Storm在集群上运行一个Topology时,主要通过以下3个实体来完成Topology的执行工作:
1. Worker(进程)
2. Executor(线程)
3. Task
下图简要描述了这3者之间的关系: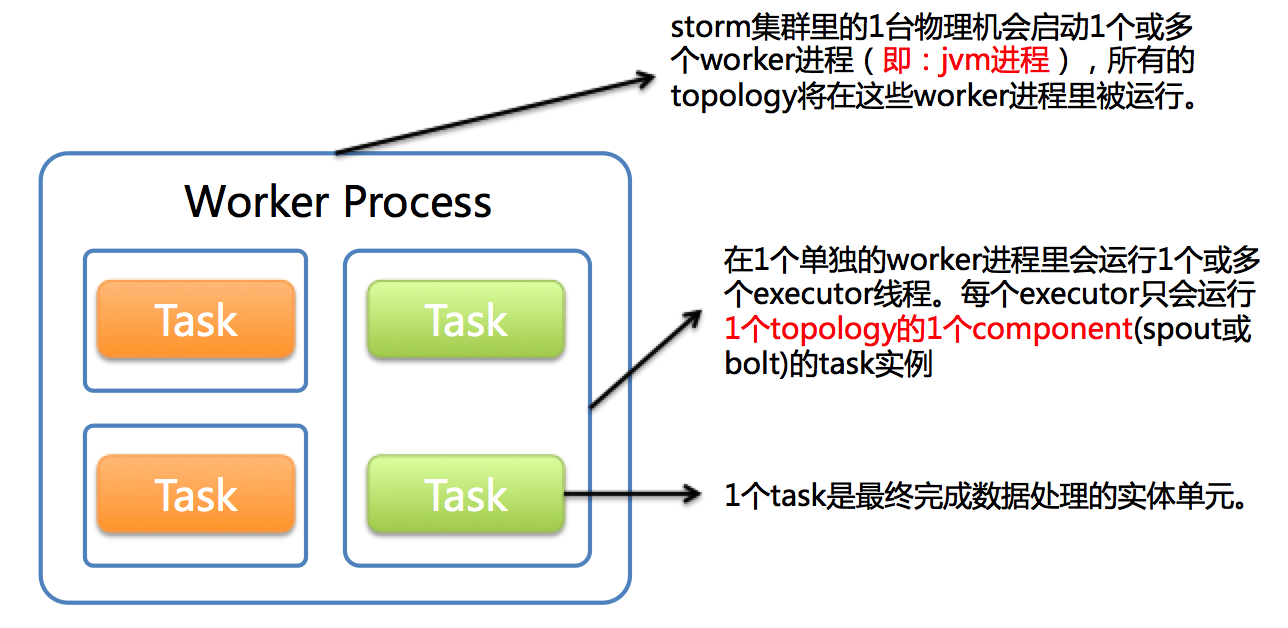
注:supervisor.slots.ports:对于每个工作节点配置该节点可以运行多少个worker进程。
每个worker进程使用一个但单独的端口来收取消息,这里配置了哪个端口用来使用。
定义5个端口,那么该节点上允许最多运行5个worker进程。
默认情况下,可以在端口6700, 6701, 6702, 6703四个端口最多运行四个worker进程。
如果我们不在这进行配置的话,这个参数也是有默认值的,有一个strom-core.jar,打开这个jar文件,在里面有一个defaults.yaml文件中是有一些默认配置的。
如下图:

Worker :
一个Worker 进程执行的是一个topology的子集,这里我们必须强调:不会存在一个worker 为多个topology服务,
一个worker进程会启动一个或则多个executor 线程来执行一个topology的compotent-》也就是Spout或者bolt,
一个topology就是由于集群中间的多台物理机上的Worker构成的
Workers (JVMs): 在一个节点上可以运行一个或多个独立的JVM 进程(配置多个端口时)。一个Topology可以包含一个或多个worker(并行的跑在不同的machine上), 所以worker process就是执行一个topology的子集, 并且worker只能对应于一个topology;worker processes的数目, 可以通过配置文件和代码中配置, worker就是执行进程, 所以考虑并发的效果, 数目至少应该大亍machines的数目。
默认情况下一个storm项目只使用一个work进程,也可以通过代码进行修改,通过config.setNumWorkers(workers)设置。(最好一台机器上的一个topology只使用一个worker,主要原因时减少了worker之间的数据传输)
注意:如果worker使用完的话再提交topology就不会执行,因为没有可用的worker,只能处于等待状态,把之前运行的topology停止一个之后这个就会继续执行了,
Executor:
一个executor是一个被Worker进程启动的单独线程,每一个Executor都只会运行一个topology的一个component,
默认情况:一个spout,或则一个bolt都只会生成一个task,Executor线程里会在每次 循环的时候 顺序的去调用所有的task的实例子
默认情况:一个executor对应一个task,可以通过配置文件,或者API来设置!
