前言
Python官方教程(https://docs.python.org/3/tutorial/)
本书的源码(https://github.com/fluentpython/example-code)
第2章:序列构成的数组
我们把文本、列表和表格叫做数据火车······
2.1 内置序列类型概览
容器序列:(存放的是它们所包含的任意类型的对象的引用)
list、tuple和collections.deque这些序列能存放不同类型的数据。
扁平序列:(存放的是值而不是引用)
str、bytes、bytearray、memoryview和array.array,这类序列只能容纳一种类型。
扁平序列其实更加紧凑,但是它里面只能存放诸如字符、字节和数值这种基础类型。
序列类型还能按照能否被修改来分类。
可变序列:
list、bytearray、memoryview、array.array和collections.deque
不可变序列:
tuple、str、bytes
list是一个可变序列,并且能同时存放不同类型的元素。
2.2 列表推导和生成器表达式
列表推导是构建列表的快捷方式,而生成器表达式则可以用来创建其他任何类型的序列。
2.2.1 列表推导和可读性
例1,把字符串变成Unicode码位的列表:(两种方法对比可读性)
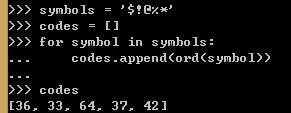

ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
2.2.2 列表推导同filter和map的比较
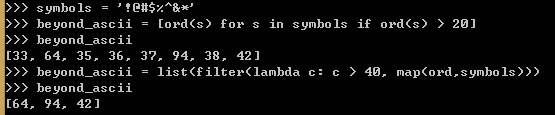
https://www.cnblogs.com/shaosks/p/9449540.html
2.2.3 笛卡尔积
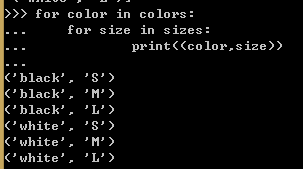
例2,使用列表推导计算笛卡尔积


第一处,得到的结果使按照先以颜色排列,再以尺码排列。
第二处,两个嵌套关系和上面列表推导中for从句的先后顺序一样。

第三处,先以尺码排序,再按照颜色。只需要调整从句的顺序。
2.2.4 生成器表达式
例3,用生成器表达式初始化元组和数组

如果生成器表达式是一个函数调用过程中的唯一参数,那么不需要额外再用括号把它围起来。

array的构造方法需要两个参数,因此括号是必要的。array构造方法的第一个参数指定了数组中数字的存储方式。
例4,使用生成器表达式计算笛卡尔积
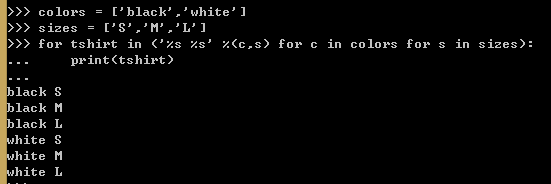
生成器表达式会在每次for循环运行时才生成一个组合,生成器表达式逐个产出元素,从来不会一次性产出一个含有6个T恤样式的列表。
2.3 元组不仅仅是一个不可变的列表
2.3.1 元组和记录
例 5,把元祖用作记录
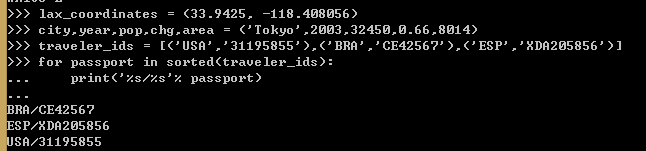
%格式运算符能够被匹配到对应的元组元素上。
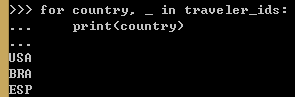
for循环可以提取元组的元素,也叫做拆包。因为元组中第二个元素对我们没有用,所以它赋值给“_”占位符。
2.3.2 元组拆包
元组拆包可以应用到任何可迭代对象上,唯一的硬性要求是,被可迭代对象中的元素数量必须要跟接受这些元素的元组的空档数一致。除非用*来代替。
最好辨认的元组拆包形式就是平行赋值。b,a = a,b
还可以用*运算符把一个可迭代对象拆开作为函数的参数:
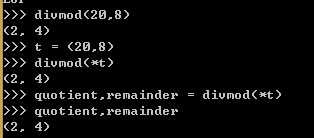
python divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)
下面是另一个例子,这里元组拆包的用法是让一个函数可以用元组的形式返回多个值,然后调用函数的代码就能轻松地接受这些返回值。比如os.path.split()函数就会返回以路径和最后一个文件名组成的元组(path,last_part):

注意:如果做的是国际化软件,那么_可能不是一个理想的占位符。
用*来处理剩下的元素
在Python中,函数*args来获取不确定数量的参数算是一种经典写法了。
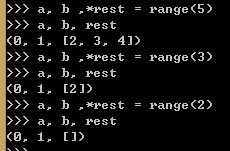
在平行赋值中,*前缀只能用在一个变量名前面,但是这个变量可以出现在赋值表达式的任意位置。
