辨别复杂度高,我们可以利用
3.3 使用lvm2快照备份数据
部署lvm环境
# 1、添加硬盘; 这里我们直接实现SCSI硬盘的热插拔, 首先
在虚拟机中添加一块硬盘, 无需重启
echo '- - -' > /sys/class/scsi_host/host0/scan
echo '- - -' > /sys/class/scsi_host/host1/scan
echo '- - -' > /sys/class/scsi_host/host2/scan
# 2、创建逻辑卷
pvcreate /dev/sdb
vgcreate vg1 /dev/sdb
lvcreate -n lv1 -L 5G vg1
# 3、格式化制作文件系统并挂载
mkfs.xfs /dev/mapper/vg1-lv1
mkdir /lv1
mount /dev/mapper/vg1-lv1 /var/lib/mysql
chown -R mysql.mysql /var/lib/mysql
# 4、修改mysql配置文件的datadir如下
[root@node1 ~]# rm -rf /var/lib/mysql/* # 删除原数据
[root@node1 ~]# vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
# 5、重启MySQL、完成初始化
[root@node1 ~]# systemctl restart mysqld
# 6、往数据库内插入测试数据
create database db3;
use db3;
create table t1(id int);
insert t1 values(1),(2),(3);
创建快照卷并备份
mysql> FLUSH TABLES WITH READ LOCK; #锁定所有表
Query OK, 0 rows affected (0.00 sec)
[root@node1 lvm_data]# lvcreate -L 1G -s -n lv1_from_vg1_snap /dev/vg1/lv1 #创建快照卷
mysql> UNLOCK TABLES; #解锁所有表
Query OK, 0 rows affected (0.00 sec)
[root@node1 lvm_data]# mkdir /snap1 #创建文件夹
[root@node1 lvm_data]# mount -o nouuid/dev/vg1/lv1_from_vg1_snap /snap1
[root@localhost snap1]# cd /snap1/
[root@localhost snap1]# tar cf /tmp/mysqlback.tar *
[root@localhost snap1]# umount /snap1/ -l
[root@localhost snap1]# lvremove vg1/lv1_from_vg1_snap
恢复数据
rm -rf /var/lib/mysql/*
# 恢复
tar xf /tmp/mysqlback.tar -C /var/lib/mysql/
3.4 物理备份之Xtrabackup
(1)介绍
Xtrabackup是由percona提供的mysql数据库备份工具, 据官方介绍,这也是世界上惟一一款开源的能够对innodb 和xtradb数据库进行热备的工具。特点:
- 备份过程快速、可靠;
- 备份过程不会打断正在执行的事务;
- 能够基于压缩等功能节约磁盘空间和流量;
- 自动实现备份检验;
- 还原速度快;
使用xtrabackup使用InnoDB能够发挥其最大功效, 并且 InnoDB的每一张表必须使用单独的表空间, 我们需要在配置 文件中添加 innodb_file_per_table = ON 来开启
(2)安装
版本选择
mysql 5.7以下版本,可以采用percona xtrabackup 2.4版本
mysql 8.0以上版本,可以采用percona xtrabackup 8.0版本,xtrabackup8.0也只支持mysql8.0以上的版本
比如,接触过一些金融行业,mysql版本还是多采用mysql5.7,当然oracle官方对于mysql 8.0的开发支持力度日益加大,新功能新特性迭代不止。生产环境采用mysql 8.0的版本比例会日益增加。
安装方式一**
# 安装yum仓库
wget https://repo.percona.com/yum/percona-release-latest.noarch.rpm
rpm -ivh percona-release-latest.noarch.rpm
# 安装XtraBackup命令
yum install percona-xtrabackup-24 -y
安装方式二
#下载epel源
wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
#安装依赖
yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL
#下载Xtrabackup
wget https://downloads.percona.com/downloads/Percona-XtraBackup-2.4/Percona-XtraBackup-2.4.23/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.23-1.el7.x86_64.rpm
# 安装
yum localinstall -y percona-xtrabackup-24-2.4.4-1.el6.x86_64.rpm
安装完后会生成命令
xtrabackup 以前使用该命令
innobackupex 现在使用该命令
innobackupex是xtrabackup的前端配置工具,使用innobackupex备份时, 会调用xtrabackup备份所有的InnoDB表, 复制所有关于表结构定义的相关文件(.frm)、以及MyISAM、MERGE、CSV和ARCHIVE表的相关文件, 同时还会备份触发器和数据库配置文件信息相关的文件, 这些文件会被保存至一个以时间命名的目录.
