breakpad 是什么
breakpad 是一个包含了一系列库文件和工具的开源工具包,使用它可以帮助我们在程序崩溃后进行一系列的后续处理,如现场的保存(core dump),及事后分析(重建 call stack )等,它提供了非常有效且易用的工具来帮助开发者处理程序的异常崩溃。该项目由 google 所开发维护并开源,代码托管在 google code 上。
breakpad 具有跨平台的特性,支持 window, linux, mac 三大平台,可以运行于一系列架构的 cpu 上,现在已经被广泛运用在 google 的一系列产品及其它公司的桌面程序上,如 chrome,piscal,firefox 等。 这篇文章主要介绍一下其在 linux 下结构,breakpad 主要包括三大主件:
1) client.
2) symbol dumper.
3) processor.
各个模块
(1) client module.
client 模块作为一个静态库将会与使用者的程序编译在一块。它的主要作用是在程序崩溃后,接管程序的异常处理,具体来说,它主要做了两方面的事情:
a) 响应程序崩溃时接收到的 signal,包括:SIGSEGV,SIGABRT,SIGFPE,SIGILL,SIGBUS。(另外两个 SIGSTOP 和 SIGKILL 无法处理)
b) 获取程序崩溃那一刻的运行时信息,保存为一个 mini dump 格式的文件(可以想像为一个特殊格式的 core dump)
下图描述了 client module 中几个类的关系及工作的流程:
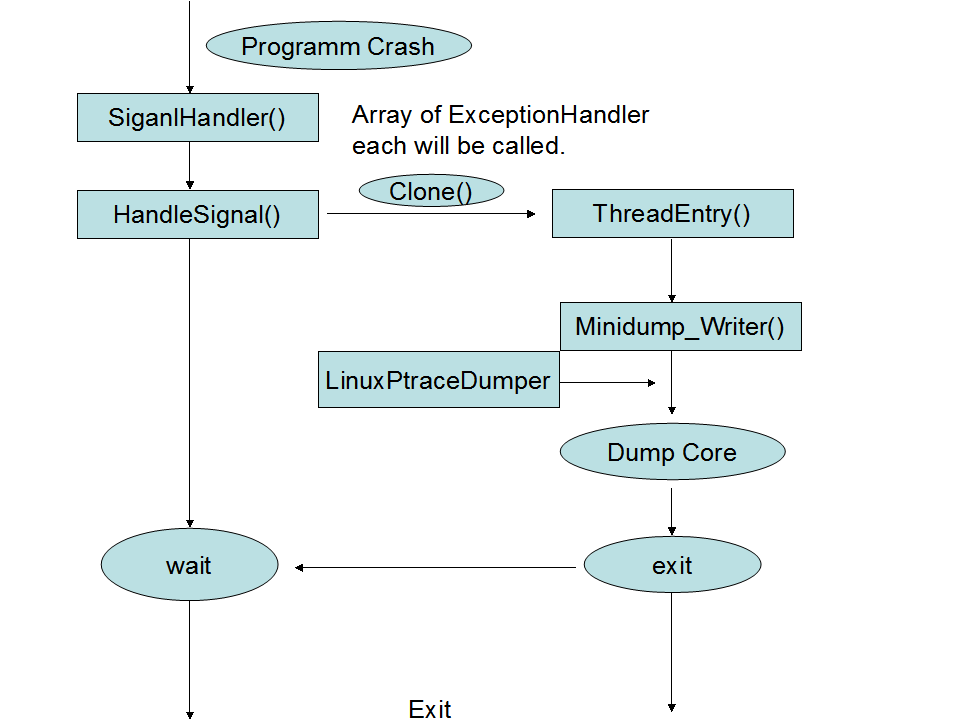
如上,breakpad 通过提供信号处理函数来响应程序的崩溃,然后在信号处理函数中,保存程序崩溃时的现场信息,在这里有几点需要说明:
a) 程序崩溃后,整个进程空间已经处于一个不稳定的状态,在这样的不稳定状态下,再进行内存的分配,和调用动态库里的函数,都是不安全的。之所以说处在不稳定状态,主要是指如果当前的崩溃是由 SIGSEGV 引起的,那么此时程序的内存可能已经被破坏了(heap,stack,数据段),而引用动态库是需要查找一堆数据段里的表项(plt,got),这些数据很可能已经被破坏,因此没法正确加载动态库,至于不能 malloc 那是基本同理的,heap 可能已经被破坏了,malloc 内部维护的数据未必还正常,也就无法保证还能正确进行 malloc。
b) 信号处理函数会 clone 出一个新的进程,dump core 这件事情则是在这个 clone 出来的子进程中进行的,子进程通过 ptrace 来与父进程进行交互,从而读取父进程的相关信息。
c) breakpad 的 exception handling 有两种模式,一种是 in process,一种是 out of process。但在 Linux 平台上,暂时只有 in process 这种模式,in process 的实现相对简单些,流程很清楚明了,out of process 相对就复杂了。按照开发者的设计意想,是为每一个登陆 Linux 的登陆用户起一个 deamon 程序运行于后台,当该用户的其它程序崩溃后,崩溃程序通过与这个 deamon 程序进行交互,从而保存 core dump。其中,交互方面将通过 socket 按照client/server 的模式进行,但是至今为止,这种模式还未可用。
在上图中,MinidumpWriter 这个类是一个包装,提供一些与 write dump 相关的接口函数给上层的函数处理函数进行调用,真正与 linux process 相关的操作都放在 LinuxPtraceDump 这个类中进行。client 程序崩溃之后中,dump 出来的内容主要包含以下几个内容:
a) 各个线程相关的运行时信息。如 stack pointer,context,mapping 等,以一个线程为单位保存在一个数组中(list)。