2.3.3 嵌套元组拆包
例6,用嵌套元组来获取精度
metro_areas = [ # 每个元组内有4个元素,其中最后一个元素是一对坐标。 ('Tokyo','JP',36.933,(35.689722,139.691667)), ('Delhi NCR','IN',21.935,(28.613889,77.208889)), ('Mexico City','MX',20.142,(19.433333,-99.133333)), ('New York-Newark','US',20.104,(40.808611,-74.020386)), ('Sao Paulo','BR',19.649,(-23.547778,-46.635833)), ] print('{:15} | {:^9} | {:^9}'.format('','lat.','long.')) fmt = '{:15} | {:9.4f} | {:9.4f}' # 我们把输入元组的最后一个元素拆包到由变量构成的元组里,这样就获取了坐标。 for name,cc,pop,(latitude,longitude) in metro_areas: # 条件判断把输出限制在西半球的城市里 if longitude <= 0: print(fmt.format(name,latitude,longitude))
| lat. | long. Mexico City | 19.4333 | -99.1333 New York-Newark | 40.8086 | -74.0204 Sao Paulo | -23.5478 | -46.6358
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
基本语法是通过 {} 和 : 来代替以前的 % 。
format 函数可以接受不限个参数,位置可以不按顺序。
https://www.runoob.com/python/att-string-format.html
2.3.4 具名元组
collection.nameduple是一个工厂函数,他可以用来构建一个带字段名的元组和一个有名字的类。
例7,定义和使用具名元组
from collections import namedtuple # 创建一个具名元组需要两个参数,一个是类名,另一个是类的各个字段的名字。 #后者可以是由数个字符组成的可迭代的对象,或者是由空格分隔开的字段名组成的字符串。 City = namedtuple('City','name country population coordinates') # 存放在对应字段里的数据要以一串参数的形式传入到构造函数中 # (注意元组的构造函数却只接受单一的可迭代的对象) tokyo = City('Tokyo','JP',36.933,(35.689722,139.691667)) print(tokyo) print(tokyo.population) print(tokyo.coordinates) print(tokyo[1])
City(name='Tokyo', country='JP', population=36.933, coordinates=(35.689722, 139.691667)) 36.933 (35.689722, 139.691667) JP
除了从普通元组那里继承来的属性外,具名元组还有一些自己专有的属性。例如_fields类属性、类方法_make(iterable)和实例方法_asdict()。
>>> from collections import namedtuple >>> City = namedtuple('City','name country population coordinates') >>> tokyo = City('Tokyo','JP',36.933,(35.689722,139.691667)) >>> City._fields ('name', 'country', 'population', 'coordinates') >>> LatLong = namedtuple('LatLong','lat long') >>> delhi_data = ('Delhi NCR','IN',21.935,(28.613889,77.208889)) >>> delhi = City._make(delhi_data) >>> delhi._asdict() OrderedDict([('name', 'Delhi NCR'), ('country', 'IN'), ('population', 21.935), ('coordinates', (28.613889, 77.208889))]) >>> for key,value in delhi._asdict().items(): ... print(key +':',value) ... name: Delhi NCR country: IN population: 21.935 coordinates: (28.613889, 77.208889)
_fields类属性:是一个包含这个类所有字段名称的元组。
_make(iterable)方法:可通过接收一个可迭代对象来生成这个类的一个实例,它的作用跟City(*delhi_data)是一样的。
_asdict()把具名元组以collection.OrderedDict的形式返回。
2.3.5 作为不可变列表的元组
方法或属性 列表 元组 含义 s.__add__(s2) 有 有 s+s2 s.__iadd__(s2) 有 s+=s2 s.apppend(e) 有 尾部新加一个元素 s.clear() 有 删除所有元素 s.__contains__(e) 有 有 s是否包含了e s.copy() 有 列表的浅拷贝 s.count(e) 有 有 e在s中出现的次数 s.__delitem__(p) 有 把位于p的元素删除了 s.extend(it) 有 把可迭代的对象it追加个s s.__getnewargs__() 有 在pickle中支持更加优化的序列化 s.index(e) 有 有 在s中找到元素e第一次出现的位置 s.insert(p,e) 有 在位置p之前插入元素e s.__iter__() 有 有 获取s的迭代器 s.__len__() 有 有 s.__mul__(n) 有 有 s*n,n个s重复拼接 s.__imul__(n) 有 就地n次拼接 s.__rmul__(n) 有 有 n*s,反向拼接 s.pop([p]) 有 删除最后一个,或者指定p位置的元素。可选p s.remove(e) 有 删除s中第一次出现的e s.reverse() 有 原地把s的元素倒序排列 s.__reversed__() 有 返回s的倒序迭代器 s.__setitem__(p,e) 有 s[p]=e,把元素放在位置p上,替代原来的那个位置 s.sort([key],[reverse]) 有 就地对s中元素进行排序。可选key或是否倒序reverse
2.4 切片
2.4.1 为什么切片和区间会忽略最后一个元素
当只有最后一个位置信息时,我们也可以快速看出切片和区间里有几个元素:range(3)和my_list[:3]都返回3个元素。
当起止位置信息都可见时,可以快速计算出切片和区间的长度,用后一个数减去第一个下标(stop-start)
2.4.2 对对象进行切片
可以用s[a:b:c]的形式对s在a和b之间以c为间隔取值。c的值还可以为负,负值意味着反向取值。
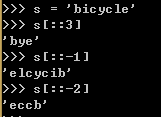
2.4.3 多维切片和省略
[]运算符里还可以使用以逗号分开的多个索引或者是切片,外部库NumPy里就用了这个特性,二维的numpy.darray就可以用a[i,j]这种形式,抑或是用a[m:n, k:l]的方式来得到二维切片。
省略(ellipsis)的正确书写方法是三个英语句号,而不是Unicdoe码位U+2026表示的半个省略号。
2.4.4 给切片赋值
>>> l = list(range(10)) >>> l [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> l[2:5] = [20,30] >>> l [0, 1, 20, 30, 5, 6, 7, 8, 9] >>> del l[5:7] >>> l [0, 1, 20, 30, 5, 8, 9] >>> l[3::2] = [11,22] >>> l [0, 1, 20, 11, 5, 22, 9] >>> l[2:5] = 100 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can only assign an iterable >>> l[2:5] = [100] >>> l [0, 1, 100, 22, 9]