(3)Xtrabackup 备份方式(物理备份)
1.对于非innodb表(比如myisam)是直接锁表cp数据文件,属于一种温备。
2.对于innodb的表(支持事务),不锁表,cp数据页最终以数据文件方式保存下来,并且把redo和undo一并备走,属于热备方式。
3.备份时读取配置文件/etc/my.cnf
(4)Xtrabackup全量备份
#1、创建备份目录,会把mysql的datadir中的内容备份到改目录中
mkdir /backup
#2、全备
#2.1 在本地执行下述命令,输入登录数据的本地账号与密码
#2.2 指定备份目录为/backup下的full目录
innobackupex --user=root --password=Cdan@111 /backup/full
#3、查看:默认会在备份目录下生成一个以时间戳命名的文件夹
[root@localhost ~]# cd /backup/full/
[root@localhost full]# ls
2021-07-16_16-09-47
[root@localhost full]# ls 2021-07-16_16-09-47/
#备份目录
。。。
[root@localhost full]# ls /var/lib/mysql # 数据目录
# 4、去掉时间戳,让备份数据直接放在备份目录下
我们在写备份脚本和恢复脚本,恢复的时候必须指定上一次备份的目录,如果备份目录带着时间戳,该时间戳我们很难在脚本中确定,为了让脚本编写更加方便,我们可以使用选项--no-timestamp去掉时间戳,让备份内容直接放置于我们指定的目录下(ps:金融公司喜欢每天全备,每小时增备,如果备份目录带着时间戳,看似合理,但确实会很让头疼)
[root@localhost full]# rm -rf 2021-07-16_17-45-53/
[root@localhost full]# innobackupex --user=root --password=Cdan@111 --no-timestamp/backup/full
# 补充:关于备份目录下新增的文件说明,可用cat命令查看
xtrabackup_checkpoints 存储系统版本号,增备的时候会用到
xtrabackup_info 存储UUID,数据库是由自己的UUID的,如果相同,做主从会有问题
xtrabackup_logfile 就是redo
(5)Xtrabackup增量备份
#一 基于上一次备份进行增量,参数说明:
--incremental:开启增量备份功能
--incremental-basedir:上一次备份的路径
#二 加上上一次命令
innobackupex --user=root --password=Cdan@111 --no-timestamp --incremental --incremental-basedir=/backup/full/ /backup/xtra
#三 判断数据备份是否衔接
cat /backup/full/xtrabackup_checkpoints
backup_type = full-backuped
from_lsn = 0
to_lsn = 1808756
last_lsn = 1808756
compact = 0
recover_binlog_info = 0
flushed_lsn = 1808756
cat /backup/xtra/xtrabackup_checkpoints
backup_type = incremental
from_lsn = 1808756 # 值应该与全被的to_lsn一致
to_lsn = 1808756
last_lsn = 1808756
compact = 0
recover_binlog_info = 0
flushed_lsn = 1808756
更多参数详见:https://www.cnblogs.com/linhaifeng/arti cles/15021166.html
(6)企业实战:Xtrabackup + Binlog恢复
mysql配置文件:数据目录与binlog放在不同的文件夹下
[mysqld]
datadir=/var/lib/mysql
default-storage-engine=innodb
innodb_file_per_table=1
server_id=1
log-bin=/data/binlog/mybinlog
binlog_format='row' #(row,statement,mixed)
binlog_rows_query_log_events=on
max_binlog_size=100M
为binlog日志创建目录
mkdir -p /data/binlog/
chown -R mysql.mysql /data/
启动mysql
systemctl restart mysqld
模拟数据
create database full charset utf8mb4;
use full;
create table t1 (id int);
insert into t1 values(1),(2),(3);
commit;
进行周日的全备
# 1、事先创建好备份目录
[root@db01 backup]# rm -rf /backup
[root@db01 backup]# mkdir /backup
# 2、全备
[root@db01 backup]# innobackupex --user=root --password=Cdan@111 --no-timestamp --parallel=5 /backup/full
模拟周一的数据变化
create database inc1 charset utf8mb4;
use inc1;
create table t1 (id int);
insert into t1 values(1),(2),(3);
commit;
进行周一的增量备份
innobackupex --user=root --password=Cdan@111 --no-timestamp --incremental --incremental-basedir=/backup/full /backup/inc1
检查本次备份的LSN
[root@localhost backup]# cat /backup/full/xtrabackup_checkpoints
backup_type = full-backuped
from_lsn = 0
to_lsn = 1817002
last_lsn = 1817002
compact = 0
recover_binlog_info = 0
flushed_lsn = 1817002
[root@localhost backup]# cat /backup/inc1/xtrabackup_checkpoints
backup_type = incremental
from_lsn = 1817002
to_lsn = 1825905
last_lsn = 1825905
