Spark中调度其实是分为两个层级的,即集群层级的资源分配和任务调度,以及任务层级的任务管理。其中集群层级调度是可配置的,Spark目前提供了Local,Standalone,YARN,Mesos。任务层级的任务管理就使用Driver-Executor架构来进行管理。在Standalone模式下,首先对涉及到的名词进行说明
| 名称 | 说明 |
|---|---|
| Master | Spark standalone集群主节点,保存集群元数据,负责资源分配和任务调度 |
| Worker | Spark standalone集群工作节点,是实际运行任务的节点 |
| Client | 用户提交程序的节点,通过client将程序提交到Spark集群运行 |
| Driver | 管理Application运行任务使用的Executor,以及保存运行所需的元数据 |
| Executor | 在Worker上运行,用来实际执行任务 |
| Application | 用户提交的程序 |
| Job | 对于每个action操作都是一个Job,一个用户程序中可以有多个job(多个action,如果这些action是在不同线程中提交的,则job会并行提交到集群执行) |
| Partition | 每个Job都会被分为多个Partition,不同的Partition上的任务可以并行运行,提高并行度 |
| Stage | Spark内部会将一个Job划分为多个Stage |
| Task | Task是Spark中最小的执行单位。在每个Stage中,Spark为每个Partition建立一个Task,并发送到Executor上执行 |
集群启动流程
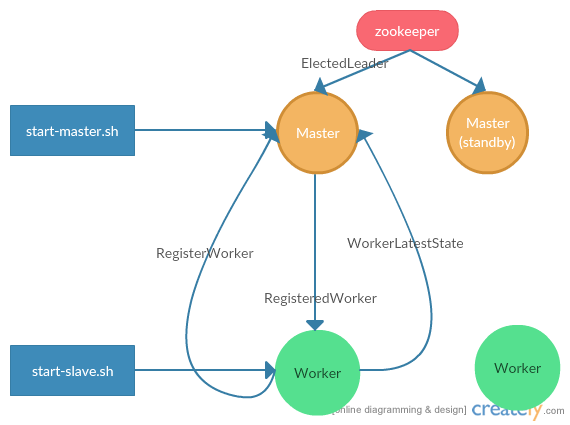
本文以Spark Standalone集群以正常启动,双Master,以zookeeper作为Master leader选举和灾备恢复方案,流程如下:
- 首先在要启动Master的节点运行start-master.sh脚本,在本机启动Master,Master的默认启动状态为standby,即备份节点。Master启动后会向zookeeper注册,zookeeper会选择一个节点作为leader,并向leader节点发送ElectedLeader消息,被选中的Master将节点状态改为alive
- 在要启动Worker的节点上运行start-slave.sh脚本,以在本机启动Worker。Worker初始化时首先向Master发送RegisterWorker请求,Master接收到请求后,将Worker相关信息保存到本地,并返回RegisteredWorker消息
- Worker在收到Master发送的RegisteredWorker后,向Master汇报Worker当前的状态(保存的driver,executor信息),并封装在WorkerLastestState消息中发送给Master,从而完成启动并注册到Master