如果赋值的对象是一个切片,那么赋值语句的右侧必须是个可迭代对象,即便只有单独一个值。
2.5 对序列使用+和*
+和*都遵循这个规律,不修改原有的操作对象,而是构建一个全新的序列。
>>> my_list = [[1,2,3]]*3 >>> my_list [[1, 2, 3], [1, 2, 3], [1, 2, 3]] >>> my_list = [1,2,3]*3 >>> my_list [1, 2, 3, 1, 2, 3, 1, 2, 3]
建立由列表组成的列表
例8,一个包含3个列表的列表,嵌套的3个列表各自有3个元素来代表井字游戏的一行方块
>>> board = [['_']*3 for i in range(3)] >>> board [['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']] >>> board[1][2]='X' >>> board [['_', '_', '_'], ['_', '_', 'X'], ['_', '_', '_']]
>>> board = [] >>> for i in range(3): ... row=['_']*3 ... board.append(row) ... >>> board [['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']] >>> board[2][0]='X' >>> board [['_', '_', '_'], ['_', '_', '_'], ['X', '_', '_']]
每次迭代都新建一个列表,作为新的一行(row)追加到游戏板(board)。
例9,含有3个指向同一对象的引用的列表是毫无用处的
>>> weird_board = [['_']*3]*3 >>> weird_board [['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']] >>> weird_board[1][2] = '0' >>> weird_board [['_', '_', '0'], ['_', '_', '0'], ['_', '_', '0']]
>>> row = ['_'] * 3 >>> board = [] >>> for i in range(3): ... board.append(row) ... >>> board [['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']] >>> board[1][2]='0' >>> board [['_', '_', '0'], ['_', '_', '0'], ['_', '_', '0']]
追加同一行对象(row)3次到游戏板(board),还是同样错误。
2.6 序列的增量赋值
*= 在可变和不可变序列上的作用:
>>> l=[1,2,3] >>> id(l) 1026421080520 >>> l*=2 >>> l [1, 2, 3, 1, 2, 3] >>> id(l) 1026421080520 >>> t = (1,2,3) >>> id(t) 1026421045288 >>> t *=2 >>> t (1, 2, 3, 1, 2, 3) >>> id(t) 1026420926024
对不可变序列进行重复拼接操作的话,效率会很低,因为每次都有一个新对象,而解释器需要把原来对象中的元素先复制到新的对象里,然后再追加新的元素。
一个关于+=的谜题
例10,一个谜题
>>> t = (1,2,[30,40])
>>> t[2] += [50,60]
会发生下面4种情况中的哪一种?
a.t变成(1, 2, [30, 40, 50, 60])。
b.因为tuple不支持它的元素赋值,所以会抛出TypeError 异常。
c.以上两个都不是
d.a和b都对
笔者选择的是a,但是答案其实是d。
例11,结果:t[2]被改动了,但是也有异常抛出
>>> t = (1,2,[30,40]) >>> t[2] += [50,60] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>> t (1, 2, [30, 40, 50, 60])