compact = 0
recover_binlog_info = 0
flushed_lsn = 1825905
模拟周二数据变化
create database inc2 charset utf8mb4;
use inc2;
create table t1 (id int);
insert into t1 values(1),(2),(3);
commit;
周二的增量
innobackupex --user=root --password=Cdan@111 --no-timestamp --incremental --incremental-basedir=/backup/inc1 /backup/inc2
周三的数据变化
create database inc3 charset utf8mb4;
use inc3;
create table t1 (id int);
insert into t1 values(1),(2),(3);
commit;
模拟上午10点数据库崩溃
systemctl stop mysqld # pkill -9 mysqld
m -rf /var/lib/mysql/*
恢复思路
1. 停业务,挂维护页
2. 查找可用备份并处理备份:full+inc1+inc2
3. 找到binlog中: inc2 到 故障时间点的binlog
4. 恢复全备+增量+binlog
5. 验证数据
6. 起业务,撤维护页
恢复前的准备
所有增量必须要按顺序合并到全备当中才能用于恢复
#(1) 整理full
innobackupex --apply-log --use-memory=3G --redo-only /backup/full
--apply-log:该选项表示同xtrabackup的--prepare参数,一般情况下,在备份完成后,数据尚且不能用于恢复操作,因为备份的数据中可能会包含尚未提交的事务或已经提交但尚未同步至数据文件中的事务。因此,此时数据 文件仍处理不一致状态。--apply-log的作用是通过回滚未提交的事务及同步已经提交的事务至数据文件使数据文件处于一致性状态。
#(2) 合并inc1到full,并整理备份
innobackupex --apply-log --use-memory=3G --redo-only --incremental-dir=/backup/inc1 /backup/full
#(3) 合并后对比inc1与full的LSN号:last_lsn保持一致
cat /backup/full/xtrabackup_checkpoints
cat /backup/inc1/xtrabackup_checkpoints
#(4) 合并inc2到full,并整理备份 (合并最后一个增量备份时不要加--redo-only)
innobackupex --apply-log --use-memory=3G --incremental-dir=/backup/inc2 /backup/full
#(5) 合并后对比inc2与full的LSN号:last_lsn保持一致
cat /backup/full/xtrabackup_checkpoints
cat /backup/inc2/xtrabackup_checkpoints
#(6) 最后一次整理ful
innobackupex --use-memory=3G --apply-log/backup/full
#(7) 截取二进制日志
# 起点
cat /backup/inc2/xtrabackup_binlog_info验证
输出内容如下
mysql-bin.000031 1997 aa648280-a6a6-11e9-949f-000c294a1b3b:1-17,e16db3fd-a6e8-11e9-aee9-000c294a1b3b:1-9
# 终点:
mysqlbinlog /data/binlog/mysql-bin.000031|grep 'SET'SET @@SESSION.GTID_NEXT= 'e16db3fd-a6e8-11e9-aee9-000c294a1b3b:12'/*!*/;
# 导出:
mysqlbinlog --skip-gtids --include-gtids='e16db3fd-a6e8-11e9-aee9-
000c294a1b3b:10-12' /data/binlog/mysql-bin.000031>/backup/binlog.sql
或:
mysqlbinlog /data/binlog/mybinlog.000003 --start-position=1648 > /backup/binlog.sql恢复备份的数据
cp -a /backup/full/* /var/lib/mysql
chown -R mysql.mysql /var/lib/mysql
systemctl start mysql
mysql -uroot -p123
> set sql_log_bin=0;
> source /backup/binlog.sql
验证
select * from full.t1;
select * from inc1.t1;
select * from inc2.t1;
select * from inc3.t1;
恢复
四、 自动备份脚本
4.1 备份计划
1. 什么时间 2:00
2. 对哪些数据库备份
3. 备份文件放的位置
4.2 备份脚本(基于mysqldump)
备份脚本:
[root@egon ~]# vim /mysql_back.sh
#!/bin/bash
back_dir=/backup
back_file=`date +%F`_all.sql
user=root
pass=123
if [ ! -d /backup ];then
mkdir -p /backup
fi
# 备份并截断日志
mysqldump -u${user} -p${pass} --events -R --triggers --master-data=2 --single-transaction--all-databases > ${back_dir}/${back_file}
mysql -u${user} -p${pass} -e 'flush logs'
# 只保留最近一周的备份
cd $back_dir
find . -mtime +7 -exec rm -rf {} ;
4.3 手动测试
手动测试:
chmod a+x /mysql_back.sh
chattr +i /mysql_back.sh
bash /mysql_back.sh
4.4 配置计划任务
配置cron:
[root@egon ~]# crontab -l
0 2 * * * /mysql_back.sh
五 、企业案例
5.1 背景
1.正在运行的网站系统,MySQL数据库,数据量25G,日业务增量10-15M。
2.备份策略:每天23:00,计划任务调用mysqldump执行全备脚本
3.故障时间点:上午10点开发人员误删除一个核心业务表,如何恢复?
