当层数较多时,梯度的计算也容易出现消失或爆炸
随机初始化模型参数
在神经网络中,通常需要随机初始化模型参数。下面我们来解释这样做的原因。
回顾多层感知机一节描述的多层感知机。为了方便解释,假设输出层只保留一个输出单元o1(删去o2和o3以及指向它们的箭头),且隐藏层使用相同的激活函数。如果将每个隐藏单元的参数都初始化为相等的值,那么在正向传播时每个隐藏单元将根据相同的输入计算出相同的值,并传递至输出层。在反向传播中,每个隐藏单元的参数梯度值相等。因此,这些参数在使用基于梯度的优化算法迭代后值依然相等。之后的迭代也是如此。在这种情况下,无论隐藏单元有多少,隐藏层本质上只有1个隐藏单元在发挥作用。因此,正如在前面的实验中所做的那样,我们通常将神经网络的模型参数,特别是权重参数,进行随机初始化。
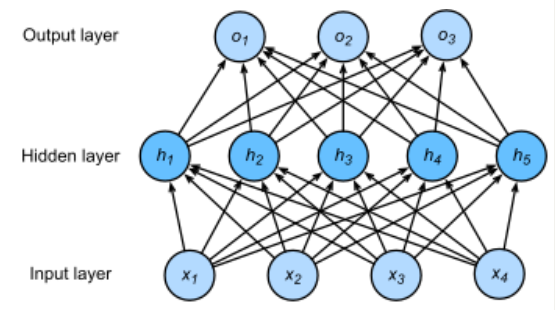
PyTorch的默认随机初始化
随机初始化模型参数的方法有很多。在线性回归的简洁实现中,我们使用torch.nn.init.normal_()使模型net的权重参数采用正态分布的随机初始化方式。不过,PyTorch中nn.Module的模块参数都采取了较为合理的初始化策略
Xavier随机初始化
还有一种比较常用的随机初始化方法叫作Xavier随机初始化。 假设某全连接层的输入个数为a,输出个数为b,Xavier随机初始化将使该层中权重参数的每个元素都随机采样于均匀分布
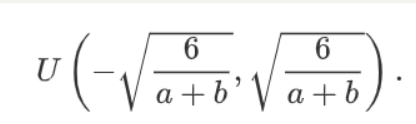
它的设计主要考虑到,模型参数初始化后,每层输出的方差不该受该层输入个数影响,且每层梯度的方差也不该受该层输出个数影响。
环境因素
协变量偏移:
统计学家称这种协变量变化是因为问题的根源在于特征分布的变化(即协变量的变化)。数学上,我们可以说P(x)改变了,但P(y∣x)保持不变。尽管它的有用性并不局限于此,当我们认为x导致y时,协变量移位通常是正确的假设。
标签偏移 --- y导致了x
病因(要预测的诊断结果)导致 症状(观察到的结果)
些方法倾向于操作看起来像标签的对象,这(在深度学习中)与处理看起来像输入的对象(在深度学习中)相比相对容易一些
概念偏移
例如,地理位置不同,同一件东西的定义不同
#函数
iloc() 提取列数据
concat() 主要是根据索引进行行或列的拼接,只能取行或列的交集或并集。 https://www.cnblogs.com/laiyaling/p/11798046.html
fillna() 用常数补充 https://blog.csdn.net/weixin_39549734/article/details/81221276
get_dummies() 用作特征提取 https://blog.csdn.net/u010712012/article/details/83002388
算法