FailOver
一、Flume简单介绍
Flume提供一个分布式的,可靠的,对大数据量的日志进行高效收集、聚集、移动的服务
1.1 FLume的基本组成
Flume的组件主要包括三个:Source、Channel、Sink,其前后关系如图1所示。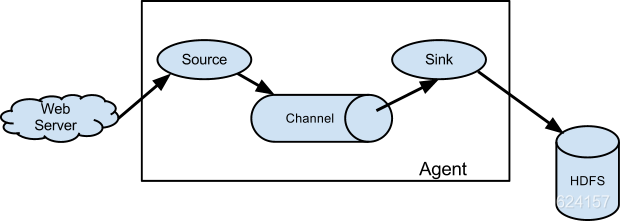
图1
1.2 Source
Source用来从数据源接收数据,并将数据写入到Channel中。
Source分很多种,现在公司内用到的有两个:
(1)KafkaSource:其用于从Kafka中获取数据
(2)TailDirSource:其可以读取本地磁盘文件中的数据,TailDirSource会在本地维护一个position文件,根据文件名字和文件的inode来记录所消费到的文件中的偏移量来记录数据消费到了哪个位置。当Flume挂掉重启时,会从当前偏移量继续消费。(注意:经过vim编辑过的文件inode会变更)
(3)AvroSource:这个Source会监听当前服务器的指定的端口,数据发送到这个端口就会被AvroSource收集
1.3 Channel
Channel是一个被动组件,Source将数据写入到Channel,Sink从Channel中读取数据,其就像一个队列。
Channel有两种:
(1)FileChannel:其会将进入Channel的数据持久化到磁盘上,当flume挂掉时,保证数据不会丢失
(2)MemoryChannel:数据在Channel中只在内存中进行传输,虽然性能上相比FileChannel较高,但是当flume挂掉时,而Channel中还有数据没有被消费完时,这部分数据将会丢失。
1.4 Sink
Sink是一个agent的输出组件,其将数据输送到目的地。
(1)HdfsSink:数据目的地是hdfs的Sink
(2)AvroSink:数据目的地是指定端口号的Sink
1.5 三个组件的对应关系(类型)
数据源于Source:1对1
Source与Channel:1对多
Channel与Sink:1对多
Sink与数据目的地:1对1
二、Flume HA
Flume HA不是完全的HA,其不依赖于第三方组件如zookeeper
2.1 Flume HA存在的必要性
现在flume的应用场景有:flume采集ng日志数据到hdfs、flume采集kafka数据到hdfs、flume采集ng日志数据到kafka。那么,当flume采集数据的时候由于不可预测的原因突然挂掉怎么办,所以,为了保障数据采集链路的正常运行,搭建flume的HA的架构是非常有必要的。
2.2 FLume如何可以做到HA来提高稳定性
2.2.1 如果数据源是本地文件?
如果要做到HA的话,FLume就要采用双层架构,如图2所示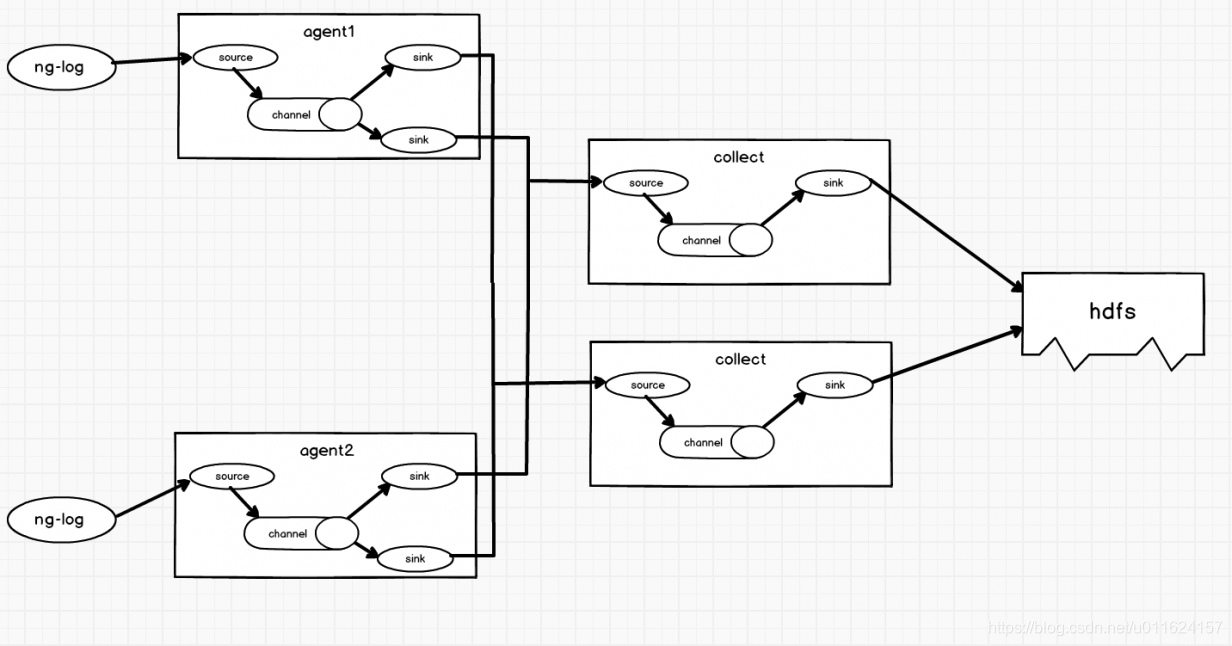
图2
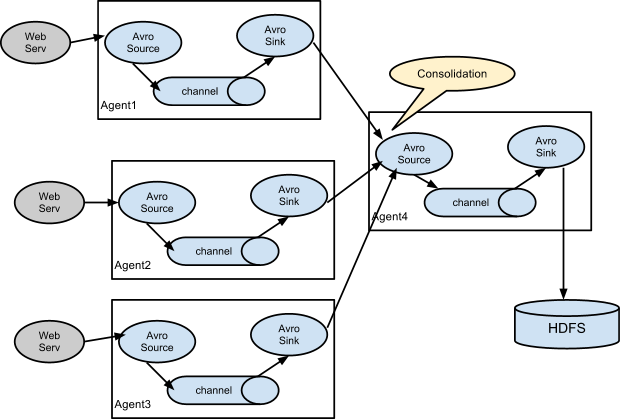