例12, s[a] +=b 背后的字节码
>>> import dis >>> dis.dis('s[a] += b') 1 0 LOAD_NAME 0 (s) 2 LOAD_NAME 1 (a) 4 DUP_TOP_TWO 6 BINARY_SUBSCR 8 LOAD_NAME 2 (b) 10 INPLACE_ADD 12 ROT_THREE 14 STORE_SUBSCR 16 LOAD_CONST 0 (None) 18 RETURN_VALUE
经验:
- 不要把可变对象放在元组里。
- 增量赋值不是一个原子操作。虽然抛出异常,但还是完成了操作。
- 查看Python的字节码并不难,而且它对我们了解代码背后的运行机制很有帮助。
2.7 list.sort方法和内置函数sorted
list.sort方法会就地排序列表,也就是说不会把原列表复制一份,这也是这个方法返回值是None的原因。
Python的一个惯例:如果一个函数或者方法对对象进行的是就地改动,那它就应该返回None,好让调用者知道传入的参数发生了变动,而且为产生新的对象。
与 list.sort方法相反的是内置函数sorted,它会新建一个列表作为返回值。
不管是list.sort方法还是sorted函数,都有两个可选的关键字参数。
reverse
默认值为False,如果被设定为True,被排序的序列里的元素会以降序输出。
key
一个只有一个参数的函数,这个函数会被用在序列里的每一个元素上,所产生的结果将是排序算法依赖的对比关键字。
比如说,在对一些字符串排序时,可以用key=str.lower 来实现忽略大小写的排序,或者是kye=len进行基于字符串长度的排序。默认值是恒等函数,也就是默认用元素自己的值来排序。
2.8 用bisect来管理已排序的序列
bisect模块包含两个主要函数,bisect和insort,两个函数都利用二分查找算法来在有序序列中查找或插入元素。
2.8.1 用bisect来搜索
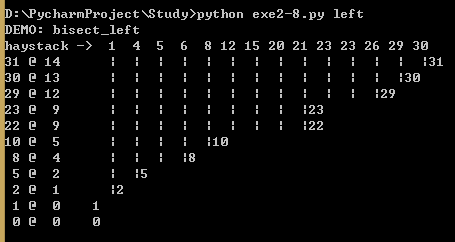
例13,在有序序列中用bisect查找某个元素的插入位置。
import bisect import sys HAYSTACK = [1,4,5,6,8,12,15,20,21,23,23,26,29,30] NEEDLES = [0,1,2,5,8,10,22,23,29,30,31] # 说明 format格式化函数 #{0:2d} 第0个参数宽度为2 #{1:2d} 第1个参数宽度为2 #{2} 第2个参数 #{0:<2d} 第0个参数,填充右边,宽度为2 #d为输出整数的十进制方式 ROW_FMT = '{0:2d} @ {1:2d} {2}{0:<2d}' def demo(bisect_fn): for needle in reversed(NEEDLES): # 用特定的bisect函数来计算元素应该出现的位置 possition = bisect_fn(HAYSTACK,needle) # 利用该位置来算出需要几个分隔符号 offset = possition * ' |' # 把元素和其应该出现的位置打印出来 print(ROW_FMT.format(needle,possition,offset)) if __name__ == '__main__': # 根据命令上最后一个参数来选用bisect函数 if sys.argv[-1] == 'left': bisect_fn = bisect.bisect_left else: bisect_fn = bisect.bisect # 把选定的函数在抬头打印出来 print('DEMO:',bisect_fn.__name__) print('haystack ->',' '.join('%2d' % n for n in HAYSTACK)) demo(bisect_fn)
DEMO: bisect haystack -> 1 4 5 6 8 12 15 20 21 23 23 26 29 30 31 @ 14 | | | | | | | | | | | | | |31 30 @ 14 | | | | | | | | | | | | | |30 29 @ 13 | | | | | | | | | | | | |29 23 @ 11 | | | | | | | | | | |23 22 @ 9 | | | | | | | | |22 10 @ 5 | | | | |10 8 @ 5 | | | | |8 5 @ 3 | | |5 2 @ 1 |2 1 @ 1 |1 0 @ 0 0
