基于多知识库迭代检索的问答系统

背景
常识问答任务需要引入外部知识来帮助模型更好地理解自然语言问题,现有的解决方案大都采用两阶段框架:
- 第一阶段 —— 从广泛的知识来源中找到与给定问题相关的知识事实或者用预训练模型生成相关的知识
- 第二阶段 —— 将找到的或者生成的知识与问题融合以预测答案。
实验结果证明,外部知识融合到问答系统的做法是十分有效的,但这仍然存在一个关键的问题:就从单一外部知识库找寻相关知识而言,抽取到的部分知识可能对解决问题基本毫无作用,甚至还可能损害模型的性能。例如,以下面一个QA为例,对于问题实体(farmland)和三个选项实体(midwest space countryside space illinois),从ConceptNet中抽取到的知识显示,(farmland)和三个选项实体都直接相关((AtLocation))。

虽然外部知识给到了模型,但模型仍然很难做出正确的选择,因为这三个选项看上去似乎都是正确的。这样的问题在论文中被称为知识的多价值属性,这种问题在问答系统中十分常见,实体关系的多值属性会损害现有模型的性能。
贡献
提出一种新的多知识源问答方法,通过利用多种知识来源,在所需的背景知识和原始问题以及选择之间建立精确的联系,以解决多值属性带来的挑战。
三个创新:
- 提出基于图的迭代检索模块 —— 通过问题中实体之间的隐藏关系来缩小和细化潜在的有用知识事实
- 引入词典为实体或者概念提供解释 —— 综合实体或概念解释和迭代检索的知识事实可以帮助模型精确区分欺骗性的答案选择
- 提出答案选择感知注意力机制 —— 在将隐层状态向量输入最终预测的线性分类器之前,引入答案选择感知注意机制来计算给定问题、检索的知识和候选选择的各自的隐层向量之间的注意力分数
框架
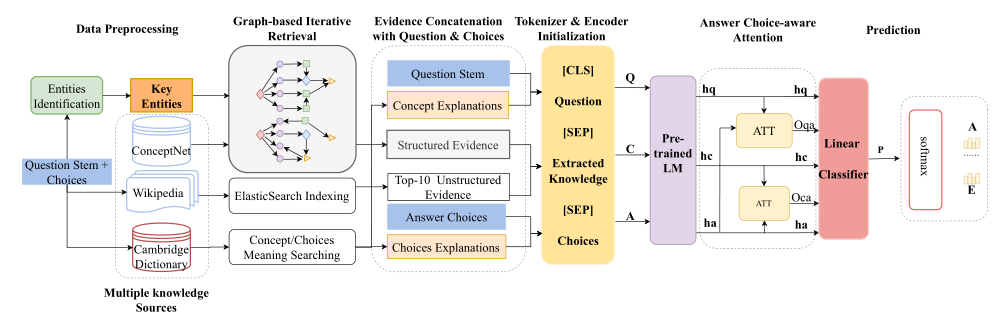
仍然采用两阶段的框架(默认已经进行了对QA对的实体识别):
-
第一阶段 —— 从多个外部知识库中抽取与QA对相关的知识,这部分大多是在检索知识
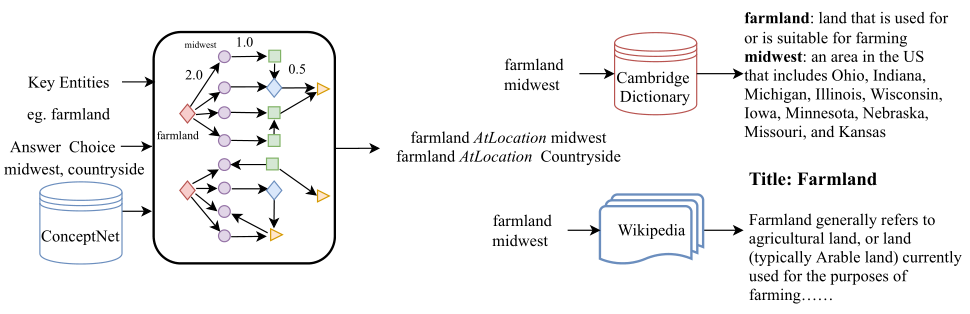
- 结构化证据 —— 从ConceptNet中找到问题概念和识别的关键实体(包含选项实体),并把它们作为初始节点。根据问题的类型,使用基于规则的方法推断可能的关系,并使用这些关系来缩小知识提取的范围。基于初始节点和潜在关系,迭代地检索与问题相关的知识事实。
