近几年,医疗行业正在经历一场数字化转型,这场基于大数据和AI技术的变革几乎改变了整个行业的方方面面,将“信息就是力量”这句箴言体现的淋漓尽致,人们对人工智能寄以厚望,希望它能真正深入临床一线,帮助医生和患者。
理想很丰满,但现实却很骨感,在这场大变革下,作为医疗AI成长道路不可或缺的“粮食”,数据成了医疗AI落地的“拦路虎”——我国医疗健康数据领域长期存在的“信息孤岛”问题,不同地区甚至不同医院间的医疗数据没有互联,也没有统一的标准。与此同时,数据安全问题也存在着巨大挑战。
数据问题让医疗AI成了“空中楼阁”,在这一难题下,腾讯天衍实验室联合微众银行联合研发了医疗联邦学习框架,成功地实现了在保护不同医院数据隐私下的疾病预测模型,破解医疗行业数据安全与隐私保护难题。这是联邦学习在医疗健康大数据领域应用的首个成功案例,为医疗大健康的各种潜在应用如分诊诊疗、慢病防控、疾病早筛、医保控费的落地等探索出了新的方向。
首创医疗联邦学习——打破数据壁垒,保护数据隐私
在重大疾病早期筛查和预测领域,如果要成功能建立大数据疾病预测模型,就需要将居民在不同医院的医疗信息与健康档案进行整合与建模。但由于信息系统不统一,医院管理机构对于数据隐私泄露的担忧,和相关数据保护法规的限制,相关机构之间形成了数据壁垒,很少有医院愿意进行数据的共享,这就导致了AI难以在疾病预测领域“施展拳脚”。
在这个问题下,联邦学习成了一剂“良方”。联邦学习是一种新兴的人工智能机器学习框架,其设计目标是在保障大数据交换时的信息安全、保护终端数据和个人数据隐私、保证合规的前提下,在多参与方或多计算结点之间开展高效率的机器学习。联邦学习作为分布式的机器学习范式,可以有效解决数据孤岛问题,让参与方在不共享数据的基础上联合建模,能从技术上打破数据孤岛,实现AI协作。
该技术最早由谷歌在2016年提出,而后微众银行则在首席人工智能官杨强教授的带领下首次提出了“联邦迁移学习”,并开源自研联邦学习框架Federated AI Technology Enabler(简称FATE),推动联邦学习技术在行业中的落地。此前联邦学习在金融、互联网、智慧零智等领域已经有多个成功应用案例,但在医疗领域,由于医疗知识的专业性,电子病历的复杂性对联邦学习的构建带来了种种困难。
腾讯天衍实验室则结合自身医疗机器学习与自然语言处理的先天优势,与微众银行共同将联邦学习与医疗深度融合,有机整合医疗模型与机器学习,通过搭建基于联邦学习技术的大数据集中与挖掘平台,开发医疗联邦学习(Medical Federated Learning)技术。
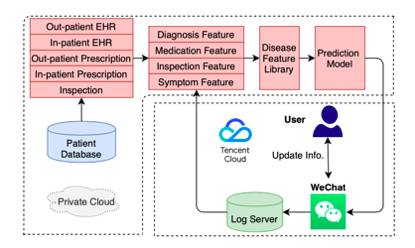
图片来源:天衍-微众投稿给人工智能顶级会议IJCAI 2020的论文
这一创新技术让医疗行业的数据问题“药到病除”,联邦学习可以绕过医疗机构之间的信息壁垒,不考虑将各自数据做合并,而是通过协议在其间传递加密之后的信息,该加密过程具有一定的隐私保护机制,保证加密后的信息不会产生数据泄露。各个医疗机构通过使用这些加密的信息更新模型参数,从而实现在不暴露原始数据的条件下使用全部患者数据的训练过程。
举例来说,假设医院 A 和 B 想联合训练一个脑卒中疾病预测模型,两个医院各自掌握科研病例数据,此外,医院 B 还拥有模型需要预测的标签数据如脑卒中发病标签。出于数据隐私保护和安全考虑,医院A 和 B 无法直接进行数据交换。联邦学习系统则可以利用基于加密的患者样本对齐技术,在医院A 和 B 不公开各自数据的前提下确认双方的共有患者,并且不暴露不互相重叠的患者,以便联合这些用户的特征进行建模,在确定共有用户群体后,就可以利用这些数据训练疾病预测模型。
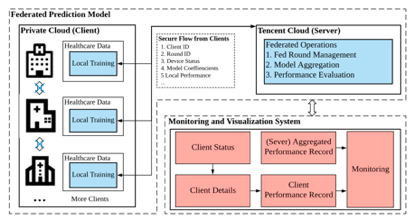
图片来源:天衍-微众投稿给人工智能顶级会议IJCAI 2020的论文
如此一来,联邦学习技术就成功破解医疗行业信息孤岛和隐私保护难题,实现了在保护不同医院数据隐私下的疾病预测模型,而这项技术也在疾病预测领域落地,双方成功构建“脑卒中发病风险预测模型”。
成功落地疾病预测领域 脑卒中预测准确率达80%
在构建疾病预测模型过程中,不同医院数据缺乏标准化是关键性难题。双方首先通过搭建的大数据集中与挖掘平台,构建医疗健康领域机器学习、深度学习、自然语言理解、文本特征抽取、多种关系网络等多种大数据模型,对地区居民连续电子病历和其它数据进行多重关联和信息抽取。构建带有时间标志的重大慢病标签(脑卒中、冠心病、肿瘤、慢阻肺等)与大健康医疗特征(疾病、用药、检查、症状、手术、费用、家庭关系、行为、生活、环境),并对不同医院构建统一的数据标准形成疾病标签集与特征集。
通过技术力量对疾病预测模型所需特征进行标准与归一化后,再将标准化模型部署到不同医院,使各医院按照该标准对自有的疾病、用药、检验检查、症状、手术等方面的数据进行清洗,形成各自的标准化的疾病标签集与医疗特征集,再以此建立巢式病例对照研究队列,基于联邦学习算法协议,有效训练机器学习模型。
通过使用来自就诊记录数量TOP5的医院真实就诊数据验证,基于横向联邦学习的脑卒中预测模型的有效性良好。结果显示,基于横向联邦学习的脑卒中预测模型的有效性良好。联邦学习模型和集中训练模型表现几乎一致,在脑卒中预测模型中的准确率达到80%,仅比集中训练模型准确率降低1%,同时,联邦学习技术显著提升了不同医院的独立模型效果,特别地,对于两家脑卒中确诊病例数量较少的医院而言,联邦学习分别提升其准确率10%和20%以上。因此,基于联邦学习的联合模型效果优于任意一家医院独立建模结果,与集中数据训练所得模型效果相比也差异甚微,为不同医院的联合建模探索出了新的方向。
双方的这一成功合作案例仅仅是医疗联邦学习落地应用的开始,除疾病预测模型外,后续双方将就联邦学习在医疗大数据领域的应用落地进行更多维度的合作,包括医保控费、合理诊断、精准医疗等领域。医疗联邦学习作为基础技术框架,可以挖掘并利用医疗健康数据,构建不同的医疗场景应用,如通过联邦学习助力电子健康卡实现保护用户隐私建模等等,以助力医疗健康产业发展,提升医疗服务的质量。