这个架构的关键在于第一层Flume的sink上。在第一层的的每个Flume的Channel上都会有两个Sink,这两个Sink消费的Channel的数据是负载均衡的,这两个Sink会分别向第二层的两个Collect发送数据。当第二层的FLume有其中一个挂了的时候,这个时候相应要给这个FLume发送数据的Sink就不会再发送数据了,数据都会集中在另一个Sink中,全部发送给第二层正常的Flume。
那么如果第一层的FLume有其中一个挂掉了怎么办。很遗憾,只能及时的重启它并保持正常。因为ng同样需要做负载均衡,如果第一层的FLume挂掉其中一个,那么打到对应ng日志服务器上的日志在FLume这一环节就会缺失。
2.2.2 如果数据源是Kafka?
对于数据源是Kafka的情况,有两种部署方式,第一种就是如上面提到的双层架构,那么第二种可以利用Kafka的消费者本身的特性。相比于第一种,第二种无疑更加简洁。
消费Kafka的数据的客服端成为Kafka的消费者,Kafka的消费者有一个重要的特性,对于同组的消费者来说,其消费的相同topic下的数据是互斥的,可以简单理解为,如果有同组的两个消费者去消费同一个topic的数据,在特定情况下(topic的分区是偶数个),这两个消费者会平分消费topic中的数据。架构图如图3所示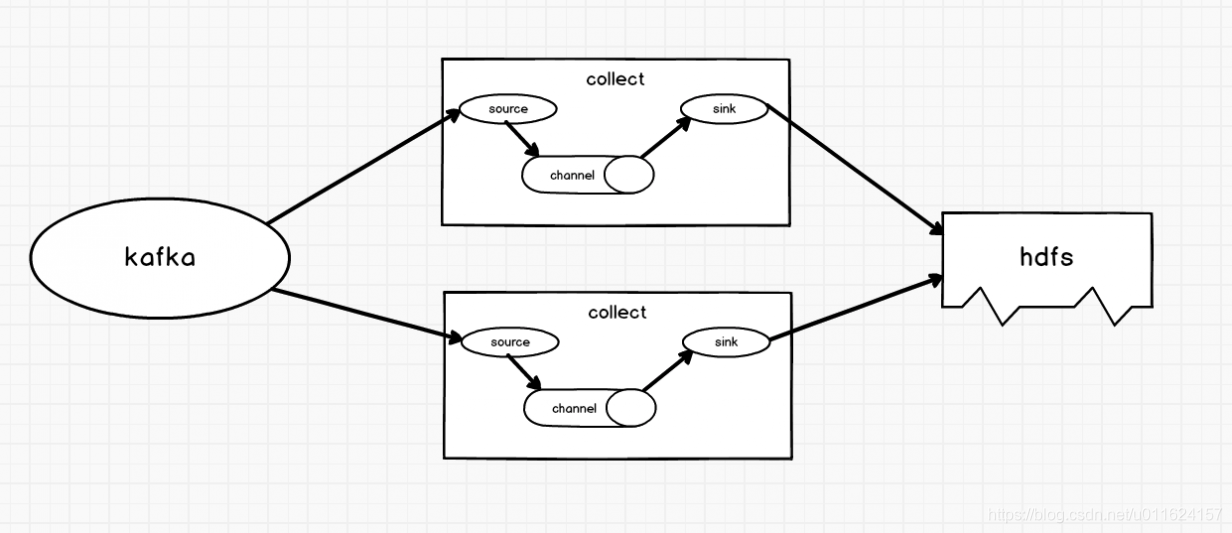
图3
同时启动多个FLume去消费Kafka的数据,当有其中一个Flume挂掉时,数据的消费权会重新分配而保证数据可以继续正常消费。
2.3 如此架构对数据有什么影响
(1)消费效率:由于每一层的FLume都是多个FLume在消费数据,所以消费数据的效率会提高。
(2)消费出的数据是否会有丢失或者重复:
1、对于数据源是Kafka的Flume来说,由于每当启动或者关闭Flume的时候,topic的分区都会重新分配,而由于数据是批量进入到Channel中,只有当数据完全进入到Channel中数据才会被标记为被消费,所以当数据有部分进入到Channel中而未被提交时发生了数据重新分配,那么这部分已经进入到Channel中的数据而未被提交的数据很有可能会重新被分配给另一个FLume,这部分数据就会重新被消费。最终的数据就会发生重复,但是由于时间差非常小,所以重复的数据可以忽略。
2、Flume自身用Channel的事务保证了数据不会丢失,其保证数据至少会被发送一次。Source在向Channel中put数据和Sink从Channel中take数据时,都是按照batch走的,那么当put或者take数据时就会启动事务,只有当数据完全put成功时事务才会被提交,不然就会回滚。同样的,只有当Sink确认数据安全到达目的地时,事务才会被提交,不然会回滚。
三、Q&A
Q:Flume数据一定会重复吗?
A:这个要视情况而定,由于Flume保证数据不丢失的机制,导致了当遇到特殊情况时数据会重新发送,比如下游存储系统(hdfs)运行过慢,这时就会有重复数据产生。
