RPN(Region Proposal Networks)架构:
图片来源于:http://blog.csdn.net/shenxiaolu1984/article/details/51152614
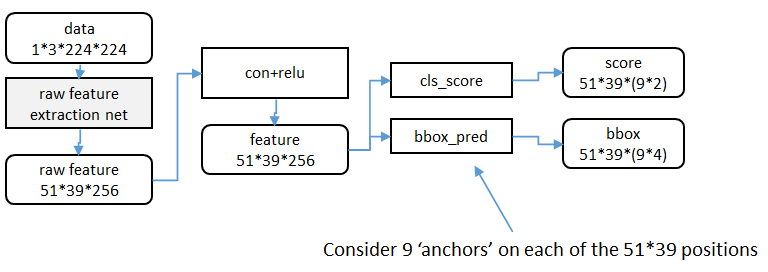
raw feature extraction net:
其中的原始特征提取可以用7层的ZF或者16层的VGG或者自己写的CNN网络。之后得到51*39*256的原始特征,再加一个卷积核大小为3*3的conv+relu层使得输出与原始特征相同的特征。(图片大小为51*39,因此3*3的感受野就够了,大了的话会丢失细节)
anchor:
特征可以看成有259个通道尺度为51*39的图像,对于该图像的每个位置,考虑9中尺寸的候选框,三种面积{128,256,512}和三种比例{1:1,1:2,2:1}
cls_score:
全连接网络,也可以看成是1*1的全连接层,因为要对每个位置进行处理,且共享参数,给出每个位置9个anchor属于目标还是背景的概率。
bbox_pre:
全连接网络,也可以看成是1*1的全连接层,因为要对每个位置进行处理,且共享参数,输出每个位置上9个anchor对应窗口应该平移缩放的参数。输出4个参数,包括box的中心坐标x和y,box宽w和长h。
ps:在实际代码中,将51*39*9个anchor根据得分排序,选择最高的一部分,再送入cls_score和bbox_pre层中。
RPN训练:
样本:
1)假如某anchor与任一ground-truth box的IoU最大,则该anchor判定为有目标;
2)假如某anchor与任一ground-truth box的IoU>0.7,则判定为有目标;
3)假如某anchor与任一ground-truth box的IoU<0.3,则判定为背景。
4)其余anchor丢弃。
因此一个ground-truth box可能对应多个anchor。通常情况下,第二种方法对正样本的确定较为有效,但是依旧要采取方法一的原因是在极少情况下方法二可能找不到正样本。
损失函数:
一个图像的损失函数分为两部分,一部分是cla_score的分类误差,另一部分是bbox的回归误差。
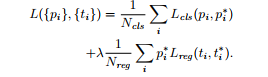 i 表示在anchor在mini-batch中的索引,pi 表示该anchor是正样本的概率,如果anchor为正样本ground-truth为正样本的概率pi*为1,反之则为0。ti 是含有与预测的bounding box有关的四个参数的向量,ti* 是正样本ground-truth box的参数向量。分类损失函数式log loss。Lreg (ti , ti*) = R (ti , ti*), R是Fast RCNN中定义的smooth L1。pi* Lreg 意为只对正样本的回归损失。
i 表示在anchor在mini-batch中的索引,pi 表示该anchor是正样本的概率,如果anchor为正样本ground-truth为正样本的概率pi*为1,反之则为0。ti 是含有与预测的bounding box有关的四个参数的向量,ti* 是正样本ground-truth box的参数向量。分类损失函数式log loss。Lreg (ti , ti*) = R (ti , ti*), R是Fast RCNN中定义的smooth L1。pi* Lreg 意为只对正样本的回归损失。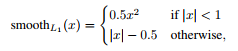
这两项损失函数通过Ncls和Nreg进行正则化,并且通过平衡参数λ进行加权处理。在实验中,cls部分正则化参数为mini-batch的大小,reg部分正则化的参数是anchor的位置,λ默认为10,因此这两部分的损失函数的权重大致相等。作者注意到,上面所提到的正则化不是必须的并且可以被简化。
对于bounding box回归,作者采用了四个参数:
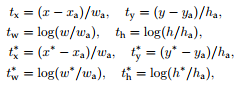
x,y,w,h 表示box的中心位置、宽和高。x,xa,x*分别指预测的box、anchor box和ground-truth box,这可以被认为bounding-box回归是从anchor到一个相近的ground-truth box。
RPNs的训练:
RPNs可以通过BP算法和SGD算法进行端到端的训练。每一个从一张图像得到的mini-batch包含许多正样本和负样本,在一张图像上随机选取256个anchor计算损失函数,其中正样本和负样本的比例是1:1。如果一个图像中的,正样本少于128,用负样本填充mini-batch。
用均值为0,标准差为0.01的高斯分布随机初始化所有新加入层的权重,其余层用预训练好的ImageNet分类模型的参数初始化。
RPN和Fast RCNN共享特征:
至此,描述了如何训练生成候选区域,并没有考虑基于区域的目标检测。下面描述RPN和有共享卷积层的Fast RCNN组成的联合网络。独立训练RPN和Fast RCNN会用不同的方法修改他们的卷积层。因此需要一种方法使得这两个网络共享卷积层参数。
方法1:训练RPN,使用proposals训练Fast RCNN,然后用Fast RCNN的参数初始化RPN,一直重复这个过程。
方法2:将RPN和Fast RCNN合并成一个网络,在每个SGD迭代中,在前向传播训练Fast RCNN的检测器时将生成的候选区域看成固定的,已经计算好的候选区。在反向传播正常进行,在共享层中反向传播信号来自于RPN和Fast RCNN损失的组合。
方法3:不想翻译
方法1的四步训练
第一步,用预训练好的分类模型初始化RPN并进行参数微调。
第二步,使用RPN产生的候选区域训练目标检测网络(Fast RCNN)。目标检测网络也是用与训练好的分类模型进行初始化。这时,这两个模型没有共享卷积层参数。
第三步,使用目标检测网络初始化RPN,但是固定共享卷积层,微调RPN不共享的层。
最后,保持共享卷积层的固定,微调,Fast RCNN中特有的层。
这个过程可以被重复很多次,但是作者观察到对模型性能的提高很微不足道。
还有好多,不想翻译,睡啦睡啦!
参考论文:Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in Neural Information Processing Systems. 2015.