bisect模块:https://www.cnblogs.com/skydesign/archive/2011/09/02/2163592.html
bisect的表现可以从两个方面来调教。
首先可以用它的两个可选参数——lo和hi——来缩小搜寻的范围。lo的默认值是0,hi的默认值是序列的长度,即len()作用于该序列的返回值。
其次,bisect函数其实是bisect_right函数的别名,与bisect_left的区别在于,bisect_left返回的插入位置是原序列中跟被插入元素相等的元素的位置,也就是新元素会被插入到它想等元素的前面,而bisect_right返回的则是跟他相等元素之后的位置。
下图显示的是biset_left运行上述示例的结果。
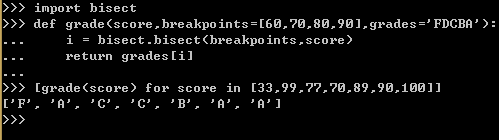
例14,根据一个分数,找到它所对应的成绩
2.8.2 用bisect.insort插入新元素
insort(seq,item)把变量item插入到序列seq中,并能保持seq的升序顺序。
import bisect import random SIZE = 7
#当我们设置相同的seed,每次生成的随机数相同。如果不设置seed,则每次生成不同的随机数
random.seed(1729) my_list = [] for i in range(SIZE): new_item = random.randrange(SIZE*2) bisect.insort(my_list,new_item) print('%2d ->' % new_item,my_list)
10 -> [10] 0 -> [0, 10] 6 -> [0, 6, 10] 8 -> [0, 6, 8, 10] 7 -> [0, 6, 7, 8, 10] 2 -> [0, 2, 6, 7, 8, 10] 10 -> [0, 2, 6, 7, 8, 10, 10]
2.9 当列表不是首选时
如果在你的代码里,包含操作(比如检查一个元素是否出现在一个集合中)的频率很高,用set会更合适。set专为检查元素是否存在做过优化。但是它不是序列,因为set是无序的。
2.9.1 数组
如果我们需要一个只包含数字的列表,那么array.array比list更高效。
例15,一个浮点型数组的创建、存入文件和文件读取的过程。
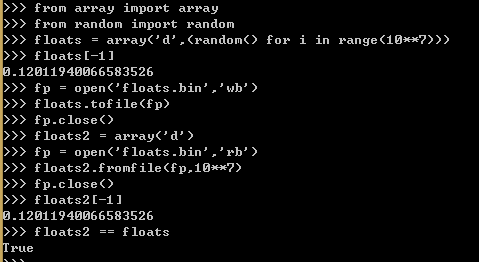
用array.fromfile从一个二进制文件里读出1000万个双精度浮点数只需要0.1秒,这比从文本文件里读取的速度要快60倍,因为后者会使用内置的float方法把每一行文字转换成浮点数。另外使用array.tofile写入到二进制文件,比每一行一个浮点数的方式把所有数字写入到文本文件要快7倍。
另一个快速序列化数字类型的方法是使用pickle(https://docs.python.org/3/library/pickle.html)模块。pickle.dump处理浮点数组的速度几乎跟array.tofile一样快。不过前者可以处理几乎所有的内置数字类型,包含复数、嵌套集合,甚至用户自定义的类。前提是这些类没有什么特别复杂的实现。
列表和数组的属性和方法
# 列表 数组 #s.__add(s2)__ • • s + s2 ,拼接 #s.__iadd(s2)__ • • s += s2 ,就地拼接 #s.append(e) • • 在尾部添加一个元素 #s.byteswap • 翻转数组内每个元素的字节序列,转换字节序 #s.clear() • 删除所有元素 #s.__contains__(e) • • s 是否含有e #s.copy() • 对列表浅复制 #s.__copy__() • 对copy.copy 的支持 #s.count(e) • • s 中e 出现的次数 #s.__deepcopy__() • 对copy.deepcopy 的支持 #s.