本文参考自:(1)李航《统计学习与方法》 (2)https://github.com/apachecn/AiLearning/blob/master/src/py2.x/ml/7.AdaBoost/adaboost.py
- 提升方法(boosting)是一种常用的统计学习方法,在分类问题中,他通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类器的性能
- 具体来说,对于提升方法来说,有两个问题需要回答:一是在每一轮如何改变训练数据的权值或概率分布;二是如何将弱分类器组合成一个强分类器。
- 关于第一个问题,AdaBoost的方法事提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类的样本的权值。这样一来,那些没有得到正确分类的数据,由于其权值的加大而受到后一轮的弱分类器更大的关注
- 对于第2个问题,即弱分类器的组合,AdaBoost采取加权多数表决的方式,具体的,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用;减小分类误差率大的弱分类器的权值,使其在表决中起较小的作用,AdaBoost的巧妙之处在于将这些想法自然且有效的实现在一种算法里
- 下图是AdaBoost的工作原理:
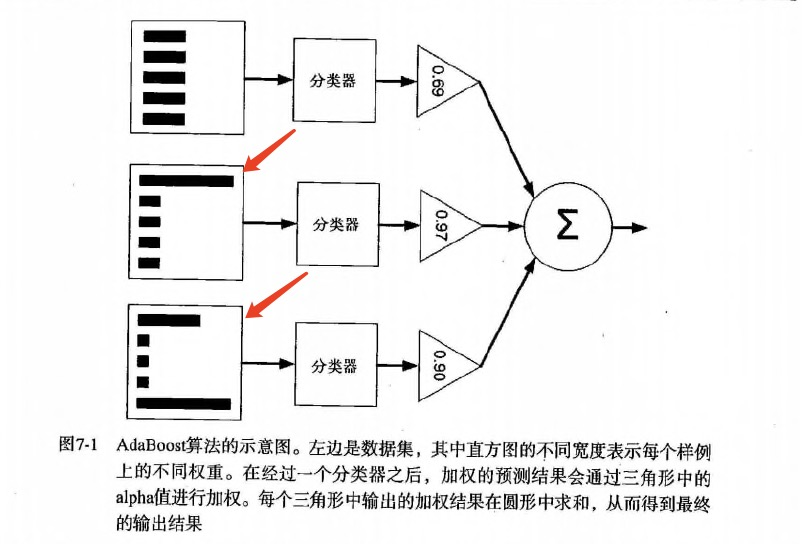




项目概述:
预测患有疝气病的马的存活问题,这里的数据包括368个样本和28个特征,疝气病是描述马胃肠痛的术语,然而,这种病并不一定源自马的胃肠问题,其他问题也可能引发疝气病,该数据集中包含了医院检测马疝气病的一些指标,有的指标比较主观,有的指标难以测量,例如马的疼痛级别。另外,除了部分指标主观和难以测量之外,该数据还存在一个问题,数据集中有30%的值是缺失的。
1.准备数据
def loadDataSet(filename):
dim = len(open(filename).readline().split(' ')) #获取每个样本的维度(包括标签)
data = []
label = []
fr = open(filename)
for line in fr.readlines(): #一行行的读取
LineArr = []
curline = line.strip().split(' ') #以tab键划分,去除掉每个的空格
for i in range(dim-1):
LineArr.append(float(curline[i]))
data.append(LineArr)
label.append(float(curline[1]))
return data,label
2. 构建弱分类器:单层决策树
def buildStump(dataArr, labelArr, D):
"""buildStump(得到决策树的模型)
Args:
dataArr 特征标签集合
labelArr 分类标签集合
D 最初的样本的所有特征权重集合
Returns:
bestStump 最优的分类器模型
minError 错误率
bestClasEst 训练后的结果集
"""
# 转换数据
dataMat = np.mat(dataArr)
labelMat = np.mat(labelArr).T
# m行 n列
m, n = np.shape(dataMat)
# 初始化数据
numSteps = 10.0
bestStump = {}
bestClasEst = np.mat(np.zeros((m, 1)))
# 初始化的最小误差为无穷大
minError = np.inf
# 循环所有的feature列,将列切分成 若干份,每一段以最左边的点作为分类节点
for i in range(n):
rangeMin = dataMat[:, i].min()
rangeMax = dataMat[:, i].max()
# print 'rangeMin=%s, rangeMax=%s' % (rangeMin, rangeMax)
# 计算每一份的元素个数
stepSize = (rangeMax-rangeMin)/numSteps
# 例如: 4=(10-1)/2 那么 1-4(-1次) 1(0次) 1+1*4(1次) 1+2*4(2次)
# 所以: 循环 -1/0/1/2
for j in range(-1, int(numSteps)+1):
# go over less than and greater than
for inequal in ['lt', 'gt']:
# 如果是-1,那么得到rangeMin-stepSize; 如果是numSteps,那么得到rangeMax
threshVal = (rangeMin + float(j) * stepSize)
# 对单层决策树进行简单分类,得到预测的分类值
predictedVals = stumpClassify(dataMat, i, threshVal, inequal)
# print predictedVals
errArr = np.mat(np.ones((m, 1)))
# 正确为0,错误为1
errArr[predictedVals == labelMat] = 0
# 计算 平均每个特征的概率0.2*错误概率的总和为多少,就知道错误率多高
# 例如: 一个都没错,那么错误率= 0.2*0=0 , 5个都错,那么错误率= 0.2*5=1, 只错3个,那么错误率= 0.2*3=0.6
weightedError = D.T*errArr
'''
dim 表示 feature列