b) 当前进程的各种内存映射(Mapping)
c) 用户指定的内存区域(application-provided memory regions)
d) 异常信息(crash address, signal, thread id, context)
e) 当前系统的信息 (cpu, os info)
上述的内容会以 minidump 的格式组织起来保存为一个二进制文件,minidump 格式是一种简单的流格式,由微软所设计,具体可看下图:

上图中,_MINIDUMP_DIRECTOR 就是各种流的 container,流的类型不同,它所包含的数据形式就有所不同。具体各个流的数据格式是怎样的,可以参考一下 MSDN 的说明:http://msdn.microsoft.com/en-us/library/windows/desktop/ms680394(v=vs.85).aspx
(2) symbol dumper.
这个模块主要是用来从可执行程序中提取与符号相关的信息,并保存为一种特定格式的文件。为什么要提取符号信息? 根据前面的介绍,client 模块在程序崩溃时保存了一个 core dump 文件,但这个 core dump 出于简单及实用考虑,保存的都是些二进制的数据,只通过这些数据,我们根本无法重建出可读的 call stack. 因此 symbol dumper 就是用来产生一个可与 core dum p配合起来使用的符号文件。
编译非 release 版本的程序时(如,gcc 开了-g 选项),编译器通常会将带有符号相关的信息以某种格式(DWARF,STABS)组织起来,存放在可执行文件的某个段位里。breakpad 的 symbol dumper 就是要从这些段位里提取出它认为有用的信息。
下面具体来说一下这个 symbol file:
1)symbol file 中全部内容都是ascii文本。
2)symbol file 的内容以行单位,每一行称作一条记录,每条记录中有多个字段,每个字段以空格分开。
3)每条记录的开头是一个串字符,这个字符标记这条记录是什么类型的记录。但 Line record 除外,这种类型的记录,默认省略掉标记符,也就是如果有一行没有标记类型,这一行就是一个Line record.
4)记录中有些字段是10进制或16进制的字符串,16进制也没有以0x开头,要分清某个数字具体是哪种进制,就要看这些数字是在哪种记录里,属于哪个字段,这些都是规定死了的。
记录的类型主要有以下几种:
- MODULE: 这种记录用来描述当前这个可执行文件。这条记录是 symbol file 的第一条记录。
- FILE: 这种记录用来记录源文件,包含有文件名及路径信息。这个类型的记录会被分配一个整形符号来作标记,然后在别的记录中可能会引用它。
- FUNC: 这种记录用来描述一个函数,包含函数名,函数在可执行文件中的地址等信息。
- 行记录: 这种记录用来描述,一个给定范围的机器指令对应哪个源文件的哪一行。行记录总是跟在FUNC记录后面,从而描述每个函数里的指令对应在源码里的位置。
- PUBLIC: 这种记录用来描述每一个链接符号的地址,如汇编函数里的各个入口点。
- STACK WIN: 这种记录用来描述函数调用时,函数帧(stack frame)的布局。有了这个记录,给定一特定的函数帧 F,就可以找到哪个函数帧调用了F。
- STACK CFI: CFI,就是 Call Frame Info,这种记录用来表述当执行到某条指令的时候,怎样去查看当前的函数调用栈。
上面主要讲了 symbol file 中的内容是怎样组织的,这里并不管其中的 symbol 是来自 DWARF,还是 STABS,这也正是 breakpad 定制自己的 symbol 格式的意义所在。
(3) processor module.