用户程序提交流程
使用Spark的用户可以通过spark-submit脚本将编译好的程序通过客户端到Spark集群运行。Spark为用户提供了两种部署模式(deploy-mode),即client模式和cluster模式。这两种模式的区别是,在client模式中,driver就运行在客户端本地,而cluster模式,客户端只负责将用户程序和运行参数提交到集群,之后就可以退出了,driver在集群中的一个worker上运行。
cluster模式提交流程
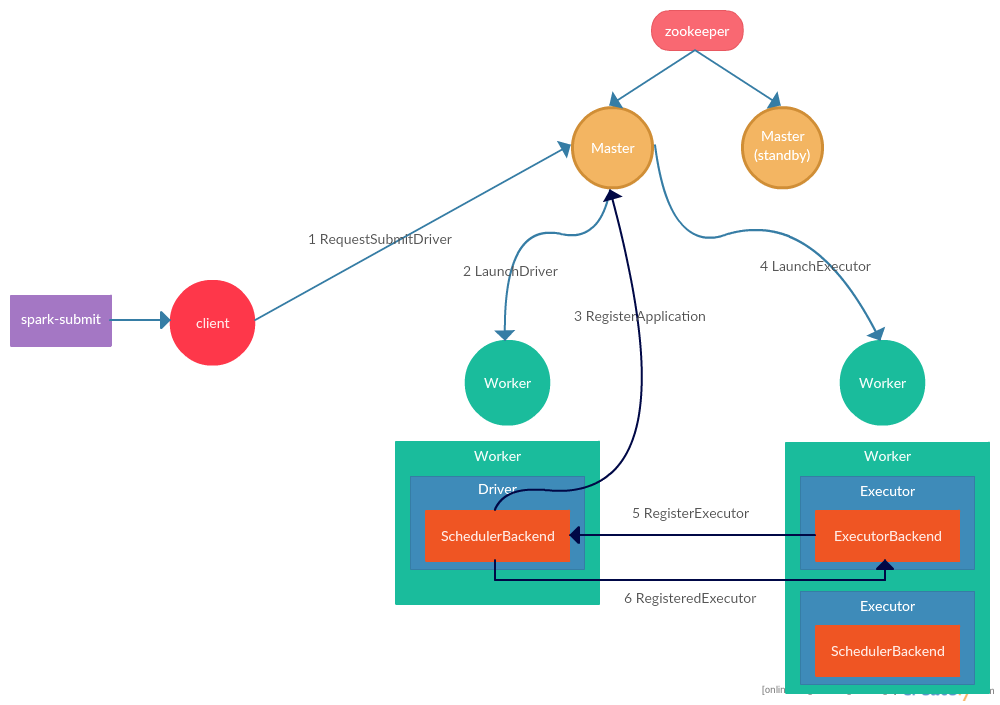
- 用户在Spark客户端通过spark-submit命令提交程序,并指定提交模式为cluster后,spark-submit脚本实际执行SparkSubmit实例,使用
org.apache.spark.deploy.rest.RestSubmissionClient(默认)或org.apache.spark.deploy.Client实际发送RequestSubmitDriver请求到master(用户通过spark-submit的master参数指定) - master收到RequestSubmitDriver后,发送LaunchDriver请求到一个worker,并将分配driver的相关元数据保存到zookeeper中,以便当前master挂掉后,备份master可以通过zookeeper恢复集群状态
- worker在收到请求后,会在当前的jvm中创建driver,并调用用户程序的main方法开始执行程序。在SparkContext初始化时,会启动TaskScheduler,在TaskScheduler中会启动StandaloneSchedulerBackend,StandaloneSchedulerBackend会启动StandaloneAppClient,StandaloneAppClient初始化时,会向所有的master发送RegisterApplication请求,主备master都会收到请求,但是只有主master会响应请求
- master在收到RegisterApplication请求后,将application需要的executor分配到响应的worker上(当前根据需要的核心数和内存来进行分配。在分配时存在两种分配策略:即将申请的executor分配到尽可能多的worker上(默认),以及将executor分配到尽可能少的worker上),然后向需要分配executor的worker发送LaunchExecutor请求,并将相关的元数据写入zookeeper
- worker在收到LaunchExecutor请求后,根据用户指定的executor参数,为每个executor启动一个新的jvm,并在新的jvm中实例化CoarseGrainedExecutorBackend
