2018-02-24
2月22号,发现namenode02服务器的namenode(standby)节点挂掉,查看hadoop日志/app/hadoop/logs/hadoop-appadm-namenode-prd-bldb-hdp-name02.log
发现2018-02-17 03:29:34,首次报出java.lang.OutOfMemoryError的ERROR,具体报错信息如下
2018-02-17 03:29:34,485 ERROR org.apache.hadoop.hdfs.server.namenode.EditLogInputStream: caught exception initializing http://datanode01:8480/getJournal?jid=cluster1&segmentTxId=2187844&storageInfo=-63%3A1002064722%3A1516782893469%3ACID-02428012-28ec-4c03-b5ba-bfec77c3a32b java.lang.OutOfMemoryError: unable to create new native thread at java.lang.Thread.start0(Native Method) at java.lang.Thread.start(Thread.java:714)
之后在2018-02-17 03:34:34,Shutting down standby NN
2018-02-17 03:34:34,495 FATAL org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer: Unknown error encountered while tailing edits. Shutting down standby NN. java.lang.OutOfMemoryError: unable to create new native thread at java.lang.Thread.start0(Native Method) at java.lang.Thread.start(Thread.java:714) at java.util.concurrent.ThreadPoolExecutor.addWorker(ThreadPoolExecutor.java:949) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1371) at com.google.common.util.concurrent.MoreExecutors$ListeningDecorator.execute(MoreExecutors.java:440) at com.google.common.util.concurrent.AbstractListeningExecutorService.submit(AbstractListeningExecutorService.java:56) at org.apache.hadoop.hdfs.qjournal.client.IPCLoggerChannel.getEditLogManifest(IPCLoggerChannel.java:553) at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.getEditLogManifest(AsyncLoggerSet.java:270) at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.selectInputStreams(QuorumJournalManager.java:474) at org.apache.hadoop.hdfs.server.namenode.JournalSet.selectInputStreams(JournalSet.java:278) at org.apache.hadoop.hdfs.server.namenode.FSEditLog.selectInputStreams(FSEditLog.java:1590) at org.apache.hadoop.hdfs.server.namenode.FSEditLog.selectInputStreams(FSEditLog.java:1614) at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer.doTailEdits(EditLogTailer.java:216) at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.doWork(EditLogTailer.java:342) at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.access$200(EditLogTailer.java:295) at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread$1.run(EditLogTailer.java:312) at org.apache.hadoop.security.SecurityUtil.doAsLoginUserOrFatal(SecurityUtil.java:455) at org.apache.hadoop.hdfs.server.namenode.ha.EditLogTailer$EditLogTailerThread.run(EditLogTailer.java:308) 2018-02-17 03:34:34,500 INFO org.apache.hadoop.util.ExitUtil: Exiting with status 1
当天检查系统内存使用情况,发现的确剩余内存不足,于是手动释放了内存,并重新启动了namenode02节点。
free -g sync echo 3 > /proc/sys/vm/drop_caches echo 1 > /proc/sys/vm/drop_caches # 在namenode02节点执行, su - appadm hadoop-daemon.sh start namenode
为了验证释放是由于namenode节点剩余内存不足,而导致的namenode(standby)挂掉,开发人员调整了MapReduce JOB的运行频率。为了尽快模拟出长时间运行后的状态,抽了一个原本1天跑一次的JOB改成5分钟跑一次。
在持续跑了2天JOB之后,从云平台CAS监控上看到namenode主机的历史内存使用趋势图
22 号17:00~18:00 增加了JOB运行频率,22号18:20之前,内存使用率维持在40%左右,18:20~19:10,线性增长到70%,并维持在这个水平,一直到23号 14:42,之后缓慢增长,突破80%临界值。 在24号 0:00~1:00 这个时间段,达到90%的峰值。
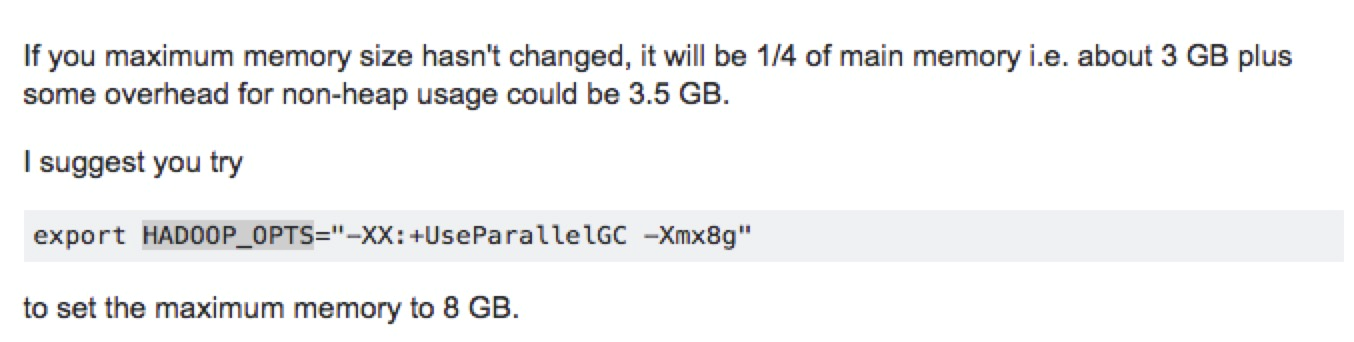
根据stackoverflow上面,对该问题的描述,提问题的人物理内存是12G,也就是建议把 -Xmx值设置为物理内存的3/4。我们生产环境的namenode 物理内存为8G,datanode 物理内存为 125G
https://stackoverflow.com/questions/9703436/hadoop-heap-space-and-gc-problems
18:43 2018-2-24 保理Hadoop生产集群变更
在5台服务器上分别执行,以下命令
vim /app/hadoop/etc/hadoop/hadoop-env.sh
添加如下参数
export HADOOP_OPTS="-XX:+UseParallelGC -Xmx4g"
为了方便日后操作,特记录下集群重启操作步骤
保理Hadoop/Hive/HBase/Zookeeper集群 重启操作步骤 ######################################################## ############ 1、关闭 Hive # 在namenode01,关闭hiveserver2 lsof -i :9999|grep -v "ID"|awk '{print "kill -9",$2}'|sh
# 在datanode01,关闭metastore
ps -ef |grep HiveMetaStore |grep -v grep|awk '{print "kill -9",$2}'|sh ############ 2、关闭 HBase # 在namenode01执行,关闭HBase stop-hbase.sh ############ 3、关闭 Hadoop # 在namnode01执行,关闭Hadoop stop-all.sh ############ 4、关闭 Zookeeper # 在3个datanode节点执行 zkServer.sh stop zkServer.sh status ######################################################## 手动释放Linux系统内存 sync echo 3 > /proc/sys/vm/drop_caches echo 1 > /proc/sys/vm/drop_caches ######################################################## ############ 5、启动 Zookeeper # 在3个datanode节点执行 zkServer.sh start zkServer.sh status ############ 6、启动 Hadoop # 在namenode01执行 start-all.sh # 在namenode02执行,重启namenode hadoop-daemon.sh stop namenode hadoop-daemon.sh start namenode # HDFS Namenode01:9000 (active) WEB UI http://172.31.132.71:50070/ # HDFS Namenode02:9000 (standby) WEB UI http://172.31.132.72:50070/ # YARN WEB UI http://172.31.132.71:8088/ ############ 7、启动 HBase # 在namenode01和namenode02节点,分别执行 start-hbase.sh # Master WEB UI http://172.31.132.71:60010/ # Backup Master WEB UI http://172.31.132.72:60010/ # RegionServer WEB UI http://172.31.132.73:60030/ http://172.31.132.74:60030/ http://172.31.132.75:60030/ ############ 8、启动 Hive # 在namenode01,启动hiveserver2 hive --service hiveserver2 & # 在datanode01,启动metastore hive --service metastore & # 在namenode01,启动hwi(Web界面) hive --service hwi & # HWI WEB UI http://172.31.132.71:9999/hwi ########################################################
加完参数,并重启了整个hadoop/hbase集群之后,内存使用率已经降了下来,以下是刚重启完之后的namenode服务器内存使用情况,等观察2天后,再继续上图