From:http://m.csdn.net/article_pt.html?arcid=2823943
Apache HBase是一个面向线上服务的数据库,其原生支持Hadoop的特性,使其成为那些基于Hadoop的扩展性和灵活性进行数据处理的应用显而易见的选择。
在Hortonworks数据平台(HDP http://zh.hortonworks.com/hdp/) 2.2中,HBase的高可用性得到了长足的发展,能够保证其上运行应用的正常运行时间达到99.99%。
本文将回顾过去12个月的开发历程,展示开发人员如何改进HBase的高可用性,并讨论未来的改进计划。
HBase高可用性的历史观点
高可用性(HA)是任何数据库的关键特性,也是任何核心业务应用的先决条件。
以前,HBase使用两种策略来保障数据的可用性:
第一,HBase将数据自动分区,并将各个分区发布到不同的节点上去。某个节点下线或宕机只会影响该节点上的数据,其他节点上的数据不会受到影响。
第二,所有存储在HBase上的数据实际上都被存储在HDFS上,数据被备份成3份,分布在不同的节点上,并且集群中任何节点都可以使用这些数据。
这使得HBase可以自动将失败节点上托管的数据重新分配给正常的节点,从而保证了数据的高可用性。
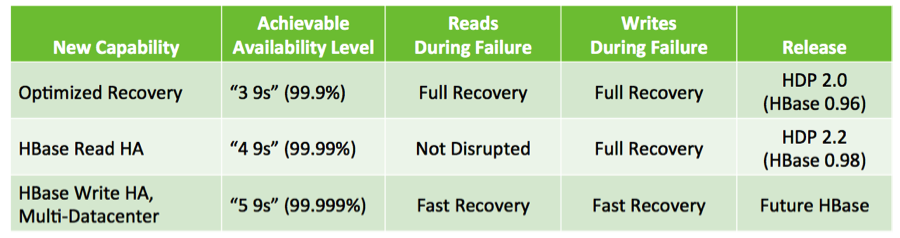
如果综合利用这些固有的HA特性,并结合Hadoop最佳实践,使得基于HBase应用的高可用性完全有可能达到99.9%,即每年总宕机时间低于9小时。
这适用于大多数应用,而对于系统核心应用来说,需要更高的可用性保障。
更好的高可用性需求
我们正处于大数据应用转向Hadoop平台再造的早期阶段。Hadoop的普及率和影响力与日俱增,已成为强调系统扩展性或者数据处理灵活性应用的不二之选。
对于那些想从Hadoop无处不在、进展迅速的创新中受益的线上应用来说,HBase作为Hadoop生态中的一员,自然成为首选的数据库。
当我们与一些希望将关键业务迁移到HBase上的客户交流时,我们经常收到如下反馈,客户需要HBase提供数据一致性,但是却无法容忍哪怕是很短的宕机恢复时间。为了使Hadoop能够支撑在线应用的关键业务,HBase的高可用性特性需要进行大幅度的改进。
Hortonworks与HBase社区通力合作,通过引入时间轴一致区域副本技术(也称HBase读高可用性,相关内容参考HBASE-10070【https://issues.apache.org/jira/browse/HBASE-10070】),极大的提高了HBase的高可用性。
从上层看,这个新的HA特性在遍布HBase集群的主区域副本和备区域副本中维持相同数据的多个备份。利用HBase读高可用性,如果一个RegionServer失败后,用户仍然可以从其他RegionServer上读取失败节点上的数据。
也就是说,在系统自动恢复期间,用户只是失去了该节点的写可用性,但仍然可以读取该节点的数据。对于那些需要持续可读并且保持读一致性的应用来说,HBase的读高可用性特性是一个理想的选择。
结合最佳实践,如使用双副本和机架感知,HBase读高可用性可以使得那些依赖HBase的关键业务应用的可用性达到99.99%。

什么是时间轴一致性?