Q:Flume数据会丢失吗?
A:只要Flume不发生故障性异常,那么数据就不会丢失。如果说因为数据量过于庞大而造成丢失,这种情况还暂时没碰到过
另外:参考双层Flume 架构:参考链接:https://blog.csdn.net/qq_38258720/article/details/113130548

一.Failover Sink Processor测试
官网解释Failover Sink Processor:
Failover Sink Processor维护一个按优先级排列的sink列表,确保只要有一个sink可用,事件就会被处理(交付)。
Failover机制的工作原理是将失败的接收转移到池中,在池中为它们分配一个冷却期,在重新尝试它们之前,随着顺序故障的增加而增加。一旦接收器成功地发送了一个事件,它就会被恢复到活动池。sink有一个与它们相关联的优先级,数量越大,优先级越高。如果一个接收器在发送事件时失败,下一个具有最高优先级的接收器将被尝试下一步发送事件。例如,优先级为100的接收器在优先级为80的接收器之前被激活。如果没有指定优先级,则thr优先级根据配置中指定的sink的顺序确定。
要进行配置,将sink组处理器设置为Failover,并为所有单个的sink设置优先级。所有指定的优先级必须是唯一的。此外,可以使用maxpenalty属性设置Failover时间的上限(以毫秒为单位)。
下图中44446的优先级更高:
左边agent的配置failover.conf:
a1.sources = r1
a1.channels = c1
a1.sinks = k1 k2
a1.sources.r1.type = netcat
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 44444
a1.channels.c1.type = memory
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop000
a1.sinks.k1.port = 44445
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop000
a1.sinks.k2.port = 44446
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
k2即agent1的44446端口的优先级高(数字越大优先级越高)。
发送数据:
[hadoop@hadoop000 apache-flume-1.6.0-cdh5.15.1-bin]$ telnet localhost 44444
Trying 192.168.198.128...
Connected to localhost.
Escape character is '^]'.
