PYTHON:
O 注意python给一个01串8位分组的方法
for i in range(len(s) // 8):
a = s[i * 8: i * 8 + 8]
易错点1:乘8不要忘了
易错点2:右边是+8不是+7
O 注意区分list的切片和range的区间,-1在二者中的意义不一样
a = [i for i in range(64)]
for i in range(16):
for j in a[i * 4 + 4 - 1: i * 4 - 1: -1]:
print(j)
得到的结果是 7 6 5 4 11 10 9 8 ,而没有3 2 1 0
因为list里-1是最后一个数,所以i=0的时候发现右边大于左边,直接跳过去了
O 如果想把一个大于128的char编码成base64,切忌不能直接b64encoder(s.encode()),这样encoder()会自动当成utf8编码然后混进来奇怪的东西
应该s = s + int.to_bytes(1, byteorder='big')
通用:
O 如果写脚本爆破不出结果,有可能是有多解
O 打 ctf 一定注意,下标从 0 开始,这个错误常见于自己写的脚本中
例如手写队列,还按习惯先让 hd = hd + 1 再 q[hd] = x 就容易出错
CRYPTO:
O 判断是否是不可见字符的时候注意范围不仅是[32,128),还要再带上一个' '
例如用key循环xor一个诗歌,那么如果要枚举每一位,判断是有不可见字符来判断密钥可行性的话,把' '漏掉就找不到解了
这个特点其实也可以为我们所用,例如诗歌里边一般不会出现数字,那么就可以把0到9列为非法字符
O 题目中给的flag{xxxx}中的x的个数不一定是真实的长度
良心题目应该都是满足这个条件的,但是如果卡自闭了不妨试试枚举长度
O 如果rsa解出来的m不满足m^e1%n=c1,可能不是求解写错了
有可能是读入c1的时候读错了,注意如果读错了,那么就不满足c1=m^e1!
REVERSE:
O 如果出现 dword_123456==0x12345678 这种,注意并不是字符串比较,而是先翻转再比较
注意 dword 取内存的顺序和字符串不一样
O 如果发现形如(c[i]+66)^0xAA的代码,那么把加密后的bytes逐字节异或0xAA后出现小于66的数时不奇怪的
注意可以溢出,如果c[i]是char会自动溢出
O 遇到IDA伪代码是用一个变量给内存分配值,然后指针扫描取值的时候
注意不要偷懒直接copy伪代码到C运行,因为不同操作系统和不同语言的变量内存防止可能不一样
最好还是勤快点,写一个python,每次模并除256(一般取的都是char)
O 看内存的时候不要光找英文的地址索引,有时候会有这种情况
s 36h
abcd ...
题目中是从s开始寻址的,如果看成abcd就惨了……
O 用脚本处理数字的时候主义隐藏的0
比如下一条中的图,如果没有注意到2实际是02,python就会把1402处理成0142
O 看内存的时候一定不要轻易忽略地址索引名右边的那个值
这个值有时候会长得很奇怪,但是忽略的话就会很惨
比如这样
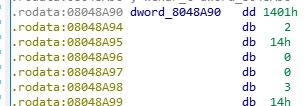
读出来应该是1401 1402 1403,把1401丢了就错了