前面所介绍的两个模块,分别输出了 coredump,及 symbol file。这里要介绍的 processor 模块,它的作用就是根据 coredump 及 symbol file,构建出可读的 call stack. stackwalking 从 MinidumpProcessor 这个类开始,入口函数 MinidumpProcessor::Process() 以 symbol file,minidump file 为参数。
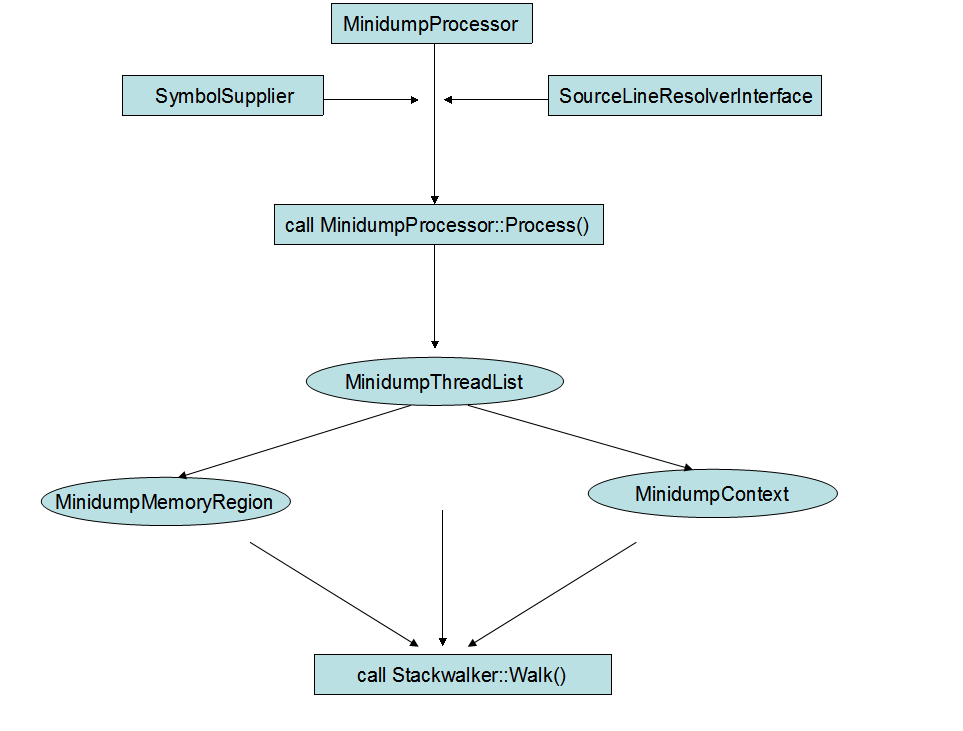
需要说明的是,stack walking 是针对每一个线程进行的。minidump 中保存了每个线程运行时的相关信息,这些信息都会在 Process()函数中被提取出来。MinidumpMemoryRegion 包含着线程的调用栈,MinidumpContext 包含着线程的 cpu context。stackwalking 开始时,Stackwalker::Walk() 根据不同的cpu,构建出当前线程的 top frame,也就是函数调用的最顶一层。然后从 top frame 开始,对整个调用栈的栈帧进行解析,解析的过程,包含有几方面的内容:
(a) 查找模块
根据当前帧的 eip(x86) 来调用 CodeModules::GetModuleForAddress() 返回当前 frame 所属的模块信息。
(b) 定位符号
前面找到模块后,找到只是二进制相关的信息。要找到这个模块相应的名字及模块里其它函数,变量的名字等,还需要用到之前 symbole file.这里需要注意的是,symbol file 可能不止一个,因此需要能够根据当前的模块来定位到,与这个模块相关的 symbol file 是哪个。SimpleSymbolSupplier 这个类就是用来做这个事情,它会结合当前模块的信息,定位到与当前 module 相关的 symbol file。
(c) 查找符号
前面一步找到了 symbol file。这里就需要根据 symbol file 来输出具体的符号。SourceLineResolverInterface 这个类的 LoadModuleUsingMemoryBuffer() 用来把 symbol file 加载进内存,并解析。BasicSourceLineResolver 这个类则是提供对外的接口,用于根据某个地址,查找出对应的符号名字,如,输入一个函数地址,返回函数的名字。
(d) 查找出当前帧的调用帧
当前帧解析完后,需要继续去解析调用当前帧的父帧。要做到这件事情,必须要有 symbol file 的支持。回忆一下,symbol file 中有二种记录类型:stack win,stack cfi。这两种类型的记录完整的描述了各类函数调用的栈帧布局,因此借助这些记录理论上就可以找回当前帧的调用帧。SourceLineResolverInterface就是用来做这些事情。具体可以查看它的成员函数,FindWindowsFrameInfo() 及FindCFIFrameInfo()。
总结
工欲善其事必先利其器,对程序开发来说,尤其如此,好的工具常常能对我们的工作起到事半工倍的作用,而对于工具的使用我们不应仅仅满足于知道怎么用,知其然也要能知其所以然,学习和分析别人的工具是怎么做出来的,不仅能帮助我们更好地理解和使用这些工具,更重要的是能帮助我们开阔视野和增长知识。前文对 breakpad 在 linux 平台下的实现做了简单介绍,从中我们可以看出一个完善的工具链实现起来是一项浩大的工程,涉及到许多方方面面的知识,里面可以学习的东西很多,需要完善的东西也很多,breakpad 作为一个开源项目,现在仍处在开发和完善的过程中,回馈开源的最好方式就是加入其中贡献你的力量,希望本文能对有兴趣的读者有帮助。