SGD : stochastic gradient descent (随机梯度下降)
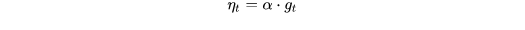
1. 更新比较频繁,会造成 cost function 有严重的震荡,最终停留在 local minima (极小值) 或 saddle point (鞍点) 处
def sgd(w, dw, config=None): if config is None: config = {} config.setdefault('learning_rate', 1e-2) w -= config['learning_rate'] * dw return w, config
SGDM : SGD with Momentum (动量)
Momentum在梯度下降的过程中加入了惯性,使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减小震荡。
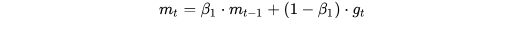
这种做法使得原来的值m(t-1)占一定的比重,新值占一定的比重,共同对新值m(t)作出影响。类似于网络书上的某个计算。记不清是什么了 : -_- :
1. 不具备一些先知(先验?),例如快要上坡时,就知道需要减速了,适应性会更好;
(个人理解:例如从一个很陡的坡下载,到达最低点,但是受动量影响,刹不住车,继续向前面的上坡冲)
2. 不能根据参数的重要性而对不同的参数进行不同程度的更新。
def sgd_momentum(w, dw, config=None): if config is None: config = {} config.setdefault('learning_rate', 1e-2) config.setdefault('momentum', 0.9) v = config.get('velocity', np.zeros_like(w)) next_w = None ########################################################################### # TODO: Implement the momentum update formula. Store the updated value in # # the next_w variable. You should also use and update the velocity v. # ########################################################################### v = config["momentum"] * v - config["learning_rate"] * dw next_w = w + v # momentum : 动量 ########################################################################### # END OF YOUR CODE # ########################################################################### config['velocity'] = v return next_w, config
NAG : SGD with Nesterov Acceleration (加速度)

计算梯度时,不是在当前位置,而是未来的位置上。因此这里的梯度是跟着累积动量走了一步后的梯度。
AdaGrad
二阶动量为该维度上迄今为止所有梯度值的平方和
为了避免分母为0,加了一项随机扰动
分母会不断积累,这样随着迭代次数的增加,步长越来越小
RMSProp
解决Adagrad学习率急剧下降的问题,RMSProp改变了二阶动量计算方法,即用窗口滑动加权平均值计算二阶动量。
Hinton 建议设定 为 0.9, 学习率
为 0.001。
def rmsprop(w, dw, config=None): if config is None: config = {} config.setdefault('learning_rate', 1e-2) config.setdefault('decay_rate', 0.99) config.setdefault('epsilon', 1e-8) config.setdefault('cache', np.zeros_like(w)) next_w = None ########################################################################### # TODO: Implement the RMSprop update formula, storing the next value of w # # in the next_w variable. Don't forget to update cache value stored in # # config['cache']. # ########################################################################### config["cache"] = config["decay_rate"]*config["cache"] + (1-config["decay_rate"])*(dw**2) next_w = w - config["learning_rate"]*dw / (np.sqrt(config["cache"]) + config["epsilon"]) pass ########################################################################### # END OF YOUR CODE # ########################################################################### return next_w, config
Adam
Adam = Adaptive + Momentum,顾名思义Adam集成了SGD的一阶动量和RMSProp的二阶动量。
优化算法里最常见的两个超参数 就都在这里了,前者控制一阶动量,后者控制二阶动量。
若在Adam基础上再加一个Nesterov加速,是不是更牛逼了,这就是Nadam。


def adam(w, dw, config=None): """ Uses the Adam update rule, which incorporates moving averages of both the gradient and its square and a bias correction term. config format: - learning_rate: Scalar learning rate. - beta1: Decay rate for moving average of first moment of gradient. - beta2: Decay rate for moving average of second moment of gradient. - epsilon: Small scalar used for smoothing to avoid dividing by zero. - m: Moving average of gradient. - v: Moving average of squared gradient. - t: Iteration number. """ if config is None: config = {} config.setdefault('learning_rate', 1e-3) config.setdefault('beta1', 0.9) # 0.9 config.setdefault('beta2', 0.999) # 0.995 config.setdefault('epsilon', 1e-8) config.setdefault('m', np.zeros_like(w)) config.setdefault('v', np.zeros_like(w)) config.setdefault('t', 0) next_w = None ########################################################################### # m -> first_moment # v -> second_moment config["t"] += 1 config["m"] = config["beta1"] * config["m"] + (1 - config["beta1"]) * dw config["v"] = config["beta2"] * config["v"] + (1 - config["beta2"]) * (dw**2) mb = config["m"] / (1 - config["beta1"]**config["t"]) vb = config["v"] / (1 - config["beta2"]**config["t"]) next_w = w - config["learning_rate"] * mb / ( np.sqrt(vb) + config["epsilon"] ) # END OF YOUR CODE # ########################################################################### return next_w, config
Reference :
https://blog.csdn.net/q295684174/article/details/79130666
https://blog.csdn.net/silent56_th/article/details/59680033