默认情况:一个executor运行一个task,可以通过在代码中设置builder.setSpout(id,spout, parallelism_hint);或者builder.setBolt(id,bolt,parallelism_hint);来提高线程数的。
Executors (threads): 在一个worker JVM进程中运行着多个Java线程。一个executor线程可以执行一个或多个tasks.
一般默认每个executor只执行一个task。
一个worker可用包含一个或多个executor, 每个component (spout或bolt)至少对应于一个executor, 所以可以说executor执行一个compenent的子集,
同时一个executor只能对应于一个component;executor的数目, component的并发线程数只能在代码中配置(通过setBolt和setSpout的参数)。
task:
通过boltDeclarer.setNumTasks(num);来设置实例的个数
默认情况下,一个supervisor节点会启动4个worker进程。每个worker进程会启动1个executor,每个executor启动1个task。
task是最终运行spout或bolt中代码的单元(注:1个task即为spout或bolt的1个实例,executor线程在执行期间会调用该task的nextTuple或execute方法)。
topology启动后,1个component(spout或bolt)的task数目是固定不变的,但该component使用的executor线程数可以动态调整(例如:1个executor线程可以执行该component的1个或多个task实例)。这意味着,对于1个component存在这样的条件:#threads<=#tasks(即:线程数小于等于task数目)。
默认情况下task的数目等于executor线程数目,即1个executor线程只运行1个task
Tasks(bolt/spout instances):Task就是具体的处理逻辑对象,每一个Spout和Bolt会被当作很多task在整个集群里面执行。
每一个task对应到一个线程,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。
可以调用TopologyBuilder.setSpout和TopBuilder.setBolt来设置并行度 — 也就是有多少个task,tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过
setNumTasks()配置。
注意:
1、并行度主要就是调整executor的数量,但是调整之后的executor的数量必须小于等于task的数量!
如果 分配的executor的线程数比task数量多的话也只能分配和task数量相等的executor
2、如果设置了多个task实例,但是并行度executor并没有很大提高!例如Spout只有两个线程(executor)去运行这些实例,是没有意义的,当然rebalance的时候用到!
rebalance不需要修改代码,就可以动态修改topology的并行度executor,这样的话就必须提前配置好多个(task)实例,在rebalance的时候主要是对之前设置多余的任务实例分配线程去执行。只有设置足够多的线程和实例才可以真正的提高并行度。
3、 worker是进程,executor对应于线程,spout或bolt是一个个的task
同一个worker只会执行同一个topology相关的task,即:一个worder执行一个topology的一部分task,因为topology由多台物理机上的worder构成的!
在同一个executor中可以执行多个同类型的task, 即在同一个executor中,要么全部是bolt类的task,要么全部是 spout类的task
运行的时候,spout和bolt需要被包装成一个又一个task
TASK的存在只是为了topology扩展的灵活性,与并行度无关。
总结一下:worker>executor>task 要想提高storm的并行度可以从三个方面来改造worker(进程)>executor(线程)>task(实例)增加work进程,增加executor线程,增加task实例!
第二:

上图中的3段话依次如下:
- Storm集群中的其中1台机器可能运行着属于多个拓扑(可能为1个)的多个worker进程(可能为1个)。每个worker进程运行着特定的某个拓扑的executors。
- 1个或多个excutor可能运行于1个单独的worker进程,每1个executor从属于1个被worker process生成的线程中。每1个executor运行着相同的组件(spout或bolt)的1个或多个task。
- 1个task执行着实际的数据处理。
1个worker进程执行一个拓扑的子集。1个worker进程从属于1个特定的拓扑,并运行着这个拓扑的1个或多个组件(spout或bolt)的1个或多个executor。一个运行中的拓扑包括集群中的许多台机器上的许多个这样的进程。
1个executor是1个worker进程生成的1个线程。它可能运行着1个相同的组件(spout或bolt)的1个或多个task。
1 个task执行着实际的数据处理,你用代码实现的每一个spout或bolt就相当于分布于整个集群中的许多个task。在1个拓扑的生命周期中,1个组 件的task的数量总是一样的,但是1个组件的executor(线程)的数量可以随着时间而改变。这意味着下面的条件总是成立:thread的数量 <= task的数量。默认情况下,task的数量与executor的数量一样,例如,Storm会在每1个线程运行1个task。
下面附上一段程序来说明:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5).setNumTasks(4); //executors数目设置为5,即线程数为5,task为4
builder.setBolt("split", new SplitSentence(), 8).shuffleGrouping("spout"); //executors数目设置为8,即线程数为8,task默认为1
builder.setBolt("count", new WordCount(), 4).fieldsGrouping("spout", new Fields("ming")); //executors数目设置为4,即线程数为4
Config conf = new Config();
conf.setDebug(false);
conf.setNumWorkers(3); //这里是设置Topology的Workers数
StormSubmitter.submitTopology("word-count", conf, builder.createTopology());
参考:http://blog.chinaunix.net/uid-28379365-id-5017449.html