aaa
OK
bbb
OK
ccc
OK
ddd
OK
eee
OK
fff
OK
44446接收到信息:
21/01/25 18:14:47 INFO ipc.NettyServer: [id: 0x0ce2a19e, /192.168.198.128:45240 => /192.168.198.128:44446] OPEN
21/01/25 18:14:47 INFO ipc.NettyServer: [id: 0x0ce2a19e, /192.168.198.128:45240 => /192.168.198.128:44446] BOUND: /192.168.198.128:44446
21/01/25 18:14:47 INFO ipc.NettyServer: [id: 0x0ce2a19e, /192.168.198.128:45240 => /192.168.198.128:44446] CONNECTED: /192.168.198.128:45240
21/01/25 18:15:40 INFO sink.LoggerSink: Event: { headers:{} body: 61 61 61 0D aaa. }
21/01/25 18:16:11 INFO sink.LoggerSink: Event: { headers:{} body: 62 62 62 0D bbb. }
将agent3 kill掉,44445端口被激活:
21/01/25 18:14:46 INFO ipc.NettyServer: [id: 0x946f8c34, /192.168.198.128:55142 => /192.168.198.128:44445] OPEN
21/01/25 18:14:46 INFO ipc.NettyServer: [id: 0x946f8c34, /192.168.198.128:55142 => /192.168.198.128:44445] BOUND: /192.168.198.128:44445
21/01/25 18:14:46 INFO ipc.NettyServer: [id: 0x946f8c34, /192.168.198.128:55142 => /192.168.198.128:44445] CONNECTED: /192.168.198.128:55142
21/01/25 18:16:42 INFO sink.LoggerSink: Event: { headers:{} body: 63 63 63 0D ccc. }
21/01/25 18:16:48 INFO sink.LoggerSink: Event: { headers:{} body: 64 64 64 0D ddd. }
21/01/25 18:47:19 INFO sink.LoggerSink: Event: { headers:{} body: 65 65 65 0D eee. }
1
重启agent3,44446端口再次被激活:
21/01/25 18:50:10 INFO ipc.NettyServer: [id: 0x58750737, /192.168.198.128:45596 => /192.168.198.128:44446] OPEN
21/01/25 18:50:10 INFO ipc.NettyServer: [id: 0x58750737, /192.168.198.128:45596 => /192.168.198.128:44446] BOUND: /192.168.198.128:44446
21/01/25 18:50:10 INFO ipc.NettyServer: [id: 0x58750737, /192.168.198.128:45596 => /192.168.198.128:44446] CONNECTED: /192.168.198.128:45596
21/01/25 18:50:13 INFO sink.LoggerSink: Event: { headers:{} body: 66 66 66 0D fff. }
1
二.双层的Flume架构
这篇博客写的特别详细:Flume日志收集分层架构应用实践.
双层Flume的好处:
解耦,hdfs或者kafka需要升级时,第二层flume可以进行缓冲,不会影响第一层。
安全,hdfs或者kafka直接暴露给第一层不安全(第一层很多flume来自其他部门,第二层在本地)。
利于业务的分组管理,将第一组的繁杂业务在第二层可以进行分组。
小文件的数量会大大减少。
外部某个类型的业务日志数据节点需要扩容,直接在L1层将数据流指向数据平台内部与之相对应的L2层Flume Agent节点组即可。
三.单source多channel多sink

第一层source发送一个消息,channel1和channel2都会传输,agent2和agent3都会收到相同的数据,所以这种架构可以将同一份数据,即可以导入hdfs进行离线计算,也可同时导入实时框架进行实时计算,实现多用途。
原文链接:https://blog.csdn.net/qq_38258720/article/details/113130548
Flume的多层代理和防止数据丢失

第一次agent负责采集原始数据,第二层agent负责对第一层数据进行汇聚。这种多层代理的方式尤其适合source源数据量庞大的时候,效率会高很多。
注意:1.如果要构建分层的代理结构,必然牵扯到数据的网络传输和分发问题。所以第一层代理需要某种特殊的sink来进行网络发送事件,再加上相应的source来接受这些事件。Avro sink 通过Avro RPC将事件发送给运行在另一个Flume代理上的其他Avro。事实上Avro的sink和source不提供写入和读取Avro文件的能力,它们仅用于代理层是事件分发,并且为了做到这一点,它们需要通过Avro RPC来进行通信。这里要区别Avro文件,如果想将事件写入到Avro文件,则可以使用HDFS sink实现。
2.如果第二层的agent停止运行,那么事件将被保存到第一层agent的channel中,等到第二层agent的重新启动。但是channel的存储是由限制的,如果第一层agent的channel已经填满数据时,第二层agent还没启动恢复运行,那么任何新采集的事件都会丢失。默认情况下,file channel能够恢复的事件数量不超过100万条(可以通过capacity属性来设置,实际要设置的大一些),此外,当检查点checkpointdir的可用磁盘空间小于500M时(minimumRequiredSpace属性设置),也将停止接收事件,造成新事件的丢失。
3.不管第一层某个代理还是第二层某个代理一旦有停止运行或者失败的情况出现,都会出现Flume丢失数据的情况发生。这也是常见开发中,或者面试中常问的Flume数据丢失问题,如果防止丢失?对于这个问题如果是第一层某个代理失败,那么可以考虑由第一层的其他节点来接管故障节点。如果是第二层代理停止运行,则为了防止数据丢失,只能让每一个第一层代理具有多个冗余的Avro sink,然后把这些sink安排到同一个sink组中,如果第二层代理中的某个代理出现问题,则该事件会被传递给该层sink组的其他代理来完成,以此来实现故障转移和负载均衡。下面博客继续sink组的实现。