5.2 处理故障思路
1.停业务避免数据的二次伤害
2.找一个临时的库,恢复前一天的全备
3.截取前一天23:00到第二天10点误删除之间的binlog,恢复到临时库
4.测试可用性和完整性
5.开启业务前的两种方式
1)直接使用临时库顶替原生产库,前端应用割接到新
2)将误删除的表单独导出,然后导入到原生产环境
6.对外开放业务
5.3 故障模拟
1)准备初始数据
#刷新binlog使内容更清晰
flush logs;
#查看当前使用的binlog
show master status;
#准备测试库与数据
create database dbtest;
use dbtest;
create table t1(id int,name varchar(16));
insert t1 values
(1,"egon1"),
(2,"egon2"),
(3,"egon3");
create table t2 select * from t1;
2)全备
[root@db01 ~]# mkdir /backup
[root@db01 ~]# mysqldump -uroot -pEgon@123 -A
-R --triggers --master-data=2 --single-transaction |gzip > /backup/full.sql.gz # 通常备份文件应该带时间,此处略
3)模拟23:00到10:00的操作
use dbtest;
create table t3 select * from t1;
select * from t3;
update t1 set name="EGON" where id=2;
delete from t2 where id>2;
4)模拟10:00删库操作
#删库、跑路
drop database dbtest;
5.4 恢复数据
1)先停生产库,避免数据二次伤害
[root@db01 ~]# systemctl stop mysql
2)准备新库,在新库中完成数据恢复操作后再 更新给生成库
3)通过binlog找到23:00到第二天10:00之间新 增的数据
#1.找到结束位置点:
mysql> show master status;
mysql> show binlog events in'mybinlog.000002';
[root@localhost backup]# cd /var/lib/mysql
[root@localhost mysql]# mysqlbinlog --base64-output=decode-rows -vvv --start-datetime="2021-07-16 02:00:00" mybinlog.000002
3.取出位置点之间新增的数据
[root@db01 ~]# mysqlbinlog --start-position=694 --stop-position=1249
mybinlog.000002 > /backup/xin.sql
4)将前一天的全备数据和新增的数据拷贝到新 数据库
scp /backup/full.sql.gz 172.16.1.52:/tmp/
scp /backup/xin.sql 172.16.1.52:/tmp/
5)将前一天的全备与增量恢复到新库
mysql> set sql_log_bin=0;
mysql> system zcat /tmp/full.sql.gz | mysql -uroot -pEgon@123
mysql> source /tmp/xin.sql;
6)查看表和数据验证数据完整
mysql> use dbtest;
mysql> show tables;
mysql> select * from t1;
mysql> select * from t2;
mysql> select * from t3;
7)恢复生产环境提供服务
1.将恢复的表导出,导入到生产库(如果核心业务表很小)
1)导出指定表
[root@db02 mysql]# mysqldump dbtest t1t2 t3 > /tmp/test.sql
2)将sql传输到生产库
[root@db02 mysql]# scp /tmp/test.sql172.16.1.51:/tmp/
3)指定库导入表
[root@db01 data]# mysql backup </tmp/test.sql
2.应用服务修改数据库配置连接到新库(如果核心业务表很大)