一、文件的操作
介绍
计算机系统分为:计算机硬件,操作系统,应用程序三部分。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
1 #1. 打开文件,得到文件句柄并赋值给一个变量 2 #2. 通过句柄对文件进行操作 3 #3. 关闭文件
1、打开一个文件
语法:
open(filename,mode)
解释:
filename:代表你要访问的文件名
mode:这里代表你打开文件的模式,有 只读,写入,读写,追加等模式;默认为只读模式。
我们可以看下面的列表:

1、读模式 r 以只读方式打开文件。
文件的指针将会放在文件的开头。这是默认模式
例子:
1 f = open("foo.txt", "r",encoding="UTF-8") #只读的方式打开的文件,encoding是转码的意思,告诉解释器,是以UTF-8的格式 2 i=f.read() # 读取文件,bing 赋值给i 3 print(i) #打印i 4 f.close() #关闭文件夹
输出:
Python 是一个非常好的语言。
是的,的确非常好!!
2、读写模式 r+ 打开一个文件用于读写。
文件指针将会放在文件的开头。
例子:
1 f = open("foo.txt", "r+",encoding="UTF-8") #读写的方式打开的文件,encoding是转码的意思,告诉解释器,是以UTF-8的格式 2 i=f.read() # 读取文件,bing 赋值给i 3 print(i) #打印i 4 f.write("我要学Python ") #写入 5 # f.flush() 6 f.close() #关闭文件夹
输出:
我要学Python
我要学Python
3、写模式 w 打开一个文件只用于写入。
如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件
例子:
1 f = open("foo.txt", "w",encoding="UTF-8") #写的方式打开的文件,encoding是转码的意思,告诉解释器,是以UTF-8的格式 2 f.write("我要学Python ") #写入,文件夹存在覆盖,不存在创建 3 f.close() #关闭文件夹
4、读写模式 w+ 打开一个文件用于读写。
如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件
例子:
1 f = open("foo.txt", "w+",encoding="UTF-8") #写的方式打开的文件,encoding是转码的意思,告诉解释器,是以UTF-8的格式 2 f.write("我要学Python ") #写入,文件夹存在覆盖,不存在创建 3 print("定位之前的光标位置:%s" % (f.tell())) 4 f.flush() #刷新文件使内存的内容刷新至文件夹 5 f.seek(0) #因为W+读取文件之后会定位在文件尾部,所以需要重新定位一下光标位置,要不无法读取 6 print("定位之后的光标位置:%s" % (f.tell())) 7 i = f.read() 8 print(i) 9 f.close() #关闭文件夹
输出:
定位之前的光标位置:17
定位之后的光标位置:0
我要学Python
5、追加 a 打开一个文件用于追加。
如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入
例子:
1 f = open("foo.txt", "a",encoding="UTF-8") #追加方式打开的文件,encoding是转码的意思,告诉解释器,是以UTF-8的格式 2 f.write("我要学Python ") #写入,文件夹存在追加,不存在创建 3 print("定位之前的光标位置:%s" % (f.tell())) 4 f.seek(0) #因为a追加文件之后会定位在文件尾部,所以需要重新定位一下光标位置,要不无法读取 5 print("定位之后的光标位置:%s" % (f.tell())) 6 f.close() #关闭文件夹
6、追加读 a+打开一个文件用于读写。
如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
例子:
1 f = open("foo.txt", "a+",encoding="UTF-8") #追加读方式打开的文件,encoding是转码的意思,告诉解释器,是以UTF-8的格式 2 f.write("我要学Python ") #写入,文件夹存在创建,不存在创建 3 print("定位之前的光标位置:%s" % (f.tell())) 4 f.flush() #刷新文件使内存的内容刷新至文件夹 5 f.seek(0) #因为W+读取文件之后会定位在文件尾部,所以需要重新定位一下光标位置,要不无法读取 6 print("定位之后的光标位置:%s" % (f.tell())) 7 i = f.read() 8 print(i) 9 f.close() #关闭文件夹
输出:
1 定位之前的光标位置:136 2 定位之后的光标位置:0 3 我要学Python 4 我要学Python 5 我要学Python 6 我要学Python 7 我要学Python
二、文件的操作方法
文件的常用方法有13种,如下图:
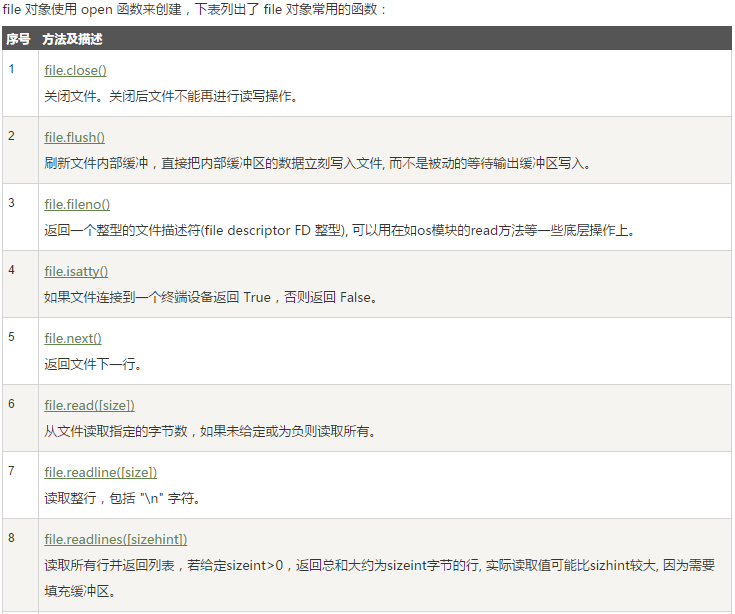
文件的file.close、file.flush、file.seek、file.tell在前面文件的读、写、追加已经介绍过了这里就不一一说了,下面我们说一下剩余的几种方法吧!
1、fileno()
方法返回一个整型的文件描述符(file descriptor FD 整型),可用于底层操作系统的 I/O 操作
语法:
fileObject.fileno()
返回值:文件描述符
例子
1 f = open("foo.txt", "a+",encoding="UTF-8") #追加读方式打开的文件,encoding是转码的意思,告诉解释器,是以UTF-8的格式 2 fid = f.fileno() 3 print("文件的描述符为:",fid) 4 f.close() #关闭文件夹
输出:
文件的描述符为: 3
2、next()
返回文件的下一行
语法:
next(iterator[,default])
例子:
1 # 打开文件 2 fo = open("foo.txt", "r",encoding="UTF-8") 3 print ("文件名为: ", fo.name) 4 for index in range(5): 5 line = next(fo) 6 print ("第 %d 行 - %s" % (index, line)) 7 # 关闭文件 8 fo.close()
输出:
# 文件名为: foo.txt # 第 0 行 - 我要学Python0 # 第 1 行 - 我要学Python1 # 第 2 行 - 我要学Python2 # 第 3 行 - 我要学Python3 # 第 4 行 - 我要学Python4
3、read方法:
用于从文件读取指定的字节数,如果为给定或为负则读取所有
语法:
fileObject.read()
例子:
1 fo = open("foo.txt", "r",encoding="UTF-8") 2 print ("文件名为: ", fo.name) 3 line = fo.read() #不指定字符节读取所有 4 print(line) 5 fo.close() # 关闭文件 6 # 如下: 7 # C:Python35python.exe D:/linux/python/all_test/总练习.py 8 # 文件名为: foo.txt 9 # 我要学Python0 10 # 我要学Python1 11 # 我要学Python2 12 # 我要学Python3 13 # 我要学Python4 14 # 我要学Python5 15 16 =========================================== 17 fo = open("foo.txt", "r",encoding="UTF-8") 18 print ("文件名为: ", fo.name) 19 line = fo.read(16) #指定读取16字节 20 print(line) 21 fo.close() # 关闭文件
输出:
# 文件名为: foo.txt # 我要学Python0 # 我要学Py
4、readline()
方法用于从文件读取整行,包括 " " 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 " " 字符。
语法:
fileObject.readline()
例子:
1 fo = open("foo.txt", "r",encoding="UTF-8") 2 print ("文件名为: ", fo.name) 3 line = fo.readline(3) #指定读取16字节 4 print("读取指定的字符串为:%s" % (line)) 5 print("光标现在的位置:%s" %(fo.tell())) 6 fo.seek(0,0) #之所以用这个是因为前面已经读了16个字符了所以要把光标调到0 的位置 7 print("调整后光标的位置:%s" %(fo.tell())) 8 line = fo.readline() #读取第一行 9 print("读取第一行:%s" % (line)) 10 fo.close() # 关闭文件
输出:
# 文件名为: foo.txt # 读取指定的字符串为:我要学 # 光标现在的位置:9 # 调整后光标的位置:0 # 读取第一行:我要学Python0
5、readlines()
方法用于读取所有行(直到结束符 EOF)并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比sizhint较大, 因为需要填充缓冲区。如果碰到结束符 EOF 则返回空字符串。
语法:
fileObject.readlines()
例子:
1 fo = open("foo.txt", "r",encoding="UTF-8") 2 print ("文件名为: ", fo.name) 3 line = fo.readlines(3) #指定读取3字节 4 print("读取指定的字符串为:%s" % (line)) 5 for line in fo.readlines(): 6 line = line.strip(" ") #使用strip去掉换行符/n 7 print("读取所有行:%s" % (line)) 8 fo.close() # 关闭文件
输出:
文件名为: foo.txt 读取指定的字符串为:['我要学Python0 '] 读取所有行:我要学Python1 读取所有行:我要学Python2 读取所有行:我要学Python3 读取所有行:我要学Python4 读取所有行:我要学Python5 读取所有行:我要学Python6 读取所有行:我要学Python7
6、truncate()
方法用于截断文件,如果指定了可选参数 size,则表示截断文件为 size 个字符。 如果没有指定 size,则重置到当前位置。
语法:
fileObject.truncate( [ size ])
例子1:
1 fo = open("foo.txt", "r+",encoding="UTF-8") 2 line = fo.readline() 3 print ("读取行: %s" % (line)) 4 5 fo.truncate() 6 line = fo.readlines() 7 print ("读取行: %s" % (line)) 8 fo.close() # 关闭文件
输出:
读取行: 我要学Python1 读取行: ['我要学Python2 ', '我要学Python3 ', '我要学Python4']
例子2:
1 fo = open("foo.txt", "r+",encoding="UTF-8") 2 fo.truncate(10) #截取10个字符,其余的清空 3 line = fo.read() 4 print ("读取的数据: %s" % (line)) 5 fo.close() # 关闭文件
输出:
读取的数据: 我要学P
7、writelines()
方法用于向文件中写入一序列的字符串,这一序列字符串可以是由迭代对象产生的,如一个字符串列表,换行需要制定换行符 。
语法
writelines() 方法语法如下:
fileObject.writelines( [ str ])
例子:
1 fo = open("foo.txt", "a+",encoding="UTF-8") 2 seq = ["我要学Python 1 ", "我要学Python 2"] 3 fo.writelines( seq ) 4 fo.flush() 5 fo.seek(0,0) #跳到行首 6 line = fo.readlines() #读取所有行 7 print ("读取的数据: %s" % (line)) 8 fo.close() # 关闭文件
输出:
读取的数据: ['我要学Python 1 ', '我要学Python 2']
三元运算
转载;https://www.cnblogs.com/hhfzj/p/6978092.html