转载请注明出处
利用python2.7正则表达式进行豆瓣电影Top250的网络数据采集
1.任务
-
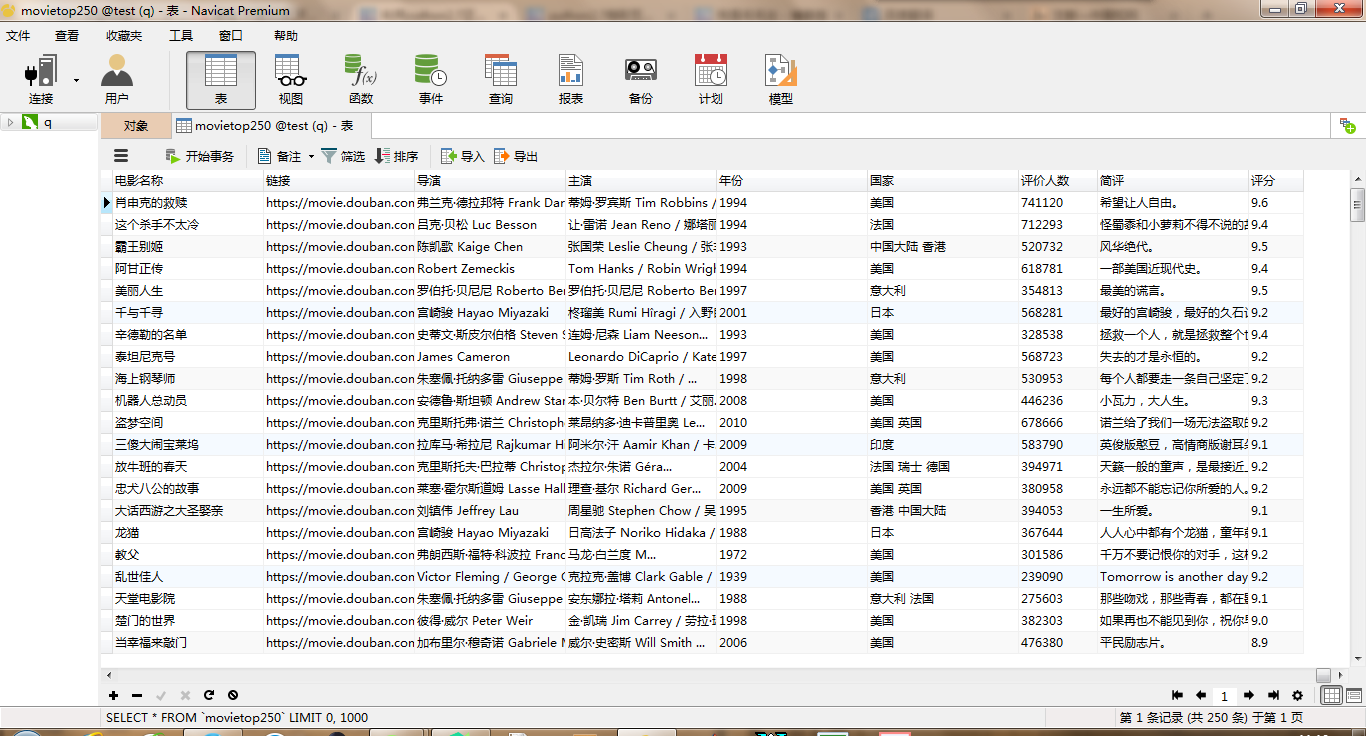
采集豆瓣电影名称、链接、评分、导演、演员、年份、国家、评论人数、简评等信息
-
将以上数据存入MySQL数据库
2.任务解析
-
requests是很好的网络数据采集模块,配合BeautifulSoup可以解析许多HTML。但个人认为BeautifulSoup返回对象不是字符串,而利用其find及findall总觉得力有未逮,与正则表达式的配合总显得有些冗余,甚至需要将BeautifulSoup返回对象转换成字符串形式与正则表达式配合使用,这里我不再利用BeautifulSoup,而是直接利用requests得到的网络文本配合正则表达式完成本次任务。
-
利用request得到的网络文本,这里截取一段某部电影的完整的网络文本:
<li> <div class="item"> <div class="pic"> <em class="">2</em> <a href="https://movie.douban.com/subject/1295644/"> <img alt="这个杀手不太冷" src="https://img3.doubanio.com/view/movie_poster_cover/ipst/public/p511118051.jpg" class=""> </a> </div> <div class="info"> <div class="hd"> <a href="https://movie.douban.com/subject/1295644/" class=""> <span class="title">这个杀手不太冷</span> <span class="title"> / Léon</span> <span class="other"> / 杀手莱昂 / 终极追杀令(台)</span> </a> <span class="playable">[可播放]</span> </div> <div class="bd"> <p class=""> 导演: 吕克·贝松 Luc Besson 主演: 让·雷诺 Jean Reno / 娜塔丽·波特曼 ...<br> 1994 / 法国 / 剧情 动作 犯罪 </p> <div class="star"> <span class="rating5-t"></span> <span class="rating_num" property="v:average">9.4</span> <span property="v:best" content="10.0"></span> <span>712293人评价</span> </div> <p class="quote"> <span class="inq">怪蜀黍和小萝莉不得不说的故事。</span> </p> </div> </div> </div> </li>
-
其他部分正则匹配参考代码相关部分
-
需要说明的是,电影年份中第84部《大闹天空》年份如下:'1961(上集) / 1964(下集) / 1978(全本) / 2004(纪念版)',不能通过数字匹配的方式获取年份,因此需要添加。某些电影没有主演及简评等信息,这里需要查找添加。相关代码见78-90行
3.代码
1 #!/usr/bin/python 2 # -*- coding: utf-8 -*- # 3 # 豆瓣电影top250 4 import requests,sys,re,MySQLdb,time 5 6 reload(sys) 7 sys.setdefaultencoding('utf-8') 8 print '正在从豆瓣电影Top250抓取数据......' 9 # --------------------------创建列表用于存放数据-----------------------------# 10 nameList=[] 11 linkList=[] 12 scoreList=[] 13 directorList=[] 14 playList=[] 15 yearList=[] 16 countryList=[] 17 commentList=[] 18 criticList=[] 19 #---------------------------------爬取模块------------------------------------# 20 def topMovie(): 21 for page in range(1): 22 url='https://movie.douban.com/top250?start='+str(page*25) 23 print '正在爬取第---'+str(page+1)+'---页......' 24 html=requests.get(url) 25 html.raise_for_status() 26 try: 27 contents=html.text # 返回网页内容,是字符串的形式 28 # ---------------------------------匹配电影中文名------------------------------------# 29 name=re.compile(r'<span class="title">(.*)</span>') 30 names=re.findall(name,contents) 31 for movieName in names: 32 if movieName.find('/')==-1: 33 nameList.append(movieName) 34 # ---------------------------------匹配电影链接------------------------------------# 35 link=re.compile(r'a href="(.*)" class=""') 36 links=re.findall(link,contents) 37 for movieLink in links: 38 linkList.append(movieLink) 39 # ---------------------------------匹配电影评分------------------------------------# 40 score=re.compile(r'<span class="rating_num" property="v:average">(.*)</span>') 41 scores=re.findall(score,contents) 42 for movieScore in scores: 43 scoreList.append(movieScore) 44 # ---------------------------------匹配导演------------------------------------# 45 director=re.compile(ur'导演: (.*) ') 46 directors=re.findall(director,contents) 47 for movieDirector in directors: 48 directorList.append(movieDirector) 49 # ---------------------------------匹配主演------------------------------------# 50 play=re.compile(u'主(.