本次爬取的是著名基因数据库www.oncomine.org,爬取的内容是基因相关因子和点位信息,由于源数据是以图片形式展现的,因此我们需要结合常规爬虫+Ocr表格识别+图像裁剪技术进行。
先看一下采集源的图片:

图中红色框选部分就是我们要抓取的内容,看似是普通文本,其实和右侧的矩阵图是一样的,都是一张完整的图片,网页其他位置无法获得此数据,因此按如下步骤进行:
1、爬虫工具自动翻页将所有图片下载下来,按日期重命名,以便后续按顺序进行整理。


2、加载目录中的图片,进行裁剪,只保留左侧部分,目的是增强Ocr表格识别的准确率和速度。
同时,由于图中左侧没有表格线,不容易识别,所以人为增加网格线,效果如下:
string source = _hostingEnvironment.WebRootPath + "\source\"; string[] allGene = FileHelper.GetFileNames(source + "geneSPINT2\"); List<VM_Oncomine> finalR = new List<VM_Oncomine>(); Bitmap background = (Bitmap)Bitmap.FromFile(source + "bg.jpg");//加白色背景 System.Drawing.Image iSource = System.Drawing.Image.FromFile(pic); Bitmap newbm = new Bitmap(133, 460); Graphics gh = Graphics.FromImage(newbm); gh.DrawImage(background, 0, 0, 133, 460); gh.DrawImage(iSource, new Rectangle(0, 0, 133, 460), new Rectangle(20, 50, 133, 460), GraphicsUnit.Pixel); newbm.Save(pic.Replace("geneSPINT2", "temp_geneSPINT2"), ImageFormat.Bmp);
3、使用百度表格识别API进行识别,以Json形式展现结果。
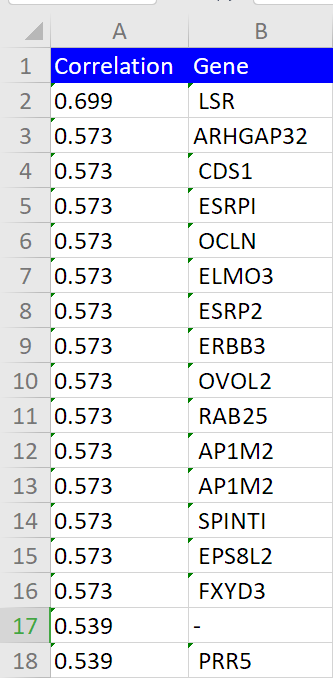
4、将结果合并,导出Excel即可
完整代码如下:
/// <summary> /// 采集oncomine.org图片中表格信息采集 /// </summary> /// <returns></returns> [HttpGet("pictoexcel")] public IActionResult PicToExcel() { var client = new Baidu.Aip.Ocr.Ocr("QhgOZpPMfNYlUVd3kUR。。。。", "5Gw6nrqrkYkMoCqc59hlB8s。。。。。。"); client.Timeout = 40000; // 修改超时时间 string source = _hostingEnvironment.WebRootPath + "\source\"; string[] allGene = FileHelper.GetFileNames(source + "geneSPINT2\"); List<VM_Oncomine> finalR = new List<VM_Oncomine>(); Bitmap background = (Bitmap)Bitmap.FromFile(source + "bg.jpg");//加白色背景 foreach (var pic in allGene) { System.Drawing.Image iSource = System.Drawing.Image.FromFile(pic); Bitmap newbm = new Bitmap(133, 460); Graphics gh = Graphics.FromImage(newbm); gh.DrawImage(background, 0, 0, 133, 460); gh.DrawImage(iSource, new Rectangle(0, 0, 133, 460), new Rectangle(20, 50, 133, 460), GraphicsUnit.Pixel); newbm.Save(pic.Replace("geneSPINT2", "temp_geneSPINT2"), ImageFormat.Bmp); //文字识别 byte[] imageBytes = FileHelper.ReadFileToByte(pic.Replace("geneSPINT2", "temp_geneSPINT2")); var result = client.TableRecognitionRequest(imageBytes).ToString(); JObject jo = (JObject)JsonConvert.DeserializeObject(result); var options = new Dictionary<string, object>{ {"result_type", "json"} }; retry: var tableR = client.TableRecognitionGetResult(jo["result"][0]["request_id"].ToString(), options); if (tableR["result"]["ret_msg"].ToString() != "已完成") { Thread.Sleep(2000); goto retry; } else { var formResult = (JObject)JsonConvert.DeserializeObject(tableR["result"]["result_data"].ToString()); var bodyRows = formResult["forms"][0]["body"]; foreach (var r in bodyRows) { string word = r["word"].ToString(); if (word.IndexOf("0.") > -1) { int coRow = (int)r["row"][0]; foreach (var f in bodyRows) { if (f["word"].ToString().IndexOf("0.") == -1) { int genRow = (int)f["row"][0]; if (genRow == coRow) { if (f["word"].ToString() == "") { f["word"] = "-"; } finalR.Add(new VM_Oncomine { Correlation = word, Gene = f["word"].ToString() }); } } } } } } } //导出Excel XlsGenerator.createXlsFile(finalR, "SPINT2", source, out string filePath); var dt = DateTime.Now.ToString("yyyyMMdd"); string fileName = WebUtility.UrlEncode("Gene_") + dt + ".xls"; filePath = source + filePath; Response.Headers.Add("content-disposition", "attachment;filename=" + fileName); return File(new FileStream(filePath, FileMode.Open), "application/excel", fileName); }
想要采集爬虫网络数据的可以邮件联系我 cdipbsxf@qq.com