B站弹幕爬取
单个视频弹幕的爬取
B站弹幕都是以xml文件的形式存在的,而xml文件的请求地址是如下形式:
http://comment.bilibili.com/233182992.xml
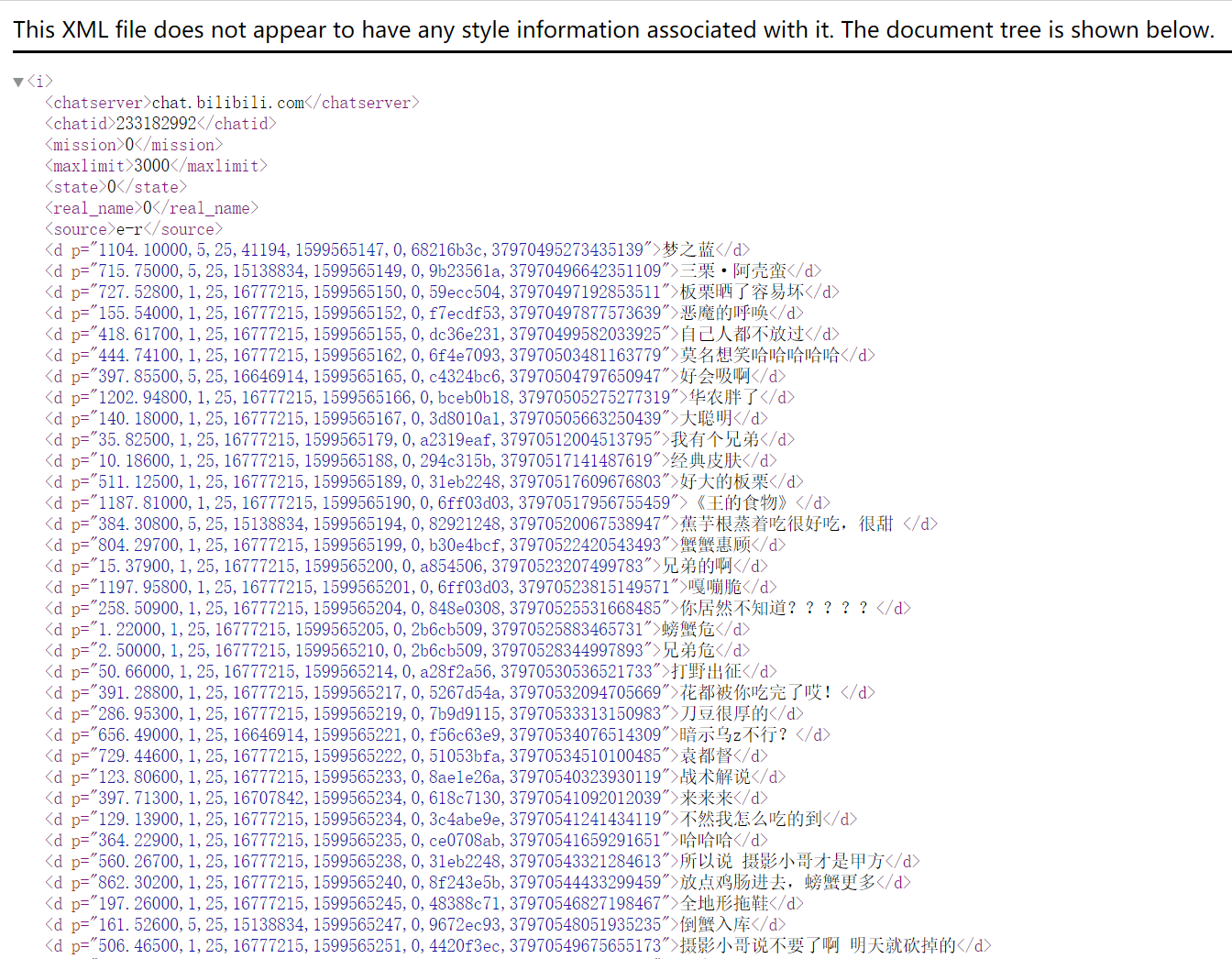
其中,233182992是cid,这个需要从原视频的网页中获取。获取了cid之后,就可以按照上述的形式拼接请求地址,发送get请求,获取对应的xml文件。
cid获取
以华农兄弟的某个视频为例,进入视频主页。
- 右键启用检查模式
- 选择网络(Network),刷新网页
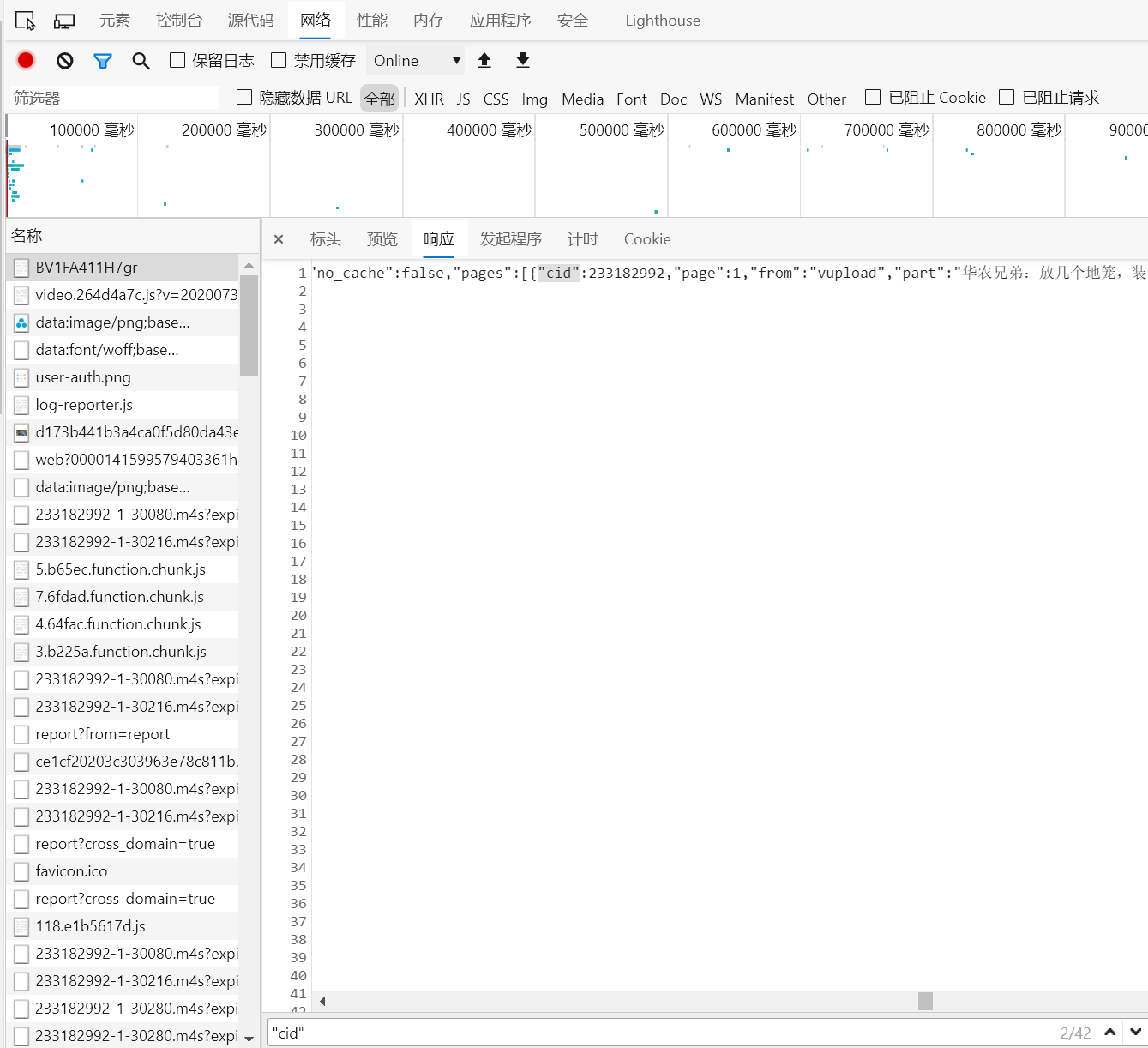
- 点开第一个文件,选择响应(response)
- 使用CTRL + F进行字段查找,输入"cid:",发现匹配到的第一个cid就是视频的cid
接下来,就是如何从视频主页返回的网页信息中提取cid。
- 确定视频的bv号
- 根据bv号确定请求地址
- 使用正则表达式从网页返回的文本中匹配cid
- 根据拿到的cid请求获取xml文件
xml文件解析
获取到xml文件之后,需要从xml文件中提取出弹幕文本。调用lxml库中的etree类,etree.HTML()可以用来解析字符串格式的HTML文档对象,将传进去的字符串转变成Element对象。作为Element对象,可以方便的使用getparent()、remove()、xpath()等方法。这里使用xpath来提取需要的那部分弹幕文本。
爬虫封装
完整代码如下:
import requests
import re
from lxml import etree
class BiliBiliDanMu:
def __init__(self, bv, filename):
# 根据bv号构造要爬取的视频url地址
self.video_url = "https://bilibili.com/video/BV" + bv
self.filename = filename
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36 Edg/85.0.564.44"
}
# 获取视频的cid
def get_video_cid(self):
response = requests.get(self.video_url, headers=self.headers)
html = response.content.decode()
cid = re.findall(r'("cid":)([0-9]+)', html)
# 有的视频没有这个字段,我们跳过它
if len(cid) == 0:
return None
else:
return cid[0][-1]
# 获取请求弹幕xml文件返回的内容
def get_content(self, xml_url):
response = requests.get(xml_url, headers=self.headers)
return response.content
# 解析获取到的内容,得到包含视频所有弹幕的列表
def extract_danmu(self, content_str):
html = etree.HTML(content_str)
danmu_list = html.xpath("//d/text()")
return danmu_list
# 将弹幕逐行写入并保存为txt文件
def save(self, save_items):
with open(self.filename, 'w', encoding='utf-8') as f:
lines = []
for item in save_items:
lines.append(item + '
')
f.writelines(lines)
# 爬虫的过程封装
def crawl(self):
cid = self.get_video_cid()
# 跳过没有cid字段的视频
if cid is not None:
xml_url = "http://comment.bilibili.com/" + str(cid) + ".xml"
content_str = self.get_content(xml_url)
danmu_lst = self.extract_danmu(content_str)
self.save(danmu_lst)
else:
pass
if __name__ == '__main__':
bv = input("请输入视频的bv号: ")
dm = BiliBiliDanMu(bv, './output/{}.txt'.format(str(bv)))
dm.crawl()
up主所有视频的弹幕爬取
仍然以华农兄弟的视频为例,进入华农兄弟的个人空间的视频页,地址如下:
https://space.bilibili.com/250858633/video
视频页数和up名字获取
仍然启用网页检查,来看我们需要的信息究竟该如何请求。
首先,选中网络中的XHR选项,刷新页面,点击出现的search文件,点击响应,左键连击3次,选中响应返回的全部数据,其实,这里返回的就是一个json文件。
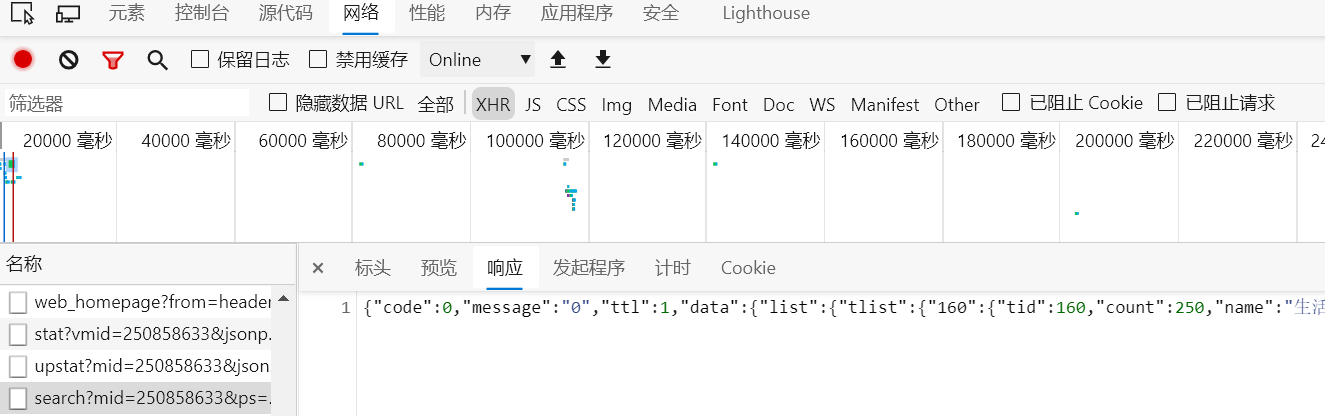
我们使用一个在线工具来看看这个json文件的结构:json工具

从这个结构里可以看到,tlist字段下包含了三类视频的类型id及数目(count字段)。而视频页的最大固定展示数目为30,因此,我们通过一个简单的计算就可以得到up主视频的总页数。由页数,也就能确定循环请求的次数。请求的url地址如下:

https://api.bilibili.com/x/space/arc/search?mid=250858633&ps=30&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp
其中,mid为up主的id号,pn为视频页号。
视频bv号批量获取
从上述方式获取到的json文件中,我们可以不仅可以推断视频页的总页数,还能获取到当前页所有视频的BV号以及作者信息,根据BV号就能使用前面获取单个视频弹幕的代码来逐一获取当前页号下所有视频的弹幕了。

爬虫封装
完整代码如下:
import requests
