Spark-shell 参数
-
Spark-shell 是以一种交互式命令行方式将Spark应用程序跑在指定模式上,也可以通过Spark-submit提交指定运用程序,Spark-shell 底层调用的是Spark-submit,二者的使用参数一致的,通过- -help 查看参数:
- -master: 指定运行模式,spark://host:port, mesos://host:port, yarn, or local[n].
- -deploy-mode: 指定将driver端运行在client 还是在cluster.
- -class: 指定运行程序main方法类名,一般是应用程序的包名+类名
- -name: 运用程序名称
- -jars: 需要在driver端和executor端运行的jar,如mysql驱动包
- -packages: maven管理的项目坐标GAV,多个以逗号分隔
- -conf: 以key=value的形式传入sparkconf参数,所传入的参数必须是以spark.开头
- -properties-file: 指定新的conf文件,默认使用spark-default.conf
- -driver-memory: 指定driver端运行内存,默认1G
- -driver-cores:指定driver端cpu数量,默认1,仅在Standalone和Yarn的cluster模式下
- -executor-memory:指定executor端的内存,默认1G
- -total-executor-cores:所有executor使用的cores
- -executor-cores: 每个executor使用的cores
- -driver-class-path: driver端的classpath
- -executor-class-path: executor端的classpath
- --num-executors 10:executor数量
-
sparkconf的传入有三种方式:
- 1.通过在spark应用程序开发的时候用set()方法进行指定
- 2.通过在spark应用程序提交的时候用过以上参数指定,一般使用此种方式,因为使用较为灵活
- 3.通过配置spark-default.conf,spark-env.sh文件进行指定,此种方式较shell方式级别低
一、Local
Local 模式是最简单的一种Spark运行方式,它采用单节点多线程(cpu)方式运行,local模式是一种OOTB(开箱即用)的方式,只需要在spark-env.sh导出JAVA_HOME。
不用启动Spark的Master、Worker守护进程,也不用启动Hadoop的各服务(除非你要用到HDFS),无需其他任何配置即可使用,因而常用于开发和学习。
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master local[8] /path/to/examples.jar 100
注:local[8]:代表线程数。
二、Standalone
Spark独立群集模式。Spark可以通过部署与Yarn的架构类似的框架来提供自己的集群模式,该集群模式的架构设计与HDFS和Yarn大相径庭。
该模式需要在每个机器上部署spark,然后启动spark集群,分为master和worker节点。不用启动Hadoop服务(除非你用到了HDFS的内容)。
这种运行模式,可以使用Spark的 http://spark1:8080 来观察资源和应用程序的执行情况。
配置
通过配置spark-env.sh和slaves文件来部署,可以通过以下配置:
vi conf/spark-env.sh SPARK_MASTER_HOST=192.168.137.200 ##配置Master节点 SPARK_WORKER_CORES=2 ##配置应用程序允许使用的核数(默认是所有的core) SPARK_WORKER_MEMORY=2g ##配置应用程序允许使用的内存(默认是1G)
vi conf/slaves 192.168.137.200 192.168.137.201 192.168.137.202
启动集群:
sbin/start-all.sh
Web UI:
192.168.137.200:8080
on Standalone的俩种模式
1、Standalone的俩种模式:一种为 client,一种为 cluster,可以通过 --deploy-mode 进行指定。
-
client
以客户端模式在Spark独立群集上运行:
# Run on a Spark standalone cluster in client deploy mode ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://207.184.161.138:7077
--deploy-mode client
--executor-memory 20G
--total-executor-cores 100
/path/to/examples.jar
1000
产生的进程:
①. Master进程做为cluster manager,用来对应用程序申请的资源进行管理
②. SparkSubmit 做为Client端和运行driver程序
③. CoarseGrainedExecutorBackend 用来并发执行应用程序
-
cluster
以集群模式在Spark独立群集上运行,并使用supervisor:
# Run on a Spark standalone cluster in cluster deploy mode with supervise ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master spark://207.184.161.138:7077 --deploy-mode cluster --supervise --executor-memory 20G --total-executor-cores 100 /path/to/examples.jar 1000
2、Standalone俩种模式的区别:
①. 客户端的SparkSubmit进程会在应用程序提交给集群之后就退出
②. Master会在集群中选择一个Worker进程生成一个子进程DriverWrapper来启动driver程序
③. 而该DriverWrapper 进程会占用Worker进程的一个core,所以同样的资源下配置下,会比第3种运行模式,少用1个core来参与计算
