前言
离线安装好CDH、Coudera Manager之后,通过Coudera Manager安装所有自带的应用,包括hdfs、hive、yarn、spark、hbase等应用,过程很是波折,此处就不抱怨了,直接进入主题。
描述
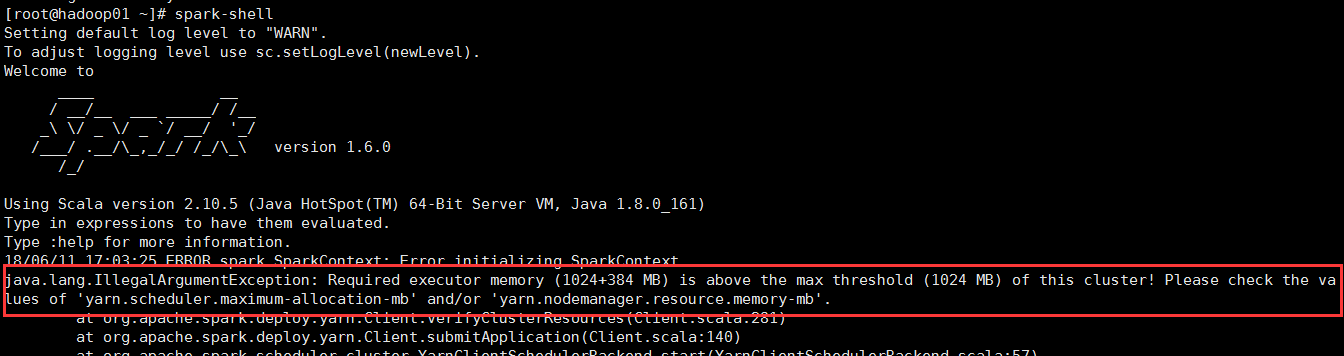
在安装有spark的节点上,通过spark-shell启动spark,满怀期待的启动spark,but,来了个晴天霹雳,报错了,报错了!错误信息如下:


18/06/11 17:40:27 ERROR spark.SparkContext: Error initializing SparkContext. java.lang.IllegalArgumentException: Required executor memory (1024+384 MB) is above the max threshold (1024 MB) of this cluster! Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'. at org.apache.spark.deploy.yarn.Client.verifyClusterResources(Client.scala:281) at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:140) at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:57) at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:158) at org.apache.spark.SparkContext.<init>(SparkContext.scala:538) at org.apache.spark.repl.SparkILoop.createSparkContext(SparkILoop.scala:1022) at $line3.$read$$iwC$$iwC.<init>(<console>:15) at $line3.$read$$iwC.<init>(<console>:25) at $line3.$read.<init>(<console>:27) at $line3.$read$.<init>(<console>:31) at $line3.$read$.<clinit>(<console>) at $line3.$eval$.<init>(<console>:7) at $line3.$eval$.<clinit>(<console>) at $line3.$eval.$print(<console>) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.repl.SparkIMain$ReadEvalPrint.call(SparkIMain.scala:1045) at org.apache.spark.repl.SparkIMain$Request.loadAndRun(SparkIMain.scala:1326) at org.apache.spark.repl.SparkIMain.loadAndRunReq$1(SparkIMain.scala:821) at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:852) at org.apache.spark.repl.SparkIMain.interpret(SparkIMain.scala:800) at org.apache.spark.repl.SparkILoop.reallyInterpret$1(SparkILoop.scala:857) ....................后面还有很多错误信息
仔细查看错误信息之后发现,原来是yarn配置的内存不够,spark启动需要1024+384 MB的内存,但是我的yarn配置仅有1024 MB,不够满足spark启动要求,所以抛出异常,关键错误信息如下图所示:
解决方法
登录Cloudera Manager,找到YARN (MR2 Included),点击进如(不要在意我的集群有那么多警告和报错,解决spark问题是关键),如下图所示:
在导航栏找到 配置 选项,如下图所示:
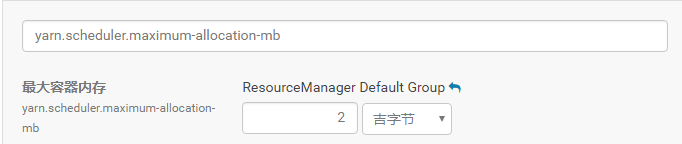
点击进入 配置 页面,在搜索栏中输入yarn.scheduler.maximum-allocation-mb,如下图所示:

可以看到,该配置参数的值正如spark启动时抛出的异常所示,为1GB,将其修改为2GB即可,点击保存更改,如下图所示:
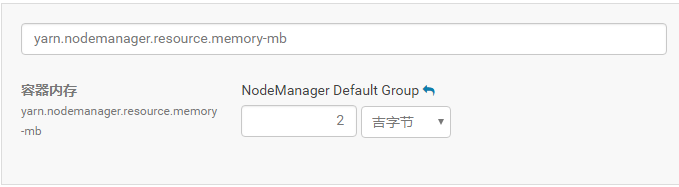
 按照上述的步骤,继续修改yarn.nodemanager.resource.memory-mb 参数的值为2GB,如下图所示,点击保存更改,重启yarn使设置生效。
按照上述的步骤,继续修改yarn.nodemanager.resource.memory-mb 参数的值为2GB,如下图所示,点击保存更改,重启yarn使设置生效。
返回到spark节点命令行里面执行spark-shell命令,奇怪,仍然报错,但错误为其他,不再是上面的错误,错误信息为
18/06/11 17:46:46 ERROR spark.SparkContext: Error initializing SparkContext. org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/user":hdfs:supergroup:drwxr-xr-x at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.checkFsPermission(DefaultAuthorizationProvider.java:279) at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.check(DefaultAuthorizationProvider.java:260) at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.check(DefaultAuthorizationProvider.java:240) at org.apache.hadoop.hdfs.server.namenode.DefaultAuthorizationProvider.checkPermission(DefaultAuthorizationProvider.java:162) at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:152) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:3530) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkPermission(FSDirectory.java:3513) at org.apache.hadoop.hdfs.server.namenode.FSDirectory.checkAncestorAccess(FSDirectory.java:3495) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkAncestorAccess(FSNamesystem.java:6649) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInternal(FSNamesystem.java:4420) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInt(FSNamesystem.java:4390) at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:4363) ...........................后面还有很多不重要的
关键错误信息如下图所示:
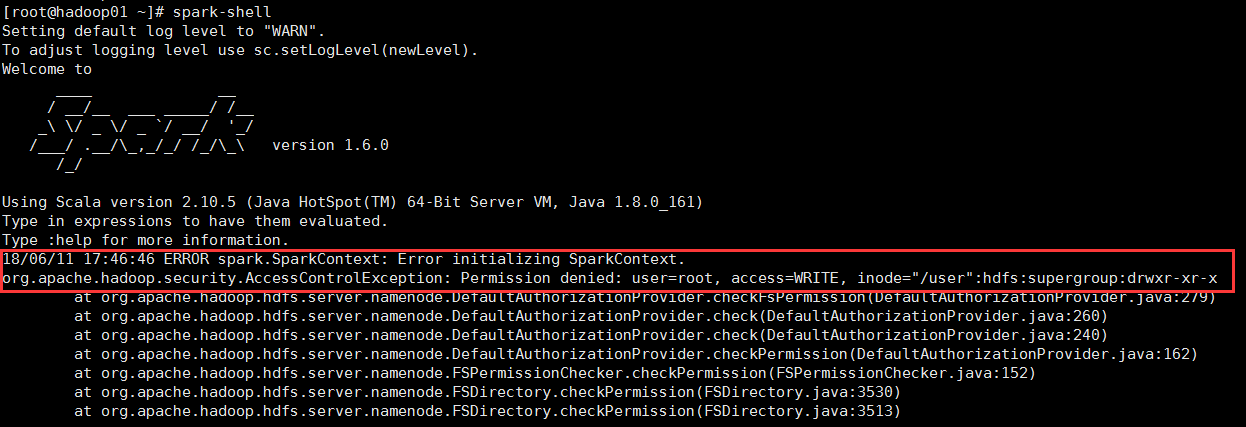
原因是启动spark的用户权限不够,我是使用root命令启动spark,需要hdfs用户启动spark(注:hdfs是hadoop的超级用户),所以报错,切换到hdfs用户下,再次启动是spark,成功。

补充
yarn.scheduler.maximum-allocation-mb 参数的作用:该参数在yarn-site.xml配置文件中配置,设置yarn容器的最大分配内存,以MB为单位,如果yarn资源管理器(RM/ResourceManager)中的容器请求的资源大于此处设置的值,就会抛出无效资源请求异常(InvalidResourceRequestException)。
yarn.nodemanager.resource.memory-mb参数的作用:该参数在yarn-site.xml配置文件中配置,设置yarn节点上可用的物理内存,默认大小为8192(MB),该内存可用于分配给yarn容器。