- CoarseGrainedExecutorBackend初始化时,会向executor所属的driver发送RegisterExecutor请求,请求实例化executor
- driver在收到来自executor的注册请求后,如果当前executor没有注册(根据executorId判断),则将申请注册的executor元数据保存到driver内存中,并向executor响应RegisteredExecutor(如果发现当前executorId已经被注册,则向当前申请注册的executor发送RegisterExecutorFailed响应),ExecutorBackend在收到RegisteredExecutor请求后,在当前jvm实例化Executor
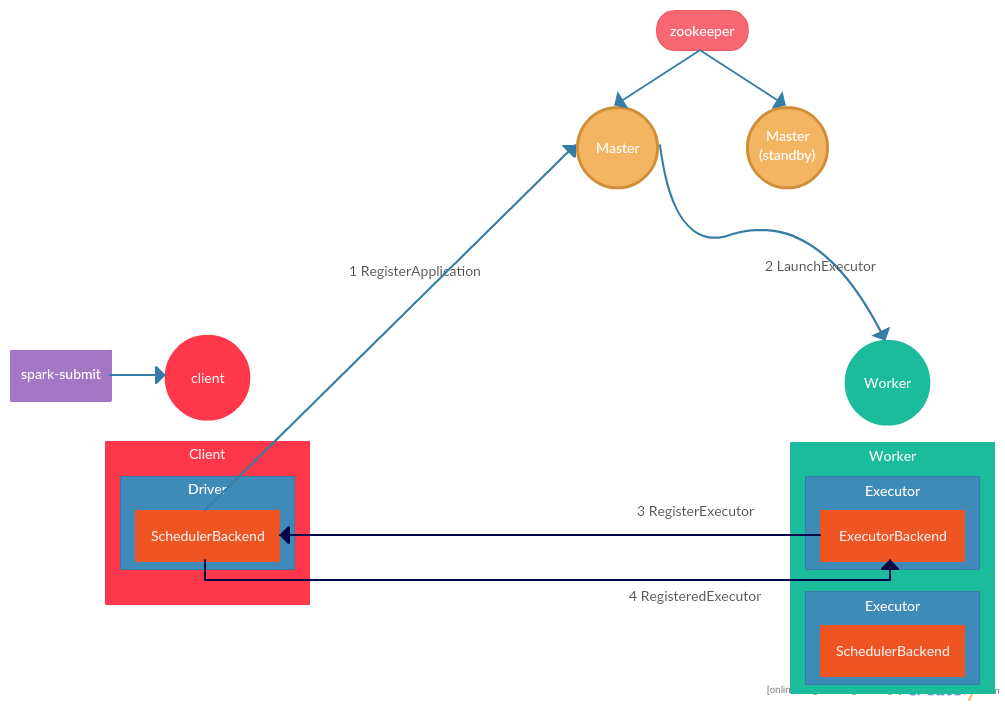
client模式提交流程
client模式driver是在client本地运行,所以相比cluster模式少了RequestSubmitDriver这一步(即向master申请在集群中某个worker上启动driver),流程如下:
- 用户在Spark客户端通过spark-submit命令提交程序,并指定提交模式为client后,spark-submit脚本实际执行SparkSubmit实例,并直接在本地调用用户程序main方法启动用户程序。在SparkContext初始化时,会启动TaskScheduler,在TaskScheduler中会启动StandaloneSchedulerBackend,StandaloneSchedulerBackend会启动StandaloneAppClient,StandaloneAppClient初始化时,会向所有的master发送RegisterApplication请求,主备master都会收到请求,但是只有主master会响应请求
- 接下来的流程与cluster的4,5,6,7步骤相同
用户程序执行流程
用户通过spark-submit脚本将编译好的程序成功提交到集群后,会首先在Driver节点调用用户指定的main方法开始执行用户程序。接下来以Spark自带例子JavaWordCount来对Spark用户程序的执行流程进行说明,示例程序如下:
public final class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length < 1) {
System.err.println("Usage: JavaWordCount <file>");
System.exit(1);
}
SparkConf conf = new SparkConf().setAppName("JavaWordCount");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaRDD<String> lines = jsc.textFile(args[0]);
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(SPACE.split(s));
}});
JavaPairRDD<String, Integer> ones = words.mapToPair(
new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<>(s, 1);
}
});
JavaPairRDD<String, Integer> counts = ones.reduceByKey(
new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?,?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
jsc.close();
}
}
SparkContext初始化
每个Spark程序都要首先实例化SparkContext实例作为当前程序的Spark执行环境。SparkContext初始化时会启动DAGScheduler和TaskScheduler,用来处理之后提交的job。DAGScheduler用来根据用户提交的RDD的DAG将RDD划分为多个Stage,然后每个Stage作为一个TaskSet,为RDD的每个分区对应一个Task,并加入TaskSet。然后将TaskSet提交到TaskScheduler进行任务调度,由TaskScheduler将Task分配到Executor上运行。DAGScheduler和TaskScheduler的内容具体见任务提交
RDD转换和DAG构建
在用户编写程序时,实际上就是对Spark提供的RDD进行转换的过程,Spark会将RDD进行层层包装,并记录RDD之间的关系,最终构建出一个RDD的DAG。在最后的RDD上调用action操作(本文例子中是调用counts.collect方法),会真正触发用户编写的job的提交到Spark集群执行。之后Spark就可以从最后一个RDD逆向获得整个job RDD的DAG,从而进行计算。

任务提交
Stage划分和TaskSet提交
当用户程序调用Spark的action方法后action以及与之关联的transformation操作的RDD就会被封装成一个job提交到Spark集群执行。job首先会被提交给DAGScheduler,由DAGScheduler根据提交job的RDD的DAG划分Stage。划分依据就是如果RDD的依赖(deps)类型为ShuffleDependency,则当前RDD为新的Stage,并依赖于当前RDD依赖的RDD所在的Stage。当划分完Stage后,DAGScheduler会按Stage之间的依赖关系依次提交(保证依赖的Stage都执行完毕后再执行当前的Stage)。在提交Stage时,DAGScheduler会为Stage中最后一个RDD的每个分区建立一个task,一个Stage中所有的task组成一个taskSet提交到TaskScheduler执行。而属于一个Stage的RDD,由于子RDD分区的数据都来自父RDD固定的分区,所以可以在一个task中以流水线的方式进行计算转换,task可以并行进行。
JavaWordCount这个例子中,最终会在ShuffleDependency分成两个Stage,Stage中的RDD为每个Stage中最后的一个RDD,如下图所示: 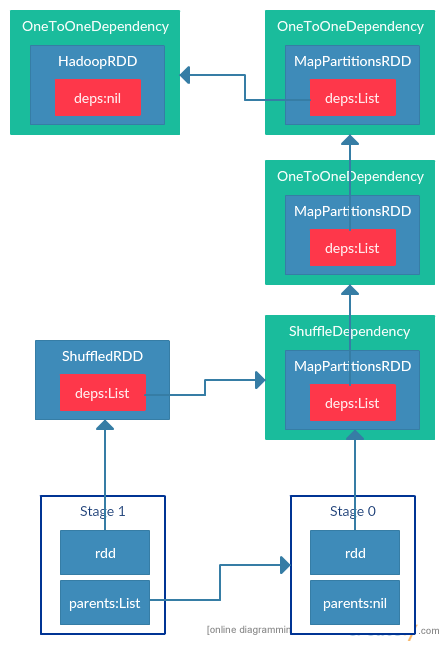 生成的每个Task都保存了Task执行需要的序列化值,以便在Executor上反序列化执行。对于ShuffleMapTask,序列化的值为RDD和对应ShuffleDependency的序列化值。对于ResultTask来说,序列化值为RDD和用户自定义函数func的序列化值。比如foreach action方法中用户定义的函数。本文的例子中为collect方法,只是简单的返回结果的iterator。
生成的每个Task都保存了Task执行需要的序列化值,以便在Executor上反序列化执行。对于ShuffleMapTask,序列化的值为RDD和对应ShuffleDependency的序列化值。对于ResultTask来说,序列化值为RDD和用户自定义函数func的序列化值。比如foreach action方法中用户定义的函数。本文的例子中为collect方法,只是简单的返回结果的iterator。
每个Task还包含了locs字段,用来标示Task首选运行的节点,这个locs实际就是分区数据的存储节点,Spark通过locs实现数据本地化的优化。在生成TaskSet后,DAGScheduler会将TaskSet提交到TaskScheduler执行。最终生成TaskSet如下图所示:
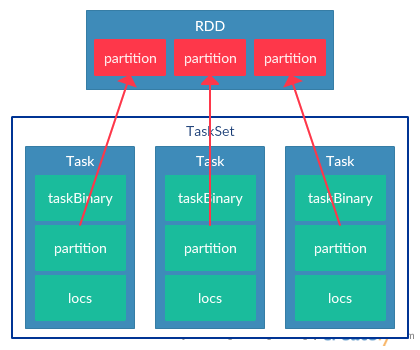
TaskSet调度和Task分配Executor
TaskScheduler在收到DAGScheduler提交的TaskSet后,会将TaskSet放入调度队列中。SchedulerBackend会定时读取任务调度队列,从中读出优先级最高的TaskSet,然后根据TaskSet中每个Task的首选执行位置为每个Task分配Executor,最终将Task发送到对应的Executor进行执行。具体的调度方法和分配Executor的方法详情见spark scheduler这篇文章。下图描述了用户提交的应用程序生存job并提交到工作节点执行的过程: 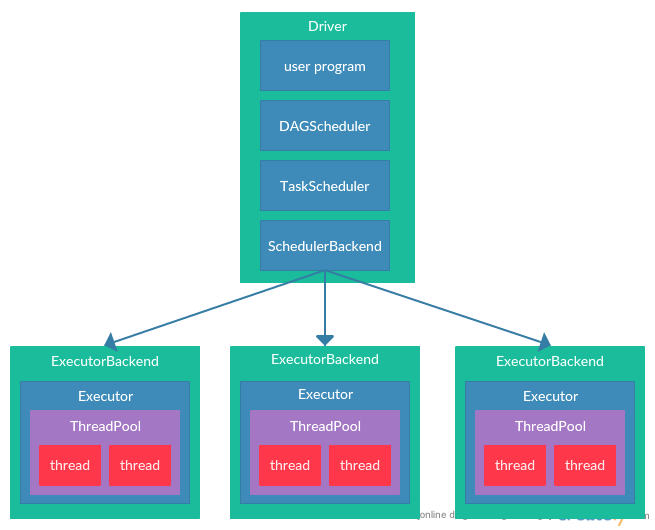
任务执行
Task提交到Executor之后,Executor会从线程池中选择一个线程来运行Task。Spark中存在两种Task,即ShuffleMapTask和ResultTask,其中ResultTask为action方法最终计算生成结果的Task(即最后一个Stage对应的Task),而ShuffleMapTask为Spark内部其他Stage对应的Task。对于本文的例子来说,首先运行的是ShuffleMapTask,用来从hdfs读取文件,并将文件划分为单词,将每个分区中每个单词出现的次数输出到map文件。之后运行ResultTask任务,运行ShuffleMapTask的节点获取map文件,并统计每个单词出现的次数(这个过程类似于hadoop的map-reduce),最终以iterator的形式返回给用户程序。程序执行流程图如下(假设HadoopRDD为4个分区,ShuffledRDD为3个分区): 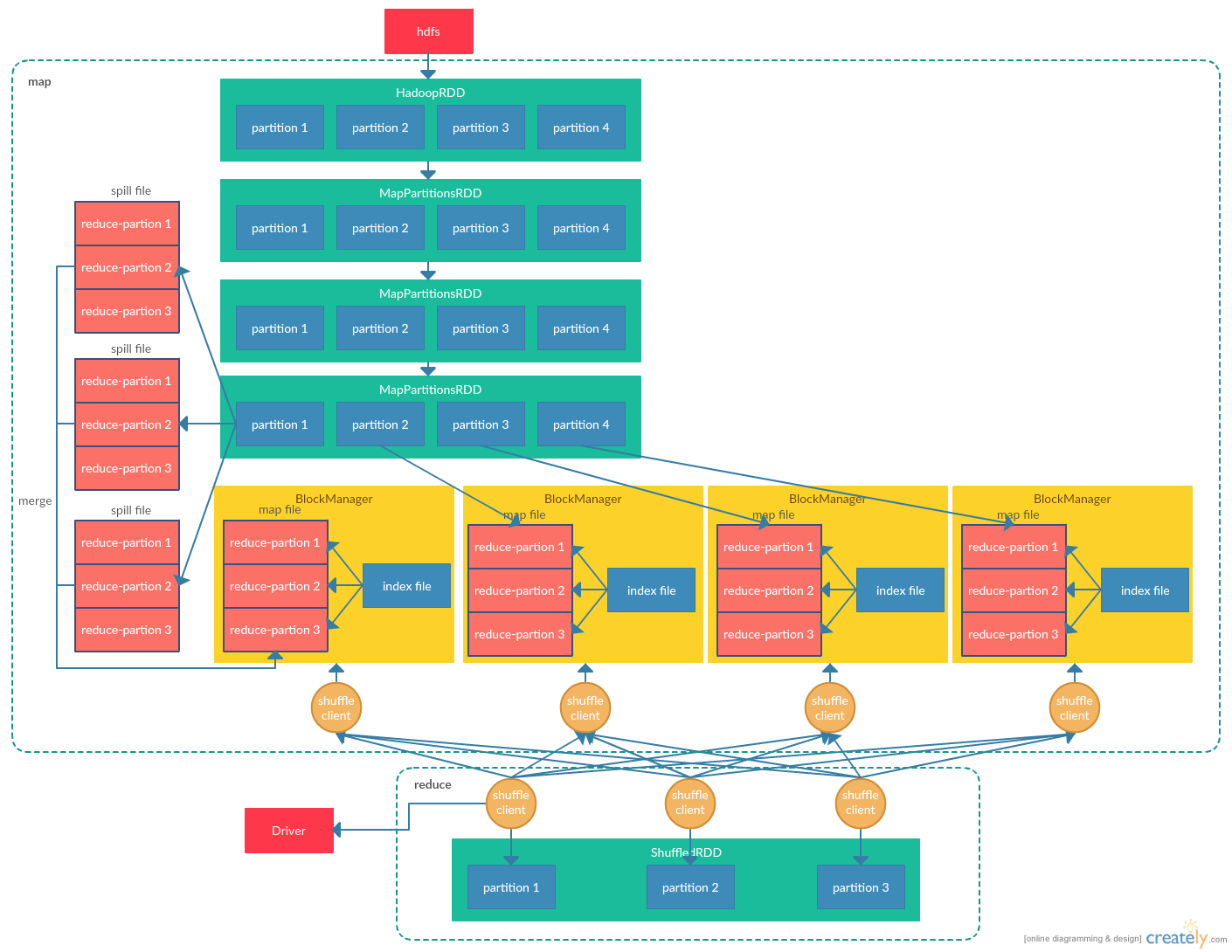
ShuffleMapTask执行
本文的例子中,首先会将ShuffleMapTask提交到Executor上执行。例子中ShuffleMapTask的主要目的是将Task所负责的分区上的单词出现的次数,并保存到Executor所在节点的本地map文件中。具体来说,每个Task会调用其所负责的分区数据的iterator方法,如果当前分区数据存在,则直接进行map操作;如果分区数据不存在,则递归调用分区的父分区数据的iterator方法,最终调用HadoopRDD对应分区的iterator方法,从而真正从hdfs上读取分区数据,并进行用户指定的transformation操作。在进行map操作时,会首先按单词为key写入内存中,如果遇到相同的单词,则使用用户指定的合并方法(这里为+1)对相同的key进行合并。如果内存不足以放下所有数据,则首先将内存中的数据根据reduce阶段的分区规则将单词进行排序,保证同一分区的单词连续,然后将内存数据刷新到磁盘的spill文件中。当map结束时,将所有的spill文件和内存中的数据进行合并,最终输出一个map文件,以及一个索引文件,用来记录reduce每个分区在map文件的起止地址。最终Task将执行结果上报给Driver,由Driver保存每个map文件所在节点,以便在reduce阶段时,指引reduce Task去对应的节点获取数据。
ResultTask执行
在本文例子中,ResultTask在Stage 1阶段,所以DAGScheduler会在Stage 0阶段的所有ShuffleMapTask执行完毕后再将所有ResultTask提交给TaskScheduler进行执行,这保证了ResultTask所需的map文件已经全部生成并将文件位置上报给了Driver。
每个ResultTask在启动后首先向Driver节点查询包含map文件的节点,然后与对应节点的ShuffleClient建立连接,并根据索引文件获取到Task需要分区的数据,然后对数据进行合并操作(在本例子中就是统计单词的出现次数),最终形成ShuffledRDD,最终由用户调用的collect方法,每个分区将其所保存的数据以iterator的形式返回给用户程序。
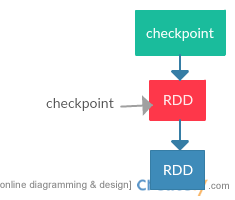
RDD缓存和RDD检查点
由上述流程可知,每个RDD的transformation操作实际上是不保存数据的,只是从上游的RDD获取到数据并进行转换后发送给下游的RDD,如果链路中的某个RDD分区丢失了数据,则需要根据RDD的血缘(lineage)从最开始的代表外部数据源的RDD中获取数据并进行一系列的转换操作。所以为了RDD的重用和降低故障恢复的时间,Spark提供了缓存RDD和为RDD建立检查点两个方法。缓存RDD和为RDD建立检查点的区别是缓存RDD只是为了加快数据的计算,RDD的依赖链路是完整保存的,在缓存的数据不可用时,Spark还可以根据RDD的依赖关系重新计算得到数据。而checkpoint检查点对应的RDD的依赖链路是不保存的,对应的RDD只有一个指向检查点文件的父RDD,所以在检查点数据丢失的情况下,Spark是无法根据RDD的依赖链路恢复数据的。而且由于缓存的数据由BlockManager管理,所以在driver程序执行结束时,被缓存的数据也会被清空。而checkpoint的数据是写入诸如HDFS文件系统中的,是独立存在的,所以可以被下一个driver程序执行使用。
cache RDD,下次再读取红色的RDD时直接从缓存中读取,不再从hdfs中读取再进行转换后生成红色RDD。当缓存不可用时,还可以按照之前的流程重新读取并生成缓存。
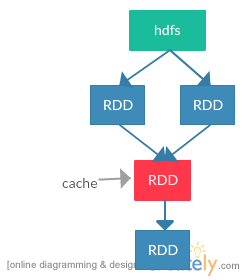
checkpoint RDD,下次再读取时直接从检查点文件中读取。档检查点文件不可用时,由于已经不保存RDD之间的血缘,所以不能恢复数据。
任务执行后续处理
Task在Executor成功执行后,会将执行结果封装在StatusUpdate消息中由ExecutorBackend发送给SchedulerBackend。在本文例子中,对于处于Stage 0阶段的ShuffleMapTask执行成功后,将任务执行成功的信息发送给Driver的SchedulerBackend,Driver会更新保存的任务信息,并在属于Stage 0阶段的所有任务成功完成后,将Stage 1的任务提交到集群执行。对于处于Stage 1的任务在执行成功后,Stage 1阶段执行成功的Task+1,当所有Stage 1阶段的任务成功完成后,调用job成功的回调接口,将执行结果返回给用户。