threshVal 表示树的分界值
inequal 表示计算树左右颠倒的错误率的情况
weightedError 表示整体结果的错误率
bestClasEst 预测的最优结果
'''
# print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
# bestStump 表示分类器的结果,在第几个列上,用大于/小于比较,阈值是多少
return bestStump, minError, bestClasEst
def stumpClassify(dataMat, dimen, threshVal, threshIneq):
"""stumpClassify(将数据集,按照feature列的value进行 二分法切分比较来赋值分类)
Args:
dataMat Matrix数据集
dimen 特征列
threshVal 特征列要比较的值
Returns:
retArray 结果集
"""
# 默认都是1
retArray = np.ones((np.shape(dataMat)[0], 1))
# dataMat[:, dimen] 表示数据集中第dimen列的所有值
# threshIneq == 'lt'表示修改左边的值,gt表示修改右边的值
# print '-----', threshIneq, dataMat[:, dimen], threshVal
if threshIneq == 'lt':
retArray[dataMat[:, dimen] <= threshVal] = -1.0
else:
retArray[dataMat[:, dimen] > threshVal] = -1.0
return retArray
3. AdaBoost算法实现
def adaBoostTrainDS(dataArr, labelArr, numIt=40):
"""
Args:
dataArr 特征标签集合
labelArr 分类标签集合
numIt 实例数
Returns:
weakClassArr 弱分类器的集合
aggClassEst 预测的分类结果值
"""
weakClassArr = []
m = np.shape(dataArr)[0] #样本的个数
# 初始化 D,设置每个样本的权重值,平均分为m份
W = np.mat(np.ones((m, 1))/m)
aggClassEst = np.mat(np.zeros((m, 1)))
for i in range(numIt):
# 得到决策树的模型
bestStump, error, classEst = buildStump(dataArr, labelArr, W)
# alpha目的主要是计算每一个分类器实例的权重(组合就是分类结果)
# 计算每个分类器的alpha权重值
alpha = float(0.5*np.log((1.0-error)/max(error, 1e-16)))
bestStump['alpha'] = alpha
# store Stump Params in Array
weakClassArr.append(bestStump)
print("alpha=%s, classEst=%s, bestStump=%s, error=%s "% (alpha, classEst.T, bestStump, error))
# 分类正确:乘积为1,不会影响结果,-1主要是下面求e的-alpha次方
# 分类错误:乘积为 -1,结果会受影响,所以也乘以 -1
expon = np.multiply(-1*alpha*np.mat(labelArr).T, classEst)
print('(-1取反)预测值expon=', expon.T)
# 计算e的expon次方,然后计算得到一个综合的概率的值
# 结果发现: 判断错误的样本,D中相对应的样本权重值会变大。
W = np.multiply(W, np.exp(expon))
W = W/W.sum()
# 预测的分类结果值,在上一轮结果的基础上,进行加和操作
print('当前的分类结果:', alpha*classEst.T)
aggClassEst += alpha*classEst
print("叠加后的分类结果aggClassEst: ", aggClassEst.T)
# sign 判断正为1, 0为0, 负为-1,通过最终加和的权重值,判断符号。
# 结果为:错误的样本标签集合,因为是 !=,那么结果就是0 正, 1 负
aggErrors = np.multiply(np.sign(aggClassEst) != np.mat(labelArr).T, np.ones((m, 1)))
errorRate = aggErrors.sum()/m
# print "total error=%s " % (errorRate)
if errorRate == 0.0:
break
return weakClassArr, aggClassEst
4. 分类准确率的计算
def adaClassify(datToClass, classifierArr):
# do stuff similar to last aggClassEst in adaBoostTrainDS
dataMat = np.mat(datToClass)
m = np.shape(dataMat)[0]
aggClassEst = np.mat(np.zeros((m, 1)))
# 循环 多个分类器
for i in range(len(classifierArr)):
# 前提: 我们已经知道了最佳的分类器的实例
# 通过分类器来核算每一次的分类结果,然后通过alpha*每一次的结果 得到最后的权重加和的值。
classEst = stumpClassify(dataMat, classifierArr[i]['dim'], classifierArr[i]['thresh'], classifierArr[i]['ineq'])
aggClassEst += classifierArr[i]['alpha']*classEst
# print aggClassEst
return np.sign(aggClassEst)
5. 绘制ROC曲线
def plotROC(predStrengths, classLabels):
"""plotROC(打印ROC曲线,并计算AUC的面积大小)
Args:
predStrengths 最终预测结果的权重值
classLabels 原始数据的分类结果集
"""
print('predStrengths=', predStrengths)
print('classLabels=', classLabels)
# variable to calculate AUC
ySum = 0.0
# 对正样本的进行求和
numPosClas = sum(np.array(classLabels)==1.0)
# 正样本的概率
yStep = 1/float(numPosClas)
# 负样本的概率
xStep = 1/float(len(classLabels)-numPosClas)
# argsort函数返回的是数组值从小到大的索引值
# get sorted index, it's reverse
sortedIndicies = predStrengths.argsort()
# 测试结果是否是从小到大排列
print('sortedIndicies=', sortedIndicies, predStrengths[0, 176], predStrengths.min(), predStrengths[0, 293], predStrengths.max())
# 开始创建模版对象
fig = plt.figure()
fig.clf()
ax = plt.subplot(111)
# cursor光标值
cur = (1.0, 1.0)
# loop through all the values, drawing a line segment at each point
for index in sortedIndicies.tolist()[0]:
if classLabels[index] == 1.0:
delX = 0
delY = yStep
else:
delX = xStep
delY = 0
ySum += cur[1]
# draw line from cur to (cur[0]-delX, cur[1]-delY)
# 画点连线 (x1, x2, y1, y2)
print(cur[0], cur[0]-delX, cur[1], cur[1]-delY)
ax.plot([cur[0], cur[0]-delX], [cur[1], cur[1]-delY], c='b')
cur = (cur[0]-delX, cur[1]-delY)
# 画对角的虚线线
ax.plot([0, 1], [0, 1], 'b--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve for AdaBoost horse colic detection system')
# 设置画图的范围区间 (x1, x2, y1, y2)
ax.axis([0, 1, 0, 1])
plt.show()
'''
参考说明:http://blog.csdn.net/wenyusuran/article/details/39056013
为了计算 AUC ,我们需要对多个小矩形的面积进行累加。
这些小矩形的宽度是xStep,因此可以先对所有矩形的高度进行累加,最后再乘以xStep得到其总面积。
所有高度的和(ySum)随着x轴的每次移动而渐次增加。
'''
print("the Area Under the Curve is: ", ySum*xStep)
6. 主函数
if __name__ == "__main__":
# 马疝病数据集
# 训练集合
dataArr, labelArr = loadDataSet("./data/horseColicTraining.txt")
weakClassArr, aggClassEst = adaBoostTrainDS(dataArr, labelArr, 40)
print(weakClassArr, '
-----
', aggClassEst.T)
# 计算ROC下面的AUC的面积大小
plotROC(aggClassEst.T, labelArr)
# 测试集合
dataArrTest, labelArrTest = loadDataSet("./data/horseColicTest.txt")
m = np.shape(dataArrTest)[0]
predicting10 = adaClassify(dataArrTest, weakClassArr)
errArr = np.mat(np.ones((m, 1)))
# 测试:计算总样本数,错误样本数,错误率
print(m, errArr[predicting10 != np.mat(labelArrTest).T].sum(), errArr[predicting10 != np.mat(labelArrTest).T].sum()/m)