*?)<br>') 51 plays=re.findall(play,contents) 52 for moviePlay in plays: 53 playList.append(moviePlay.strip(ur'演: ')) 54 # ---------------------------------匹配年份------------------------------------# 55 year=re.compile(r'(dddd) / ') 56 years=re.findall(year,contents) 57 for movieyear in years: 58 yearList.append(movieyear) 59 # ---------------------------------匹配国家------------------------------------# 60 country=re.compile(ur' / (.*) / ') 61 countries=re.findall(country,contents) 62 for movieCountry in countries: 63 countryList.append(movieCountry) 64 # ---------------------------------匹配评价人数------------------------------------# 65 commentor=re.compile(ur'<span>(.*)人评价</span>') 66 commentors=re.findall(commentor,contents) 67 for movieCommentor in commentors: 68 commentList.append(movieCommentor) 69 # ---------------------------------匹配简评------------------------------------# 70 critic=re.compile(r'<span class="inq">(.*)</span>') 71 critics=re.findall(critic,contents) 72 for movieCritic in critics: 73 criticList.append(movieCritic) 74 75 except Exception as e: 76 print e 77 print '爬取完毕!' 78 # ---------------------------------个别部分修改-----------------------------------# 79 # 需要在第84部《大闹天空》不能通过上面的方法筛选,需要在83后加入加入数据 80 yearList.insert(83, '1961(上集) / 1964(下集) / 1978(全本) / 2004(纪念版)') 81 playList.insert(38,'...') # 某些电影没有主演和评论,这里用...代替 82 playList.insert(233,'...') 83 criticList.insert(134,'...') 84 criticList.insert(156,'...') 85 criticList.insert(176,'...') 86 criticList.insert(180,'...') 87 criticList.insert(196,'...') 88 criticList.insert(230,'...') 89 criticList.insert(232,'...') 90 return nameList,linkList,scoreList,directorList,playList,yearList,countryList,commentList,criticList 91 # ---------------------------------储存到数据库-----------------------------------# 92 def save_to_MySQL(): 93 print 'MySQL数据库存储中......' 94 try: 95 conn = MySQLdb.connect(host="127.0.0.1", user="root", passwd="******", db="test", charset="utf8") 96 cursor = conn.cursor() 97 print "数据库连接成功" 98 cursor.execute('Drop table if EXISTS MovieTop250') # 如果表存在就删除 99 time.sleep(3) 100 cursor.execute('''create table if not EXISTS MovieTop250( 101 编号 int not NULL auto_increment PRIMARY KEY , 102 电影名称 VARCHAR (200), 103 链接 VARCHAR (200), 104 导演 VARCHAR (200), 105 主演 VARCHAR (200), 106 年份 VARCHAR (200), 107 国家 VARCHAR (200), 108 评价人数 VARCHAR (200), 109 简评 VARCHAR (200), 110 评分 VARCHAR (20))''') 111 for i in range(250): 112 sql='insert into MovieTop250(电影名称,链接,导演,主演,年份,国家,评价人数,简评,评分)' 113 ' VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s)' 114 param=(nameList[i],linkList[i],directorList[i],playList[i],yearList[i], 115 countryList[i],commentList[i],criticList[i],scoreList[i]) 116 cursor.execute(sql,param) 117 conn.commit() 118 cursor.close() 119 conn.close() 120 except Exception as e: 121 print e 122 print 'MySQL数据库存储结束!' 123 124 # -------------------------------------主模块--------------------------------------# 125 if __name__=="__main__": # 相当于c语言中的main()函数 126 try: 127 topMovie() 128 save_to_MySQL() 129 except Exception as e: 130 print e
4.结果
欢迎大家与我交流,一起学习和探讨。