import json
import re
import os
from bilibili_danmu import BiliBiliDanMu
uper_name = None
# 获取某个up主的全部视频的弹幕
class AllBv:
def __init__(self, up_id):
self.up_id = up_id
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36 Edg/85.0.564.44"
}
# 获取视频总页数
def get_pages_num(self):
url = 'https://api.bilibili.com/x/space/arc/search?mid={}
&ps=30&tid=0&pn=1&keyword=&order=pubdate&jsonp=jsonp'.format(self.up_id)
response = requests.get(url=url, headers=self.headers)
json_dict = json.loads(response.content.decode())
video_dict = json_dict['data']['list']['tlist']
total_videos = 0
global uper_name
for _, v in video_dict.items():
total_videos += v['count']
for comment in json_dict['data']['list']['vlist']:
if str(comment['mid']) == self.up_id:
uper_name = comment['author']
else:
continue
# 每页最多30个视频
return uper_name, int(total_videos / 30 + 1)
# 获取返回的json
def get_pages_json(self, total_pages):
json_dict_lst = []
for i in range(1, total_pages + 1):
url = 'https://api.bilibili.com/x/space/arc/search?mid={}&ps=30&tid=0&pn={}
&keyword=&order=pubdate&jsonp=jsonp'.format(str(self.up_id), str(i))
response = requests.get(url=url, headers=self.headers)
json_dict_lst.append(json.loads(response.content.decode()))
return json_dict_lst
# 从json文件中获取bv号列表
def get_bv_from_json(self, json_dict):
v_lst = json_dict['data']['list']['vlist']
bv_lst = []
for item in v_lst:
bv_lst.append(item['bvid'][2:])
return bv_lst
# 将得到的bv号列表存到一个txt文件中,文件夹名字以up主名字命名
def save_bv_lst(self, bv_lst, au_name):
folder = au_name
if not os.path.exists(folder):
os.mkdir(folder)
with open(au_name + '/bv_lst.txt', 'a', encoding='utf-8') as f:
lines = []
for bv_id in bv_lst:
lines.append(bv_id + '
')
f.writelines(lines)
# 封装爬取过程,返回up主的名字和所有视频的bv号列表
def crawl(self):
up_name, pages_total = self.get_pages_num()
bv_video_lst = []
json_dict_lst = self.get_pages_json(pages_total)
for json_file in json_dict_lst:
bv_lst = self.get_bv_from_json(json_file)
bv_video_lst = bv_video_lst + bv_lst
self.save_bv_lst(bv_lst, './{}'.format(up_name))
return up_name, bv_video_lst
if __name__ == '__main__':
up_id = input("please input up_id: ")
# 实例化
abm = AllBv(up_id)
author_name, bv_video_list = abm.crawl()
# 借助单独一个bv视频弹幕爬取的类BiliBiliDanMu进行弹幕的爬取
for bv in bv_video_list:
bm = BiliBiliDanMu(bv, './{}/{}.txt'.format(author_name, str(bv)))
bm.crawl()
制作词云
from wordcloud import WordCloud
import jieba
import numpy as np
# 1:打开词云文本
txt = open('./a.txt', 'r', encoding='utf-8').read()
# 2:用jieba进行分词
txt_cut = "".join(jieba.cut(txt, cut_all=False) )
# 3:设置词云的属性
font = "C:\Windows\Fonts\simkai.TTF" # 词云的中文字体所在路径,不设置字体的话,很可能出现乱码
wc = WordCloud(font_path=font,
background_color="white",
height=800,
width=1000
)
# 4:生成词云
wc.generate(txt_cut)
# 5:存储词云
wc.to_file("./demo.png")
效果图如下:
