本来算法没有那么复杂,但如果因为语法而攻不下就很耽误时间。于是就整理一下,搞python机器学习上都需要些什么基本语法,够用就行,可能会持续更新。
Python四大类型
元组tuple,初始化之后不可元素值变更,其余还没有感受到它和list什么差别,感觉也比较少用,声明语法是()
>>> tp = ()
>>> type(tp)
<class 'tuple'>
字典dict,声明语法{},对值 .items(),键值 .keys(),值 .values()
>>> d = {'left': {0}, 'right' :1}
>>> d
{'left': {0}, 'right': 1}
>>> d.keys()
dict_keys(['left', 'right'])
集合set,声明语法set(),括号内只能传一个参数,这个参数要可迭代。
整这么多类型干什么呢,主要是每个类型具有的属性不同。
Python支持集合类型的交集(用&)、并集(用|)、差集(用-)、交叉补集(用^)等操作
>>> setA = set(1,2)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: set expected at most 1 arguments, got 2
>>> setA = set([1,'a',2.0])
>>> setB = set(['a'])
>>> setA | setB
{1, 2.0, 'a'}
列表list,声明语法[],这个类型很常用,
需要注意一点的是,在按列表索引查询列表的数据时,方括号里不能出现小写逗号。这是目前我知道的,它与numpy.array类型的主要区别之一(前者用两个方括号)。
>>> lst = [[0,1,2],[3,4,5],[6,7,8],[9,10,11]]
>>> lst[1:3]
[[3, 4, 5], [6, 7, 8]]
>>> lst[1:5:2]
[[3, 4, 5], [9, 10, 11]]
[a:b:c]指从下标a到下标b(不包括下标b)的以c行作为间隔取行,c默认是1。例如1~10,如果取2:8:2就是2,4,6
如果a(或b)为负数,意思是取倒数的a行(或b行)
数组 numpy.array,这个,和list写法差不多,但是它很多比较方便的属性,
比如获取矩阵大小shape,改变矩阵大小reshape,矩阵转置T,等等。还有一个mat类型(声明为mat()),就是矩阵(matrix)类型,也差不多。
array比list方便的一点还在于,按索引查询当中,array可以选择查询的列,其中对列的筛选,需要用小写逗号隔开。
(如果是list类型,取第一行第一列是testlist[0][0])
>>> test = [[0,2],[1,3],[4,0],[2,1],[5,1]]
>>> test
[[0, 2], [1, 3], [4, 0], [2, 1], [5, 1]]
>>> test[0]
[0, 2]
>>> test[0][0]
0
>>> testA = np.array(test)
>>> testA[0, :]
array([0, 2])
循环
for item in iterator
常用for item in range(5)相当于for (int i = 0; i < 5; i++)
或者for item in listInstance就是foreach item in listInstance
numpy函数介绍:
关于这个,其实百度一下啥都有,或者在编辑器里悬停鼠标,可见描述。此处记一下我遇到的,感觉比较特殊的:
numpy.nonzero() #求非0元素所在位置
>>> import numpy as np
>>> test = [[1,2,5,0],[0,0,1,0]]
>>> np.nonzero(test)
(array([0, 0, 0, 1], dtype=int64), array([0, 1, 2, 2], dtype=int64))
dtype是dataType,指前面这个array里面数值的类型。
求出来是两行内容,第一行是非0的所在行下标,这个行下标出现多少次,就表示这个行有多少个非0元素;第二行是对应第一行的列中,非0元素所在列位置。
|
列下标行下标 |
0 |
1 |
2 |
3 |
|
0 |
1 |
2 |
5 |
0 |
|
1 |
0 |
0 |
1 |
0 |
出现0的位置:
|
行下标 |
0 |
0 |
0 |
1 |
|
列下标 |
0 |
1 |
2 |
2 |
var() #求方差
看见这个第一印象真是variable,弱类型,然而,np.var()此var是variance,方差。
关于查询
有3个强大的函数
https://www.liaoxuefeng.com/wiki/1016959663602400/1017329367486080
>>> def f(x):
... return x * x
...
>>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> list(r)
[1, 4, 9, 16, 25, 36, 49, 64, 81]
reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
>>> from functools import reduce
>>> def add(x, y):
... return x + y
...
>>> reduce(add, [1, 3, 5, 7, 9])
25
排序sorted(list, key = function)
最最重要的是这个:filter()
接受两个参数,一个是函数类型,一个是迭代器类型
!! filter()这个函数非常重要,相当于C#的linq to object
filter()函数返回的是一个Iterator,需要再转换类型,可用list(返回内容)
list类型处理下标查询,还能这样:
>>> test = [[1,2,5,0],[0,0,1,0]]
>>> test = np.array(test)
>>> test[0, :] >= 2
array([False, True, True, False])
>>> test[[0,0,0,1],:]
array([[1, 2, 5, 0],
[1, 2, 5, 0],
[1, 2, 5, 0],
[0, 0, 1, 0]])
>>> test[:, np.nonzero((test[0, :] >= 2))[0]]
array([[2, 5],
[0, 1]])
最后一例这个查询,看起来好像很厉害,但是吧,这个可读性让人感到难受,真是不要也罢。
而且,就此例而言,时间复杂度是多少,只是筛选≥2的数据,列表遍历了3次,这能忍吗?
用filter()不是简单明了很多吗?
我这个写法有点古怪,可能不太正确:
>>> def TestFilter(x):
... if x >= 2:
... return x
... else: return
>>> test1 = [5,2,3,1,0,0]
>>> list(filter(TestFilter, test1))
[5, 2, 3]
return就是默认return None
于是,这样也是可行的:
>>> def tt(x):
... if(x >= 2):
... return x
再简略一些:
>>> list(filter(lambda x : x >=2, test1))
[5, 4, 3, 2]
然后问题又来了,不能处理二维的list,只能是原子型的list,这样看来,《机器学习》那书上写的办法好像经得起考验?
不,不可能这么沙雕。
对象化数据不就可以了么!真是多多感谢linq to object,有时候真觉得语言设计者太厉害了,方方面面想到了。
>>> def testFilter(x):
... if x.col1 > value:
... return x
... else: return
练一练:
搞明白上面的语法,基本就能直接看明白这个CART算法的决策树(classification and regression tree)
(代码按阅读顺序排序的,如果要走,注意函数声明顺序)
1 from numpy import * 2 def createTree(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)): 3 feat, val = chooseBestSplit(dataSet, leafType, errType, ops) 4 if feat == None: return val 5 retTree = {} 6 retTree['spInd'] = feat 7 retTree['spVal'] = val 8 lSet, rSet = binSplitDataSet(dataSet, feat, val) 9 retTree['left'] = createTree(lSet, leafType, errType, ops) 10 retTree['right'] = createTree(rSet, leafType, errType, ops) 11 return retTree 12 13 def chooseBestSplit(dataSet, leafType=regLeaf, errType=regErr, ops=(1,4)): 14 tolS = ops[0]; tolN = ops[1] 15 if len(set(dataSet[:, -1].T.tolist()[0])) == 1: #取最后一列,转置为行,取第一行转作集合类型,判断集合元素个数 16 return None, leafType(dataSet) 17 m,n = shape(dataSet) #数据集大小 18 S = errType(dataSet) #errType是个方法,默认为方法regErr,计算数据集数据波动情况 19 bestS = inf; bestIndex = 0; bestValue = 0 20 for featIndex in range(n-1): #每一列 21 for splitVal in dataSet[:,featIndex]: #每一行 22 mat0, mat1 = binSplitDataSet(dataSet, featIndex, splitVal) #按当前单元格作为划分列的阈值 23 if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): continue #划分出来的两块,任一块元素个数太小的话 24 newS = errType(mat0) + errType(mat1) #划分出来的两块大小比较合理,就分别计算误差 25 if newS < bestS: 26 bestIndex = featIndex 27 bestValue = splitVal 28 bestS = newS 29 if (S - bestS) < tolS: 30 return None, leafType(dataSet) 31 mat0, mat1 = binSplitDataSet(dataSet, bestIndex, bestValue) 32 if (shape(mat0)[0] < tolN) or (shape(mat1)[0] < tolN): 33 return None, leafType(dataSet) 34 return bestIndex,bestValue 35 36 def regLeaf(dataSet): 37 return mean(dataSet[:,-1]) #我不仅知道mean是吝啬,我还知道mean是平均值 38 39 def regErr(dataSet): 40 return var(dataSet[:,-1]) * shape(dataSet)[0] 41 42 def binSplitDataSet(dataSet, feature, value): 43 a = dataSet[nonzero(dataSet[:,feature] > value)[0],:] #所有大于value的行 44 b = dataSet[nonzero(dataSet[:,feature] <= value)[0],:] 45 if (len(a) > 0): 46 mat0 = a 47 else: mat0 = [] 48 if (len(b) > 0): 49 mat1 = b 50 else: mat1 = [] 51 return mat0,mat1 52 53 def loadDataSet(fileName): #general function to parse tab -delimited floats 54 dataMat = [] #assume last column is target value 55 fr = open(fileName) 56 for line in fr.readlines(): 57 curLine = line.strip().split(' ') 58 fltLine = list(map(float,curLine)) #此处的float是个函数,float(),类型转换为float 59 dataMat.append(fltLine) 60 #dataMat.append(curLine) 61 return mat(dataMat)
Q:代码返回的是个什么树?
两列两百行的数据集,其中最后一列是标签,返回的是一个节点的树。
{'left': 1.0180967672413792, 'right': -0.04465028571428572, 'spInd': 0, 'spVal': matrix([[0.48813]])}
这个节点意思是:列下标为0作为判断依据,当待归类数值>spval阈值,就走左分支树;待归类≤spval,走右分支。
树剪枝
这个算法走下来,对这个ops=(1,4)的依赖,就很大,人很难把握到这个默认值是多少比较合适。
树的分支少了,很可能就意味着树不准确,拟合度不够;树的分支多了,就过拟合了,先不说计算成本可能增多,如果让归类范围有太大偏差就不好了。
再,如何判断这个树拟合程度如何?——可以放一些新的带已知结果的数据进去,比较一下分类结果误差情况。如果新数据在某个节点的分类误差比较大,那倒不如不要这个节点了。当然,这个过程要从叶节点开始计算。这就是树剪枝。
树剪枝,有时候真觉得,算法怎么可以没有动画,没有图呢,只有公式,劝退多少人啊。

这个图取自李航的《统计学习方法》,感觉一下子get到精髓——这个损失得怎么设置?
