1.merge合并 → 类似excel的vlookup
# merge合并 → 类似excel的vlookup df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'], 'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3']}) df2 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}) df3 = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'], 'key2': ['K0', 'K1', 'K0', 'K1'], 'A': ['A0', 'A1', 'A2', 'A3'], 'B': ['B0', 'B1', 'B2', 'B3']}) df4 = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'], 'key2': ['K0', 'K0', 'K0', 'K0'], 'C': ['C0', 'C1', 'C2', 'C3'], 'D': ['D0', 'D1', 'D2', 'D3']}) print(df1,' ',df2,' ') print(pd.merge(df1, df2, on='key')) #按照’key'字段进行连接 print('------',' ') # left:第一个df # right:第二个df # on:参考键 print(df3,' ',df4,' ') print(pd.merge(df3, df4, on=['key1','key2'])) # 多个链接键
输出结果:
A B key 0 A0 B0 K0 1 A1 B1 K1 2 A2 B2 K2 3 A3 B3 K3 C D key 0 C0 D0 K0 1 C1 D1 K1 2 C2 D2 K2 3 C3 D3 K3 A B key C D 0 A0 B0 K0 C0 D0 1 A1 B1 K1 C1 D1 2 A2 B2 K2 C2 D2 3 A3 B3 K3 C3 D3 ------ A B key1 key2 0 A0 B0 K0 K0 1 A1 B1 K0 K1 2 A2 B2 K1 K0 3 A3 B3 K2 K1 C D key1 key2 0 C0 D0 K0 K0 1 C1 D1 K1 K0 2 C2 D2 K1 K0 3 C3 D3 K2 K0 A B key1 key2 C D 0 A0 B0 K0 K0 C0 D0 1 A2 B2 K1 K0 C1 D1 2 A2 B2 K1 K0 C2 D2
2. 参数how → 合并方式
# 参数how → 合并方式 print(pd.merge(df3, df4,on=['key1','key2'], how = 'inner')) print('------') # inner:默认,取交集 print(pd.merge(df3, df4, on=['key1','key2'], how = 'outer')) print('------') # outer:取并集,数据缺失范围NaN print(pd.merge(df3, df4, on=['key1','key2'], how = 'left')) print('------') # left:按照df3为参考合并,数据缺失范围NaN print(pd.merge(df3, df4, on=['key1','key2'], how = 'right')) # right:按照df4为参考合并,数据缺失范围NaN
输出结果:
A B key1 key2 C D 0 A0 B0 K0 K0 C0 D0 1 A2 B2 K1 K0 C1 D1 2 A2 B2 K1 K0 C2 D2 ------ A B key1 key2 C D 0 A0 B0 K0 K0 C0 D0 1 A1 B1 K0 K1 NaN NaN 2 A2 B2 K1 K0 C1 D1 3 A2 B2 K1 K0 C2 D2 4 A3 B3 K2 K1 NaN NaN 5 NaN NaN K2 K0 C3 D3 ------ A B key1 key2 C D 0 A0 B0 K0 K0 C0 D0 1 A1 B1 K0 K1 NaN NaN 2 A2 B2 K1 K0 C1 D1 3 A2 B2 K1 K0 C2 D2 4 A3 B3 K2 K1 NaN NaN ------ A B key1 key2 C D 0 A0 B0 K0 K0 C0 D0 1 A2 B2 K1 K0 C1 D1 2 A2 B2 K1 K0 C2 D2 3 NaN NaN K2 K0 C3 D3
3.参数 left_on, right_on, left_index, right_index → 当键不为一个列时,可以单独设置左键与右键
# 参数 left_on, right_on, left_index, right_index → 当键不为一个列时,可以单独设置左键与右键 df1 = pd.DataFrame({'lkey':list('bbacaab'), 'data1':range(7)}) df2 = pd.DataFrame({'rkey':list('abd'), 'date2':range(3)}) print(pd.merge(df1, df2, left_on='lkey', right_on='rkey')) print('------') # df1以‘lkey’为键,df2以‘rkey’为键 df1 = pd.DataFrame({'key':list('abcdfeg'), 'data1':range(7)}) df2 = pd.DataFrame({'date2':range(100,105)}, index = list('abcde')) print(pd.merge(df1, df2, left_on='key', right_index=True)) # df1以‘key’为键,df2以index为键 # left_index:为True时,第一个df以index为键,默认False # right_index:为True时,第二个df以index为键,默认False # 所以left_on, right_on, left_index, right_index可以相互组合: # left_on + right_on, left_on + right_index, left_index + right_on, left_index + right_index #merge是针对DataFrame的,Series不存在此方法
输出结果:
data1 lkey date2 rkey 0 0 b 1 b 1 1 b 1 b 2 6 b 1 b 3 2 a 0 a 4 4 a 0 a 5 5 a 0 a ------ data1 key date2 0 0 a 100 1 1 b 101 2 2 c 102 3 3 d 103 5 5 e 104
4. 连接:concat
(1)
# 连接:concat s1 = pd.Series([1,2,3]) s2 = pd.Series([2,3,4]) print(pd.concat([s1,s2])) print('-----') # 默认axis=0,行+行 s3 = pd.Series([1,2,3],index = ['a','c','h']) s4 = pd.Series([2,3,4],index = ['b','e','d']) print(s3,' ') print(s4,' ') print(pd.concat([s3,s4]),' ') print(pd.concat([s3,s4]).sort_index()) print(pd.concat([s3,s4], axis=1)) print('-----') # axis=1,列+列,成为一个Dataframe
输出结果:
0 1 1 2 2 3 0 2 1 3 2 4 dtype: int64 ----- a 1 c 2 h 3 dtype: int64 b 2 e 3 d 4 dtype: int64 a 1 c 2 h 3 b 2 e 3 d 4 dtype: int64 a 1 b 2 c 2 d 4 e 3 h 3 dtype: int64 0 1 a 1.0 NaN b NaN 2.0 c 2.0 NaN d NaN 4.0 e NaN 3.0 h 3.0 NaN -----
(2)
snew = pd.concat([s3,s4],axis = 1) print(snew) # snew.reset_index(inplace = True) # print(snew) snew.reset_index(inplace = True,drop = True) snew
输出结果:
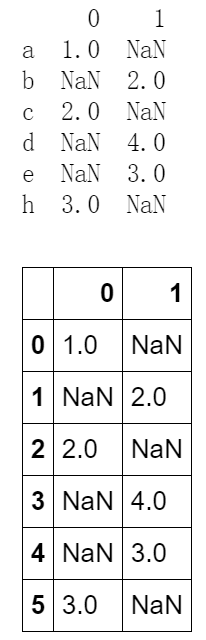
5.去重 .duplicated
# 去重 .duplicated s = pd.Series([1,1,1,1,2,2,2,3,4,5,5,5,5]) print(s.duplicated()) print(s[s.duplicated() == False]) print('-----') # 判断是否重复 # 通过布尔判断,得到不重复的值 s_re = s.drop_duplicates() print(s_re) print('-----') # drop.duplicates移除重复 # inplace参数:是否替换原值,默认False df = pd.DataFrame({'key1':['a','a',3,4,5], 'key2':['a','a','b','b','c']}) print(df,' ') print(df.duplicated()) print(df['key2'].duplicated()) # Dataframe中使用duplicated
输出结果:
0 False 1 True 2 True 3 True 4 False 5 True 6 True 7 False 8 False 9 False 10 True 11 True 12 True dtype: bool 0 1 4 2 7 3 8 4 9 5 dtype: int64 ----- 0 1 4 2 7 3 8 4 9 5 dtype: int64 ----- key1 key2 0 a a 1 a a 2 3 b 3 4 b 4 5 c 0 False 1 True 2 False 3 False 4 False dtype: bool 0 False 1 True 2 False 3 True 4 False Name: key2, dtype: bool
6. 替换 .replace
0 a 1 s 2 c 3 a 4 a 5 z 6 s 7 d dtype: object 0 NaN 1 s 2 c 3 NaN 4 NaN 5 z 6 s 7 d dtype: object 0 NaN 1 NaN 2 c 3 NaN 4 NaN 5 z 6 NaN 7 d dtype: object 0 hello world! 1 123 2 c 3 hello world! 4 hello world! 5 z 6 123 7 d dtype: object
练习题:
作业1:按要求创建Dataframe df1、df2,并合并成df3

import numpy as np import pandas as pd df1 = pd.DataFrame({'key':list('abc'), 'values1':np.random.rand(3)}) df2 = pd.DataFrame({'key':list('bcd'), 'values2':np.random.rand(3)}) print(df1,' ') print(df2,' ') print(pd.merge(df1, df2,on='key',how = 'outer'))
作业2:按要求创建Dataframe df1、df2,并合并成df3

#练习2 df3 = pd.DataFrame({'key1':['a','b','c'], 'values1':np.random.rand(3)}) df4 = pd.DataFrame({'key2':['b','c','d'], 'values2':np.random.rand(3)}) print(df3,' ') print(df4,' ') print(pd.merge(df3, df4,left_on='key1',right_on='key2',how = 'outer'))
作业3:按要求创建Dataframe df1、df2,并合并成df3
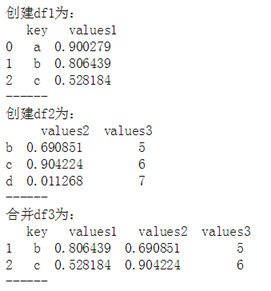
#练习3 # df3 = pd.DataFrame({'key':['a','b','c'], # 'values1':np.random.rand(3)}) # df4 = pd.DataFrame({'values2':np.random.rand(3), # 'values3':[5,6,7]},index=['b','c','d']) # print(df3,' ') # print(df4,' ') # print(pd.merge(df3, df4,left_on='key',right_index= True))
作业4:按要求创建Dataframe df1、df2,并连接成df3
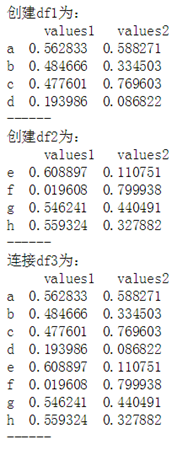
#练习4 # df3 = pd.DataFrame({'values1':np.random.rand(4), # 'values2':np.random.rand(4)},index = ['a','b','c','d']) # df4 = pd.DataFrame({'values1':np.random.rand(4), # 'values2':np.random.rand(4)},index=['e','f','g','h']) # print(df3,' ') # print(df4,' ') # print(pd.concat([df3,df4]))