从好的一面看,这个方式使得保证数据一致性的实现非常简单,只有一个所有者的策略意味着不会出现脑裂,不会出现最后一次写有效(last-write-wins)的情况,并且让计数器这类重要功能的实现变得快速和简单。
从不好的一面看,如果一个RegionServer宕机了,这个RegionServer持有的所有键值范围都将离线,直到数据恢复过程完成为止。
在HBase 0.96中,这个恢复过程已经优化到一分钟以内,不过,我们还是牺牲了一些可用性来保证数据的高度一致性。根据CAP理论,我们必须折中考虑一致性和可用性,并且还没有一个完美的系统,可以一直兼顾一致性和可用性。
很多现代数据库系统试图通过实现纯粹的AP模型来优化可用性,即放弃一致性以优化可用性。放弃一致性使得这类数据库的用户不得不直面分布式系统中的一些复杂的议题。很多时候,最终一致性数据库的用户更像是数据库开发人员,而不仅仅是数据库使用者。
实际上,网络分区问题并不是一直都存在,所有,没有必要为了防止偶尔发生的故障而在任何时候都牺牲一致性。如果对这方面的讨论和时间轴一致性的相关内容感兴趣,可以读一下Daniel Abadi的博客【http://dbmsmusings.blogspot.com/2010/04/problems-with-cap-and-yahoos-little.html】。
HBase的读高可用性实现了一个时间轴一致性的系统,该系统为开发人员提供在查询阶段选择使用严格的一致性策略还是宽松的一致性策略的功能。
使用HBase的读高可用性:
- 数据被一个主Region和一个或多个副本Region所持有。
- 任何一个Region(无论是主Reigon还是副本Region)都可以响应针对上述数据的读请求。
- 只有主Region可以处理写请求。
- 副本中的数据可能与主Region的数据不一致,但是,
- 所有副本都会按照完全一致的顺序收到更新请求。
从客户端来看:
- 客户端可以在每次请求中指定使用何种一致性策略,严格的(Consistency.STRONG )还是宽松的(Consistency.TIMELINE)。
- 返回的结果会显式的指出,数据是最新的(即来自主Region)还是过期的(即来自副本Region)。
客户端可以根据这个标识来进行操作。
这个模型具有如下几个优点:
- 保证写一致性:
- 在系统故障期间,数据仍然可读。使用双备份和合适的机架位置配置,HBase可以在整个机架故障的情况下,保证无停机的数据可读性。
- 时延:读一致性仍然只需要一次网络来回。
- 时延:客户端可以从所有副本随机读取数据,并采用第一个返回的响应。
时间轴一致性兼顾了强一致性和故障时优雅降级的需求,可以在不增加开发人员处理最终一致性系统复杂度的情况下,得到更高的可用性。
HBase读高可用性:阶段1/阶段2
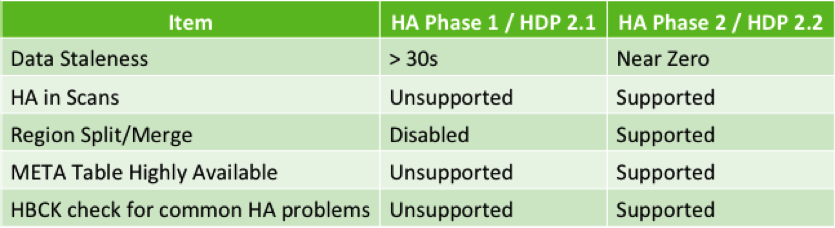
HBase读可用性的开发经历了两个阶段。第一阶段主要用于验证原型和API语义,而第二阶段提供了适合生产环境的版本。如果你关注了HDP2.1提供的HBase读高可用性,并由于其无法支持split/merge这类操作的缺陷而认为其不可用,那么,HDP2.2将针对所有你期望的HBase操作提供高可用性。
动手实践
HBase读可用性是HDP2.2平台的一个特性。如果你对提高应用的可用性比较感兴趣,那么我们建议你能够尝试一下。
HBaes高可用性展望
HBaes的高可用性在过去一年里得到了巨大的改进,不过,还有很多地方需要完善。到目前为止,HBase还未解决的两个重要问题:
- 故障时的写可用性
- 跨数据中心的读写一致性
我们非常高兴的看到HBase社区已经开始着手解决这些问题,正努力的将Facebook开发的HydraBase合并到HBase中去。未来,HBase将在保证关键业务系统对数据强一致性要求的同时,提供高达5个9(即99.999%)的可用性。
原文链接:http://zh.hortonworks.com/blog/apache-hbase-high-availability-next-level/