④. 应用程序的结果,会在执行driver程序的节点的stdout中输出,而不是打印在屏幕上
三、Yarn
现在越来越多的场景,都是Spark跑在Hadoop集群中,建议在生产上使用该模式,统一使用YARN对整个集群作业(MR/Spark)的资源均衡调度。
Spark 通过客户端,负责提交作业到yarn上运行(首先需要启动Yarn集群)。这个不需要Spark集群(只需要在Hadoop分布式集群中任选一个节点安装配置Spark即可),
但要启动Hadoop的各种服务,这里包括 YARN 和 HDFS 都需要启动,因为在计算过程中 Spark 会使用 HDFS 存储临时文件,如果 HDFS 没有启动,则会抛出异常。
将Spark应用程序跑在Yarn集群之上,通过Yarn资源调度将executor启动在container中,从而完成driver端分发给executor的各个任务。
这种运行模式,可以使用Yarn的 http://hadoop001:8088/cluster 来观察资源和应用程序的执行情况。
配置
提交作业之前需要将HADOOP_CONF_DIR或YARN_CONF_DIR配置到spark-env.sh中:
vi conf/spark-env.sh HADOOP_CONF_DIR=/opt/software/hadoop-2.6.0-cdh5.7.0/etc/hadoop
on Yarn的俩种模式
1、Yarn的俩种模式:一种为 client,一种为 cluster,可以通过 --deploy-mode 进行指定。
-
client
- Driver运行在Client端;
- Client请求Container完成作业调度执行,Client不能退出;
- 日志在Client控制台输出,方便查看;
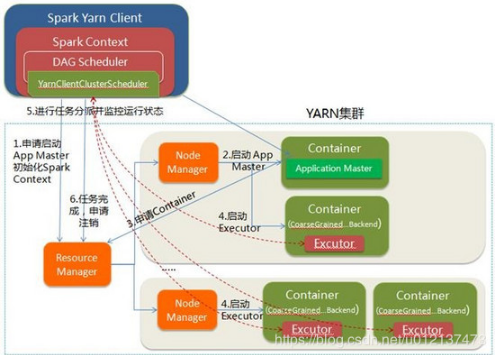
以客户端模式在Yarn集群上运行:
export HADOOP_CONF_DIR=XXX ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client
--executor-memory 20G --num-executors 50 /path/to/examples.jar 1000
产生的进程:
①. 在Resource Manager节点上提交应用程序,会生成SparkSubmit进程,该进程会执行driver程序。
②. RM会在集群中的某个NodeManager上,启动一个ExecutorLauncher进程,来做为ApplicationMaster。
③. RM也会在多个NodeManager上生成CoarseGrainedExecutorBackend进程来并发的执行应用程序。
-
cluster
- 在Resource Manager端提交应用程序,会生成SparkSubmit进程,该进程只用来做Client端,应用程序提交给集群后,就会删除该进程(就可以关掉?)
- Resource Manager在集群中的某个NodeManager上运行ApplicationMaster,该AM同时会执行driver程序。紧接着,会在各NodeManager上运行CoarseGrainedExecutorBackend来并发执行应用程序
- 应用程序的结果,会在执行driver程序(即ApplicationMaster)的节点的stdout中输出,也可通过 yarn logs -applicationId <application_id> 查看

以集群模式在Yarn集群上运行:
export HADOOP_CONF_DIR=XXX ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster
--executor-memory 20G --num-executors 50 /path/to/examples.jar 1000
2、Yarn俩种模式的区别:
①. 在于driver端启动在本地(client),还是在Yarn集群内部的AM中(cluster)。
②. client提交作业的进程是不能停止的,否则作业就挂了;cluster提交作业后就断开了,因为driver运行在AM中。
③. client提交的作业,日志在客户端看不到,因为作业运行在yarn上,可以通过 yarn logs -applicationId <application_id> 查看。
④. Cluster适合生产环境,Client适合交互和调试。
四、Mesos
# Run on a Mesos cluster in cluster deploy mode with supervise ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master mesos://207.184.161.138:7077 --deploy-mode cluster --supervise --executor-memory 20G --total-executor-cores 100 http://path/to/examples.jar 1000
具体参见:http://spark.apache.org/docs/latest/running-on-mesos.html
五、Kuberneters
# Run on a Kubernetes cluster in cluster deploy mode ./bin/spark-submit --class org.apache.spark.examples.SparkPi --master k8s://xx.yy.zz.ww:443 --deploy-mode cluster --executor-memory 20G --num-executors 50 http://path/to/examples.jar 1000
具体参见:http://spark.apache.org/docs/latest/running-on-kubernetes.html
六、总结
这几种分布式部署方式各有利弊,通常需要根据实际情况决定采用哪种方案。进行方案选择时,往往要考虑公司的技术路线(采用Hadoop生态系统还是其他生态系统)、相关技术人才储备等。
- 如果你只是测试Spark Application,你可以选择Local模式。
- 如果你数据量不是很多,属于小规模计算集群,Standalone 是个不错的选择。
- 当你需要统一管理集群资源(Hadoop、Spark等),那么你可以选择Yarn或者Mesos,但是这样维护成本就会变高。
引用: