2015-10-23
目录
一、数据定义 DDL
1.创建表 CREATE TABLE
2.修改表 ALTER TABLE
3.删除表 DROP TABLE
4.截断表 TRUNCATE TABLE
二、数据操作 DML
5.查询记录 SELECT
6.插入记录 INSERT
7.更新记录 UPDATE
8.删除记录 DELETE
一、数据定义 DDL
1.创建表 CREATE TABLE
create_table::=



CREATE [ GLOBAL TEMPORARY ] TABLE [ schema. ] table { relational_table | object_table | XMLType_table } ;
relational_table::=
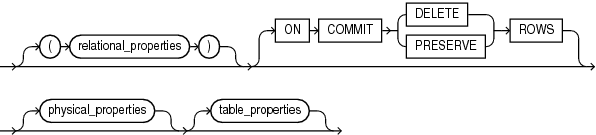
[ (relational_properties) ] [ ON COMMIT { DELETE | PRESERVE } ROWS ] [ physical_properties ] [ table_properties ]
object_table ::=

OF [ schema. ] object_type [ object_table_substitution ] [ (object_properties) ] [ ON COMMIT { DELETE | PRESERVE } ROWS ] [ OID_clause ] [ OID_index_clause ] [ physical_properties ] [ table_properties ]
XMLType_table ::=
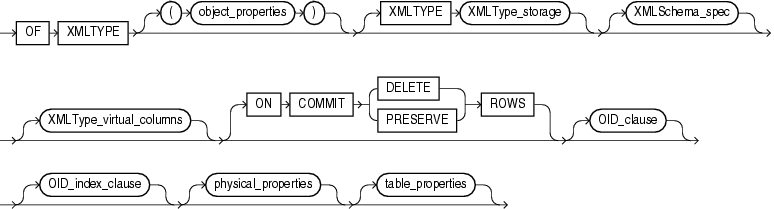
OF XMLTYPE [ (oject_properties) ] [ XMLTYPE XMLType_storage ] [ XMLSchema_spec ] [ XMLType_virtual_columns ] [ ON COMMIT { DELETE | PRESERVE } ROWS ] [ OID_clause ] [ OID_index_clause ] [ physical_properties ] [ table_properties ]
2.修改表 ALTER TABLE
【语法】ALTER TABLE 官方文档
alter_table::=
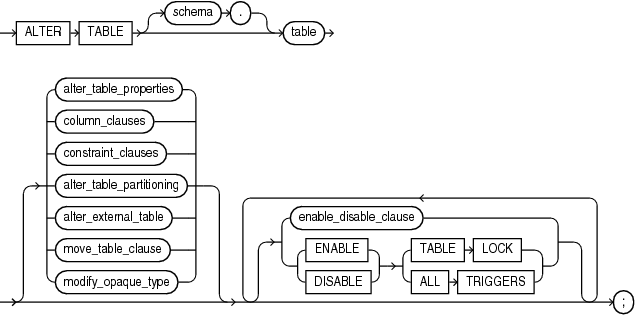
ALTER TABLE [ schema. ] table [ alter_table_properties | column_clauses | constraint_clauses | alter_table_partitioning | alter_external_table | move_table_clause | modify_opaque_type ] [ enable_disable_clause | { ENABLE | DISABLE } { TABLE LOCK | ALL TRIGGERS } ] ... ;
alter_table_properties::=

{ { { physical_attributes_clause | logging_clause | table_compression | inmemory_alter_table_clause | ilm_clause | supplemental_table_logging | allocate_extent_clause | deallocate_unused_clause | { CACHE | NOCACHE } | RESULT_CACHE ( MODE {DEFAULT | FORCE} ) | upgrade_table_clause | records_per_block_clause | parallel_clause | row_movement_clause | flashback_archive_clause }... | RENAME TO new_table_name } [ alter_iot_clauses ] [ alter_XMLSchema_clause ] | { shrink_clause | READ ONLY | READ WRITE | REKEY encryption_spec | [NO] ROW ARCHIVAL | ADD attribute_clustering_clause | MODIFY CLUSTERING [ clustering_when ] [ zonemap_clause ] | DROP CLUSTERING } }
3.删除表 DROP TABLE
【语法】DROP TABLE 官方文档
drop_table::=

DROP TABLE [ schema. ] table [ CASCADE CONSTRAINTS ] [ PURGE ] ;
4.截断表 TRUNCATE TABLE
【语法】 TRUNCATE TABLE 官方文档
truncate_table::=
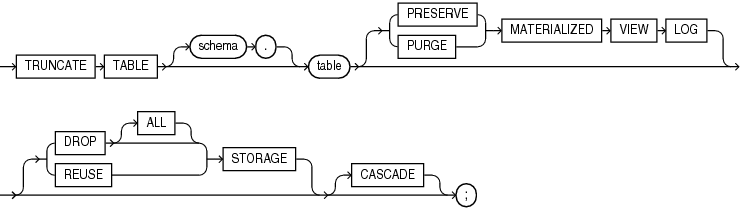
TRUNCATE TABLE [schema.] table [ {PRESERVE | PURGE} MATERIALIZED VIEW LOG ] [ {DROP [ ALL ] | REUSE} STORAGE ] [ CASCADE ] ;
二、数据操作 DML
5.查询记录 SELECT
【语法】 SELECT 官方文档
select::=

subquery [ for_update_clause ] ;
subquery::=
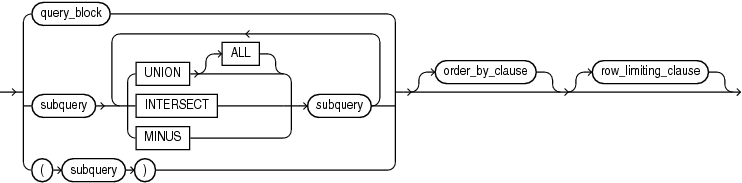
{ query_block | subquery { UNION [ALL] | INTERSECT | MINUS } subquery [ { UNION [ALL] | INTERSECT | MINUS } subquery ]... | ( subquery ) } [ order_by_clause ] [ row_limiting_clause ]
for_update_clause ::=

FOR UPDATE [ OF [ [ schema. ] { table | view } . ] column [, [ [ schema. ] { table | view } . ] column ]... ] [ { NOWAIT | WAIT integer | SKIP LOCKED } ]
query_block::=
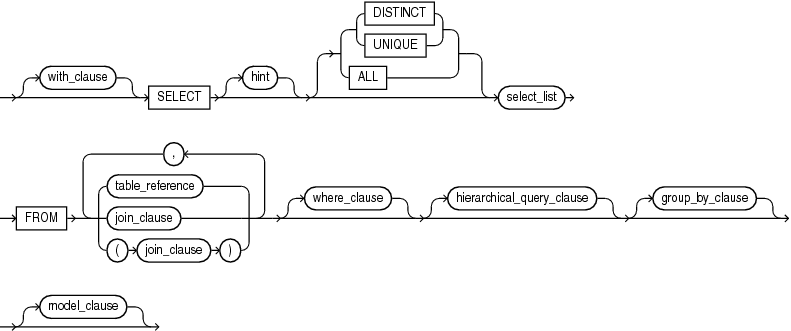
[ with_clause ] SELECT [ hint ] [ { { DISTINCT | UNIQUE } | ALL } ] select_list FROM { table_reference | join_clause | ( join_clause ) } [ , { table_reference | join_clause | (join_clause) } ] ... [ where_clause ] [ hierarchical_query_clause ] [ group_by_clause ] [ model_clause ]
order_by_clause ::=
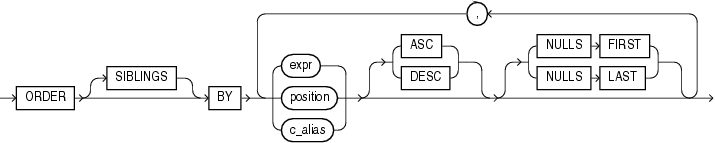
ORDER [ SIBLINGS ] BY { expr | position | c_alias } [ ASC | DESC ] [ NULLS FIRST | NULLS LAST ] [, { expr | position | c_alias } [ ASC | DESC ] [ NULLS FIRST | NULLS LAST ] ]...
row_limiting_clause::=
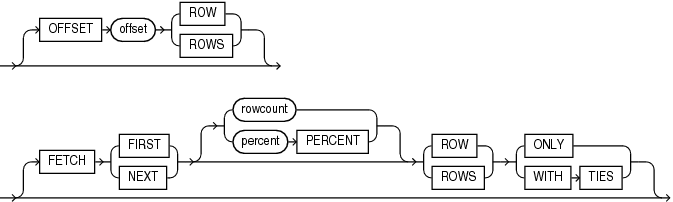
[ OFFSET offset { ROW | ROWS } ] [ FETCH { FIRST | NEXT } [ { rowcount | percent PERCENT } ] { ROW | ROWS } { ONLY | WITH TIES } ]
6.插入记录 INSERT
【语法】 INSERT 官方文档
insert::=
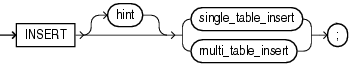
INSERT [ hint ] { single_table_insert | multi_table_insert } ;
single_table_insert ::=

insert_into_clause { values_clause [ returning_clause ] | subquery } [ error_logging_clause ]
multi_table_insert ::=

{ ALL
{ insert_into_clause [ values_clause ] [error_logging_clause] }...
| conditional_insert_clause
} subquery
7.更新记录 UPDATE
【语法】UPDATE 官方文档
update::=

UPDATE [ hint ] { dml_table_expression_clause | ONLY (dml_table_expression_clause) } [ t_alias ] update_set_clause [ where_clause ] [ returning_clause ] [error_logging_clause] ;
DML_table_expression_clause::=

{ [ schema. ]
{ table
[ partition_extension_clause
| @ dblink
]
| { view | materialized view } [ @ dblink ]
}
| ( subquery [ subquery_restriction_clause ] )
| table_collection_expression
}
8.删除记录 DELETE
【语法】DELETE 官方文档
delete::=

DELETE [ hint ] [ FROM ] { dml_table_expression_clause | ONLY (dml_table_expression_clause) } [ t_alias ] [ where_clause ] [ returning_clause ] [error_logging_clause];
DML_table_expression_clause::=
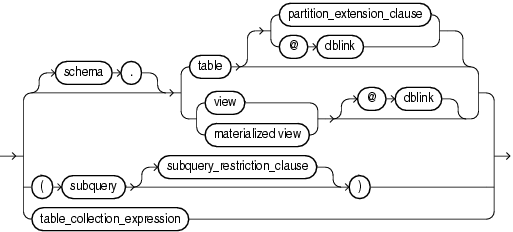
{ [ schema. ]
{ table
[ partition_extension_clause
| @ dblink
]
| { view | materialized view } [ @ dblink ]
}
| ( subquery [ subquery_restriction_clause ] )
| table_collection_expression
}
【例子】
创建普通表 #使用dba用户登录数据库 SQL> conn / as sysdba; #创建临时员工表temp_employees SQL> create table scott.temp employees (employee_id number(17),employee_name varchar(30),employee_sex char,department varchar(30)) tablespace users; #验证是否成功创建表temp_employees SQL> select owner,table_name,tablespace_name from dba_tables where owner = 'SCOTT'; #创建本地管理的表lin SQL> create tablespace lin datafile '/u01/app/oracle/oradata/orcl/lin.dbf' size 30M extent management local uniform size 1M; SQL> create table scott.employees (ecode number(17),ename varchar2(25),eaddress varchar2(30),ephone varchar2(15)) storage (initial 100k next 100k pctincrease 0 minextents 1 maxextents 8) tablespace lin; #验证是否成功创建表employees SQL> select table_name,tablespace_name,initial_extent,next_extent from dba_tables where owner = 'SCOTT' and table_anme = 'EMPLOYEES'; 创建临时表 #使用create global temporary创建临时表 SQL> create global temporary table scott.emp_temporary on commit preserve rows as select * from scott.emp where job = 'MANAGER'; #验证是否成功创建该临时表 SQL> select owner,table_name,tablespace_name from dba_tables where table_name = 'EMP_TEMPORARY'; #查询表emp_temporary是否为临时表 SQL> select table_name,tablespace_name,temporary from dba_tables where owner = 'SCOTT' and table_name = 'EMP_TEMPORARY'; #查询临时表emp_temporary的输出结果,不存在 SQL> conn / as sysdba; SQL> desc scott.emp_temporary; SQL> select * from emp_temporary; #删除临时表 SQL> drop table scott.emp_temporary; 高水位线(HWM) oracle访问数据实现全表扫描的数据块范围,truncate会调整HWM到表段的第一个数据块,delete不会。 行迁移 某一行的数据量过大,导致改行无法存储在创建这一行的数据块中,此时oracle就会使得该行离开原来的块,存储到另一个数据块中,该行的原始块和新块之间用rowid记录这种变迁关系,使得原始行知道后续数据存储的位置。 索引组织表(IOT) 数据和索引存储在一起,按照索引的结构来组织和存储表中的数据。表中的数据按照某个主键排序后存储,然后再以B树的组织结构存储在数据段中。IOT适合于完全由主键组成的表,或者只通过一个主键来访问一个表。 #创建索引组织表 SQL> create table tiot (x int primary key,y number, z varchar2(20)) organization index; #提取表定义元数据 SQL> select DBMS_METADATA.GET_DDL('TABLE','TIOT') FROM DUAL; #创建索引组织表 SQL> create table iot_test (x int,y number,z varchar2(20),constraint inot_test_pk primary key(x)) organization index pctthreshold 10 including y overflow tablespace users; organization index: 说明这是一个索引组织表 overflow: 允许创建一个新段,如果IOT的行记录太大,可以存储到这个新段上。 including; 行中从第一列直到including 所指定的列的所有列数据都存储在索引块上,其余列存储在溢出段上。 pctthreshold: 如果行中的数据量超过了数据块大小的这个百分比,行中其余数据就要放入溢出段。 compress(键压缩): 跟普通的索引一样,索引组织表也可以使用compress子句进行键压缩以消除重复值。 intrans: 控制对数据块的并行操作,定义了创建数据块时事务槽的初始值 #登录数据库并查看表dept的行id(rowid) SQL> conn scott/oracle; SQL> select deptno,dname,loc,rowid from dept; #查看scott用户的表empolyees的表参数initrans和maxtrans SQL> select ini_trans,max_trans from dba_tables where owner = 'SCOTT' and table_name = 'EMPLOYEES'; #查询scott用户的表employees的参数设置 SQL> select table_name,tablespace_name,pct_free,pct_used from dba_tables where owner = 'SCOTT' and table_name = 'EMPLOYEES'; #动态修改表的参数pctused和pctfree SQL>alter table scott.employees pctused 50 pctfree 30; #查看对表参数pctused和pctfree的修改结果 SQL>select table_name,tablespace_name,pct_free,pct_used from dba_tables where owner = 'SCOTT' and table_name - 'EMPLOYEES'; maxtrans: 定义了创建数据块时事务槽的最大值 pctfree: 设置每个数据块中预留空间的百分比数,默认值为10% freelists: 空闲数据块队列的列表 pctused: 数据块中已经使用空间的百分比数 #向表employees中插入数据 SQL> insert inot scott.employees values (1,'Tom','address1','8085173170'); #查询表employees中的所有数据 SQL> select * from scott.employees; #向表employees中增加一列sex SQL> alter table scott.employees add (sex char); #验证是否向表employees中增加了一列 SQL> col ename for a10; SQL> col eaddress for a20; SQL> col sex for a10; SQL> select * from scott.employees; #向表employees中增加一列 SQL> alter table scott.employees add (degree varchar2(10)); #更新员工Tom的sex列和degreee列的值 SQL> update scott.employees set sex = 'm',degree='Bachelor' where ename = 'Tom'; #查询修改结果 SQL> col sex for a3; SQL> col eaddress for a10; SQL> select * from scott.employees; #将表employees中的列degree设置为不允许为空 SQL> alter table scott.employees modify (degree varchar2(10) not null); SQL> desc scott.employees; #删除表employees中的列degree SQL> alter table scott.employees drop column degree; #将表employees中的列ephone设置为无用列 SQL> alter table scott.employees set unused column ephone; SQL> select * from scott.empoyees; #删除表employees中设置为unused的列 SQL> alter table scott.employees drop unused columns; #将表employees中的列sal改为salary SQL> alter table scott.emp rename column sal to salary; SQL> desc scott.emp; #创建表emp_temp SQL> create table scott.emp_temp as select * from scott.emp; #截断表emp_temp SQL> truncate table scott.emp_temp; SQL> desc scott.emp_temp; SQL> select * from scott.emp_temp; #删除表emp_temp SQL> drop table scott.emp_temp;
参考资料
[1] 林树泽.Oracle 11g R2 DBA操作指南[M].北京:清华大学出版社,2013
[2] http://docs.oracle.com/database/121/SQLRF/statements_7002.htm#SQLRF01402
[2] oracle 表的管理
[3] ORACLE_创建和管理表
[5] Oracle中创建和管理表详解
[7] Oracle中查看所有表和字段
[8] Oracle分区表 (Partition Table) 的创建及管理
[9] oracle中创建临时表方法
[10] Oracle 创建临时表的语法
[11] ORACLE临时表总结
[12] Oracle临时表总结
[13] Oracle高水位线(HWM)及性能优化
[14] 一、oracle 高水位线详解
[15] Oracle表段中的高水位线HWM
[16] Oracle 高水位线和全表扫描
[17] Oracle 高水位线详解
[18] 浅谈Oracle的高水位线--HWM
[19] 简述Oracle IOT(Index Organized Table)(上)
[20] 简述Oracle IOT(Index Organized Table)
[21] 简述Oracle IOT(Index Organized Table)(中)
[22] Oracle 自动段空间管理(ASSM:auto segment space management)
[24] oracle 行连接和行迁移
[25] Oracle行迁移和行链接详解(原创)
[26] Oracle行迁移和行链接