- 非结构化证据 —— 将维基百科文档拆分成句子,使用ElasticSearch构建索引。根据原问题检索相关句子,使用标题和段落缩小文档的范围。然后使用段落级候选词和它们的句子来建立索引,并检索前10个相关的句子
- 实体或概念解释 —— 从字典中提取答案选择和问题概念的含义,帮助模型区分分散注意力的实体
-
第二阶段 —— 用预训练模型对构造的输入进行编码,将编码后的三个隐层向量通过一个答案选择感知注意力计算注意力得分,最终输入到分类器中得到QA对的得分。
- 输入构造 —— ([CLS] space Question space [SEP] space Extracted space Knowledge space [SEP] space Choices)
- 答案选择感知注意力机制 —— 主要是计算QA对各自隐层向量的注意力系数以及证据和选项各自隐层向量的注意力系数,最后串接加权后的问题隐层向量(O_{qa}h_{q})和加权后的证据隐层向量(O_{ca}h_{c})以及选项隐层向量(h_{a})
多源知识库
结构化的ConceptNet、非结构化的Wikipedia以及剑桥词典(Cambridge Dictionary)。
- ConceptNet —— 最大的结构化知识库之一,知识主要来自其他众包资源、专家创造的资源
- Wikipedia —— 一个免费的在线百科全书,由世界各地的志愿者创建和编辑,论文中选用最新的Wikipedia 22-May-2020版本
- Cambridge Dictionary —— 1995年出版,囊括超140k单词、短语及解释。
文本编码
在从多个知识源中检索与问题相关的知识事实后,使用([SEP])来分割证据知识、原始问题和候选答案。
具体做法:
- 将原始答案选择与来自剑桥词典的答案解释连接起来作为(A= left{ a_{1},a_{2},dots,a_{n} ight})
- 将来自维基百科和概念网的证据连接起来作为上下文(C=left{c_{1}, c_{2}, ldots, c_{k} ight})
- 将来自剑桥词典的概念解释与问题词干连接起来作为(Q=left{q_{1}, q_{2}, ldots, q_{m} ight})
从形式上来看,预先训练的语言模型的输入是问题Q、相关证据C和答案选择A的连接:
答案选择感知注意力机制