1 def isTree(obj): 2 return (type(obj).__name__=='dict') #此代码树的类型是dict 3 4 def getMean(tree): 5 if isTree(tree['right']): tree['right'] = getMean(tree['right']) 6 if isTree(tree['left']): tree['left'] = getMean(tree['left']) 7 return (tree['left']+tree['right'])/2.0 8 9 def prune(tree, testData): #这个testData最后一列还是标签列,是个数值 10 if shape(testData)[0] == 0: return getMean(tree) #if we have no test data collapse the tree 11 if (isTree(tree['right']) or isTree(tree['left'])): #if the branches are not trees try to prune them 12 lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal']) 13 if isTree(tree['left']): tree['left'] = prune(tree['left'], lSet) 14 if isTree(tree['right']): tree['right'] = prune(tree['right'], rSet) 15 #if they are now both leafs, see if we can merge them 16 if not isTree(tree['left']) and not isTree(tree['right']): 17 lSet, rSet = binSplitDataSet(testData, tree['spInd'], tree['spVal']) 18 errorNoMerge = sum(power(lSet[:,-1] - tree['left'],2)) + sum(power(rSet[:,-1] - tree['right'],2)) 19 treeMean = (tree['left']+tree['right'])/2.0 20 errorMerge = sum(power(testData[:,-1] - treeMean,2)) 21 if errorMerge < errorNoMerge: 22 print("merging") 23 return treeMean 24 else: return tree 25 else: return tree
原来按节点的阈值划分testData的数据后,分别求两个数据块与左右子树的距离总数 errorNoMerge,如果这个距离比按另一个数 errorMerge 大时,就合并。这个损失函数的选定,看似有些拓展空间,但我更喜欢具体问题具体分析,所以此处不展开。
随机森林
随机森林(Random Forest)是一种集成学习方法。
集成学习,我的理解是,有几种决策模型,可能大家意见不同,然后投票(取平均或设置决策模型权重)决出结果。
集成学习是一种“投票法”,少数服从多数。因为集成学习中每个个体学习器可能学到的是任务的不同方面,综合不同方面的结果可以达到一定程度上的泛化作用。是由多个弱学习器组成一个强学习器。
随机森林里设置有多颗决策树,任务结果由这些决策树投票决出。
设定现有M * N大小的DataSet,其中M为数据行数,N为特征列数目。随机森林算法步骤如下:
1.有放回地(有放回抽样Bootstrap Sample)x次取出y行n个(n应远小于N)特征列,其中x * y = m,创建x个决策树(每棵树都不需要剪枝);

2.由步骤1组成随机森林,其中,对于分类问题:根据多棵树分类器投票[0]决出分类结果;对于回归问题,取多棵树预测值的均值[0]作为预测结果。
[0]对于步骤2,如何对子模型赋予“其结果重要性”还可以再玩些花样。
3.取未被步骤1选中过的数据集(OOB,out-of-bag[1])作为测试数据,需要测试准确率(袋外错误率out-of-bag error),这个准确率可以粗暴地这样处理:比较经过随机森林得到的决策结果与真实结果,以求得准确率。
[1]关于有放回抽样 Bootstrap Sample,
设在袋中有x个不同的小球,有放回抽取x个,那么抽到不同小球的个数大概是多少个?
此时,有一个小球在一次抽取中被抽中的概率是1/x,设小球不被抽中的概率是P,x次不被抽中的概率是:
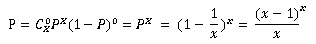
其中又:

所以,当x取无穷大时,有:

所以,不会被抽中的球大概有:x·P个。
假如设x取100,那么大概会取到不同的小球个数是100 – 36.79 ≈ 63
参考自:https://blog.csdn.net/cholocatehe/article/details/42130341
4.得到准确率后给步骤2得到的众决策树添加决策权重,准确率高的权重稍高一些,准确率低的权重稍小一些。当然,此步不走,那么步骤2每棵树权重就取平均。
随机森林 缺点:
想要得出超过范围的独立变量或非独立变量,可能不行;
关于网上所说的一点,“噪音较大的数据,RF容易陷入过拟合”,这个说法的缺点,不太赞成叭,如果噪音这么大,就应该预处理,应该很少有方法可以不需要预处理数据(神经网络好像可以);
比较明显的缺点还没感受到,如果后面有实操,再来补充。
其他:
Python实现:
在scikit-learn类库里面有很多现成的集成学习方法
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.ensemble
更多文献 github 上也有人归纳了: