HDFS教程
在这个HDFS教程博客中继续前进之前,让我带您介绍一些与HDFS相关的疯狂统计信息:
- Facebook在2010年声称拥有存储21 PB数据的最大HDFS集群之一。
- 在2012年,Facebook宣布他们拥有最大的单个HDFS集群,数据量超过100 PB 。
- 和雅虎!在运行Hadoop的40,000多台服务器上拥有超过100,000个CPU,其最大的Hadoop集群运行4,500个节点。总而言之,雅虎!在HDFS中存储455 PB的数据。
- 事实上,到了2013年,“财富”50强中的大多数大牌都开始使用Hadoop了。
太难消化?对。正如Hadoop教程中所讨论的,Hadoop有两个基本单元 - S torage和Processing。当我说Hadoop的存储部分时,我指的是代表Hadoop分布式文件系统的HDFS。所以,在这个博客中,我将向您介绍 HDFS。
在这里,我将会谈到:
- 什么是HDFS?
- HDFS的优点
- HDFS的功能
在谈论HDFS之前,让我告诉你,什么是分布式文件系统?
DFS或分布式文件系统:
分布式文件系统讨论管理数据,即跨多台计算机或服务器的文件或文件夹。换句话说,DFS是一种文件系统,允许我们将数据存储在群集中的多个节点或机器上,并允许多个用户访问数据。所以基本上,它与您的机器中可用的文件系统具有相同的用途,例如用于具有NTFS(新技术文件系统)的Windows或用于具有HFS(分层文件系统)的Mac。唯一的区别是,在分布式文件系统的情况下,您将数据存储在多台机器而不是单台机器上。即使文件存储在整个网络中,DFS也可以组织和显示数据,使坐在机器上的用户感觉所有数据都存储在该机器中。
什么是HDFS?
Hadoop分布式文件系统或HDFS是基于Java的分布式文件系统,允许您在Hadoop集群中的多个节点上存储大量数据。因此,如果您安装Hadoop,您将HDFS作为底层存储系统来存储分布式环境中的数据。
我们举个例子来理解它。想象一下,你有十台机器或十台电脑,每台机器上有1TB的硬盘。现在,HDFS表示,如果您将Hadoop作为平台安装在这十台机器上,您将获得HDFS作为存储服务。Hadoop分布式文件系统以这样的方式分发,即每台机器都有自己的存储空间来存储任何类型的数据。
HDFS教程:HDFS的优点
1.分布式存储:

当您从Hadoop集群中的十台机器中的任何一台访问Hadoop分布式文件系统时,您会感觉到您已经登录到一台具有10 TB存储容量的大型机器(总计存储十台以上的机器)。这是什么意思?这意味着您可以存储一个10 TB的大文件,这个文件将分布在十台机器上(每个1 TB)。所以,它不限于每台机器的物理边界。
2.分布式和并行计算:
 由于数据在机器上分配,因此我们可以利用分布式和并行计算。让我们通过上面的例子来理解这个概念。假设在一台机器上处理1TB文件需要43分钟。那么,现在告诉我,如果在具有类似配置的Hadoop集群中有10台机器(43分钟或4.3分钟),处理相同的1TB文件需要多长时间?4.3分钟,对!这里发生了什么?每个节点并行处理1TB文件的一部分。因此,前四三分钟的工作,现在只需要四点三分钟完成,因为工作分了十几台机器。
由于数据在机器上分配,因此我们可以利用分布式和并行计算。让我们通过上面的例子来理解这个概念。假设在一台机器上处理1TB文件需要43分钟。那么,现在告诉我,如果在具有类似配置的Hadoop集群中有10台机器(43分钟或4.3分钟),处理相同的1TB文件需要多长时间?4.3分钟,对!这里发生了什么?每个节点并行处理1TB文件的一部分。因此,前四三分钟的工作,现在只需要四点三分钟完成,因为工作分了十几台机器。
3.水平可伸缩性:
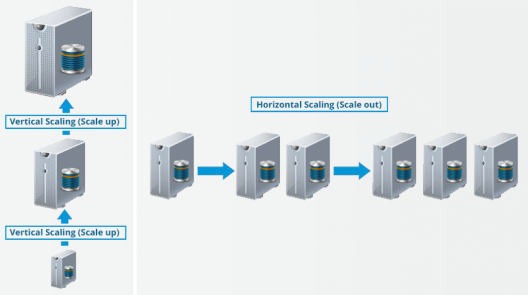
最后但并非最不重要的,让我们来讨论 一下Hadoop中的 横向扩展或扩展。有两种缩放比例:垂直和水平。在垂直缩放(放大)中,增加系统的硬件容量。换句话说,您购买更多的RAM或CPU,并将其添加到您的现有系统,使其更强大,更强大。但是,垂直缩放或扩大方面存在挑战:
- 总是有一个限制,你可以增加你的硬件容量。所以,你不能继续增加机器的RAM或CPU。
- 在垂直缩放中,您首先停止您的机器。然后增加内存或CPU,使其成为一个更强大的硬件堆栈。增加硬件容量后,重新启动机器。停机时停机成为一个挑战。
在水平缩放(横向扩展)的情况下,您可以向现有集群添加更多节点,而不是增加单个机器的硬件容量。而最重要的是,你可以添加更多的机器, 即不停止系统。因此,在扩大规模的同时,我们没有任何停机时间或绿色地带,没有任何类似的东西。在一天结束时,您将有更多的机器并行工作,以满足您的要求。
HDFS教程: HDFS的功能
当我们将在下一个HDFS教程博客中探索HDFS体系结构时,我们将详细了解这些功能。但是,现在让我们来看看HDFS的特性:
- 成本: 一般来说,HDFS部署在商用硬件上,例如您每天使用的台式机/笔记本电脑。所以,在项目的拥有成本方面是非常经济的。因为我们使用的是低成本的商品硬件,所以您无需花费大量资金来扩展Hadoop集群。换句话说,增加更多的节点到你的HDFS是成本效益的。
- 数据的种类和数量: 当我们谈论HDFS的时候,我们谈论的是存储巨大的数据,即TB级和PB级的数据和不同类型的数据。所以,您可以将任何类型的数据存储到HDFS中,无论是结构化的,非结构化的还是半结构化的。
- 可靠性和容错性: 当您将数据存储在HDFS上时,它会将给定的数据内部分割为数据块,并以分布的方式将其存储在Hadoop集群中。关于哪个数据块位于哪个数据节点上的信息被记录在元数据中。NameNode管理元数据, DataNode负责存储数据。
名称节点也复制数据,即维护数据的多个副本。数据的这种复制使得HDFS非常可靠和容错。因此,即使任何节点失败,我们也可以从驻留在其他数据节点上的副本中检索数据。默认情况下,复制因子为3.因此,如果将1 GB的文件存储在HDFS中,则最终将占用3 GB的空间。名称节点定期更新元数据并保持复制因子一致。
- 数据完整性: 数据完整性将讨论存储在我的HDFS中的数据是否正确。HDFS不断检查存储的数据的完整性与其校验和。如果发现任何错误,它会向名称节点报告。然后,名称节点创建额外的新副本,因此删除损坏的副本。
- 高吞吐量:吞吐量是单位时间内完成的工作量。它讨论了如何从文件系统访问数据的速度。基本上,它给你一个关于系统性能的见解。正如你在上面的例子中看到的那样,我们共用十台机器来增强计算。在那里我们能够将处理时间从 43分钟缩短到只有 4.3分钟,因为所有的机器都在并行工作。因此,通过并行处理数据,我们大大减少了处理时间,从而实现了高吞吐量。
- 数据局部性: 数据局部性讨论的是将处理单元移动到数据而不是数据到处理单元。在我们的传统系统中,我们曾经把数据带到应用层,然后进行处理。但是现在,由于数据的体系结构和庞大的数据量,把数据带到应用层会使网络性能显着降低。因此,在HDFS中,我们将计算部分带到数据所在的数据节点。因此,你不移动数据,你正在把程序或处理部分的数据。
所以现在,您对HDFS及其功能有一个简单的概念。但请相信我,这仅仅是冰山一角。在我的下一个HDFS教程博客中,我将深入探索HDFS 体系结构,并将揭开HDFS成功背后的秘密。我们将一起回答所有在你脑海中琢磨的问题,例如:
- 在Hadoop分布式文件系统中读取或写入数据时,幕后会发生什么?
- 像机架感知这样的算法是什么使得HDFS具有如此容错性?
- Hadoop分布式文件系统如何管理和创建副本?
- 什么是块操作?