通常在从RoBERTa模型中获得最后的隐藏状态向量后,对于下游任务中的问题回答,以往的模型方案是通常直接使用线性分类器来预测答案。
然而,在论文的实验过程中,观察到线性分类器在检索到的证据或背景知识上表现不佳。因此,论文引入了一种答案选择感知的注意机制来计算问题(h_{q})和选择之间的注意分数,并且通过标准的注意计算来计算检索到的证据(h_{c})和答案选择(h_{a})之间的注意分数。
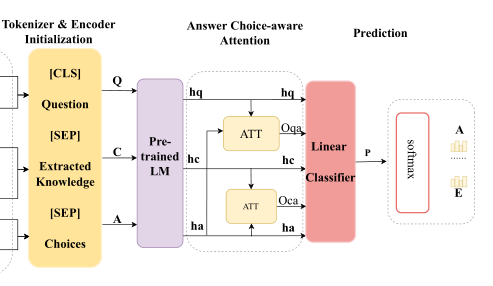
最后,将注意力重新加权的隐藏状态连接起来,通过线性分类器与ReLU进行传递,以计算最终的双向注意力向量进行预测。公式如下:
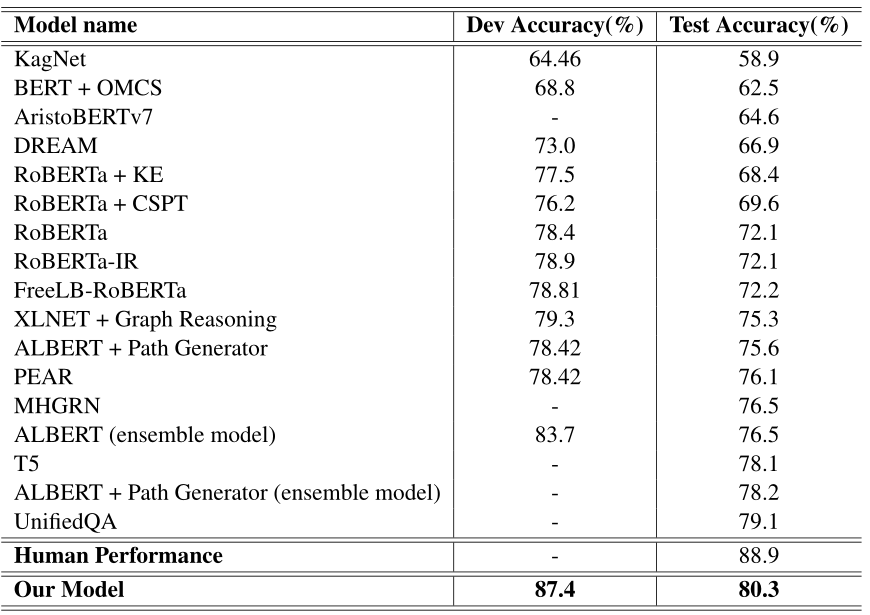
实验结果
- pretrained model —— RoBERTa-large(24-layers)
- max update step —— 6000
- warmup update step —— 150
- max length —— 512
- dropout —— 0.1
- optimizer —— Adam
- loss function —— cross-entropy loss
- batch size —— 4
- learning rate —— 1e-5
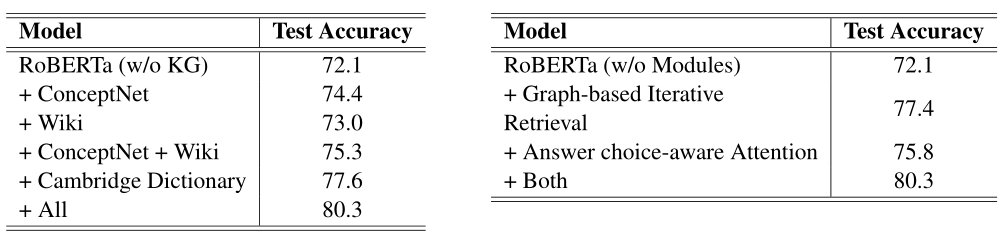
创新有效性研究
左图是对使用多元知识库有效性的研究,可以看到证据来源的知识库越多,模型的表现越好。单知识库来源下,模型表现:剑桥字典 > ConceptNet > Wikipedia。
右图是对图的迭代知识检索以及QA感知注意力机制有效性的研究,实验证明,这两处创新皆能提升模型表现。
结论
处理多项选择题回答任务,需要额外的背景知识或常识。通过有效地整合多种知识资源,提出了一种基于图迭代检索的新的常识问答系统。首先,论文提出一个新的基于图的迭代知识检索模块来迭代检索与给定问题及其选择相关的概念和实体。此外,论文还提出了一种答案选择感知的注意机制,用于融合由预先训练的语言模型编码的所有隐藏层的状态表示。论文作者在CommonsenseQA数据集上进行了实验,实验结果表明,该方法在CommonsenseQA测试集上的准确率上明显优于其他模型。最后,论文进行了对创新的有效性研究,研究结果显示了基于图的迭代知识检索模块和答案选择感知注意模块在从多个知识源检索和合成背景知识方面的有效性。