__delitem__(p) • • 删除位置p 的元素 #s.extend(it) • • 将可迭代对象it 里的元素添加到尾部 #s.frombytes(b) • 将压缩成机器值的字节序列读出来添加到尾部 #s.fromfile(f, n) • 将二进制文件f 内含有机器值读出来添加到尾部,最多添加n 项 #s.fromlist(l) • 将列表里的元素添加到尾部,如果其中任何一个元素导致了TypeError 异常,那么所有的添加都会取消 #s.__getitem__(p) • • s[p],读取位置p 的元素 #s.index(e) • • 找到e 在序列中第一次出现的位置 #s.insert(p, e) • • 在位于p 的元素之前插入元素e #s.itemsize • 数组中每个元素的长度是几个字节 #s.__iter__() • • 返回迭代器 #s.__len__() • • len(s),序列的长度 #s.__mul__(n) • • s * n,重复拼接 #s.__imul__(n) • • s *= n ,就地重复拼接 #s.__rmul__(n) • • n * s ,反向重复拼接* #s.pop([p]) • • 删除位于p 的值并返回这个值,p 的默认值是最后一个元素的位置 #s.remove(e) • • 删除序列里第一次出现的e 元素 #s.reverse() • • 就地调转序列中元素的位置 #s.__reversed__() • 返回一个从尾部开始扫描元素的迭代器 #s.__setitem__(p, e) • • s[p] = e,把位 --------------------- 版权声明:本文为CSDN博主「renzao_ai」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/zt5169/article/details/90321352
从python3.4开始,数组类型不在支持list.sort()这种就地排序方法。要给数组排序的话,得用sorted函数新建一个数组:
a = array.array(a.typecode,sorted(a))
想要在不打乱次序的情况下为数组添加新元素,bisect.insort可以派上用场。
2.9.2 内存视图
mymoryview是一个内置类,它能让用户在不复制内容的情况下操作同一个数组的不同切片。
memoryview.cast的概念跟数组模块类似,能用不同的方式读写统一块内存数据,而且内容字节不会随意移动。memoryview.cast会把同一块内存里的内容打包成一个全新的memoryview对象给你。
例16,通过改变数组中的一个字节来更新数组里某个元素的值
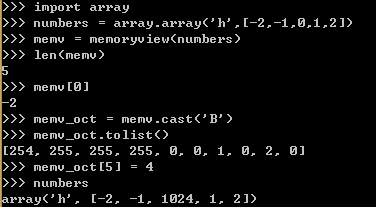
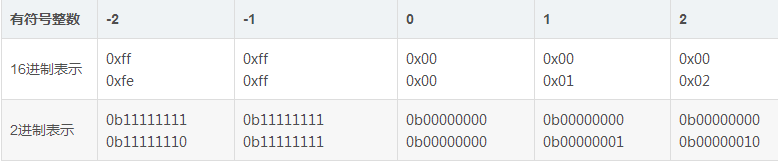
1、利用含有5个短整型有符号整数的数组(类型码是‘h’)创建一个memoryview。
2、memv里的5个元素跟数组里的没有区别。
3、创建一个memv_oct,这一次是把memv里的内容转换成‘B’类型,也就是无符号字符。
4、以列表的形式查看memv_oct的内容。
5、把位于位置5的字节赋值成4.
6、因为我们把占2个字节的整数的高位字节改变成了4,所以这个有符号整数的值就变成了1024
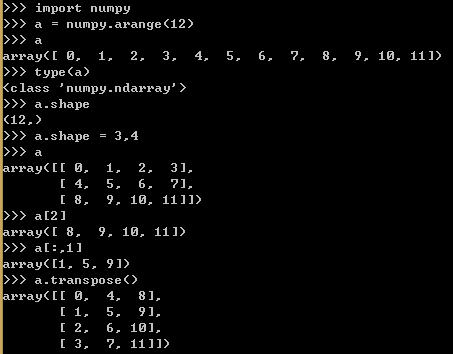
2.9.3 Numpy和Scipy
例17,对numpy.ndarray的行和列进行基本操作。
2.9.4 双向队列和其他形式的队列
collections.deque类是一个线程安全、可以快速从两端添加或者删除元素的数据类型。
例18,使用双向队列
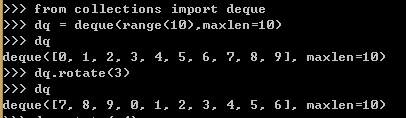
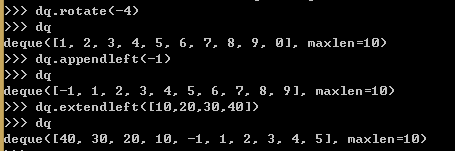
1、maxlen是一个可选参数,代表这个队列可以容纳的元素的数量。一旦设定就不能更改了。
2、队列的旋转操作接受一个参数n,当n>0时,队列的最右边的n个元素会被移动到队列的左边·····
3、当试图对一个已满的队列做头部添加操作的时候,它尾部的元素会被删掉。
4、extendleft(iter)方法会将迭代器里的元素逐个添加到双向队列的左边,因此迭代器里的元素会逆序出现在队列里。
列表和双向队列的方法(不包括由对象实现的方法):https://www.cnblogs.com/chengchengaqin/p/9523050.html