1.集群简介
Hadoop集群具体来说包括两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起。
HDFS集群:负责海量数据的存储,集群中的角色主要有NameNode/DataNode
YARN集群:负责海量数据运算时的资源调度,集群中的角色主要有ResourceManage/NodeManager
2.服务器准备
操作系统:
| 虚拟机系统 | 节点 | 域名/IP地址 |
|---|---|---|
| Centos6 | NameNode/ResourceManage | Master/192.168.1.10 |
| Centos6 | DataNode/NodeManageer | Salve11/192.168.1.11 |
| Centos6 | DataNode/NodeManageer | Salve12/192.168.1.12 |
| Centos6 | DataNode/NodeManageer | Salve13/192.168.1.13 |
Java版本
java version "1.8.0_151"
Hadoop版本
3.网络环境准备
3.1.设置IP地址
分别设置节点IP,在每个节点上执行一下步骤:
vi /etc/sysconfig/network-scripts/ifcfg-eth0
修改如下:
DEVICE=eth0
HWADDR=08:00:27:53:7E:9D
TYPE=Ethernet
UUID=c8127b91-f551-4630-a272-babb99157433
ONBOOT=yes #使用yes
NM_CONTROLLED=yes
BOOTPROTO=static #使用静态方法
IPADDR=192.168.1.10 #指定ip地址
NETMASK=255.255.255.0 #指定子网掩码
GATEWAY=
重启网络服务:
service network restart
3.2.设置域名
修改域名
打开vi /etc/sysconfig/network:
编辑:
NETWORKING=yes
HOSTNAME=master ##此处修改域名
重启设备reboot。
注意,在每个节点上配置不同的网络ip和域名。配置的ip地址在上面的表格中。
4.SSH免登陆设置
4.1.修改hosts文件
分别在每个节点添加域名到ip地址的映射
打开:vi /etc/hosts
编辑:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
#添加以下内容
192.168.1.10 master
192.168.1.11 salve11
192.168.1.12 salve12
192.168.1.13 salve13
4.2.设置节点之间的免登录
每个节点上执行如下命令:
ssh-keygen -t rsa,产生钥匙,输入后一直回车
ssh-copy-id -i master
ssh-copy-id -i salve11
ssh-copy-id -i salve12
ssh-copy-id -i salve13
4.3.关闭节点防火墙
- 查看防火墙状态
service iptables status - 关闭防火墙
service iptables stop - 查看防火墙开机启动状态
chkconfig iptables --list - 关闭防火墙开机启动
chkconfig iptables off
4.4.关闭SELinux
- 查看SELinux状态
getenforce - 临时开启SELinux
setenforce 1 - 开机关闭SELinux
编辑/etc/selinux/config文件,将SELINUCX的值设置位disabled
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
SELINUX=disable #设置为不随开机启动
# SELINUXTYPE= can take one of these two values:
# targeted - Targeted processes are protected,
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
注意:此时也不能通过setenforce 1命令临时开打。
5.Java环境安装
5.1.下载java jdk安装包
点击:Java SE Development Kit 8 下载,下载适用于linux系统的java8 的JDK套件。
下载时要先选择接受许可协议,并下载64位的:dk-8u151-linux-x64.rpm。

5.2.linux上安装
上传到linux系统,使用rpm -ivh dk-8u151-linux-x64.rpm进行安装。
5.3.添加java资源路径
安装之后,添加java的资源路径:
vi /etc/profile
在文件最后添加如下:
export JAVA_HOME=/usr/java/jdk1.8.0_151
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
更新配置:
source /etc/profile
5.4.测试java环境
测试java环境,执行java -version,即可查看java的版本。
如下:
[root@node101 ~]# java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
6.Hadoop安装部署
1.6.1.下载Hadoop
在apache的官网下载Hadoop,选择版本2.7.5,使用binary安装。如下图:
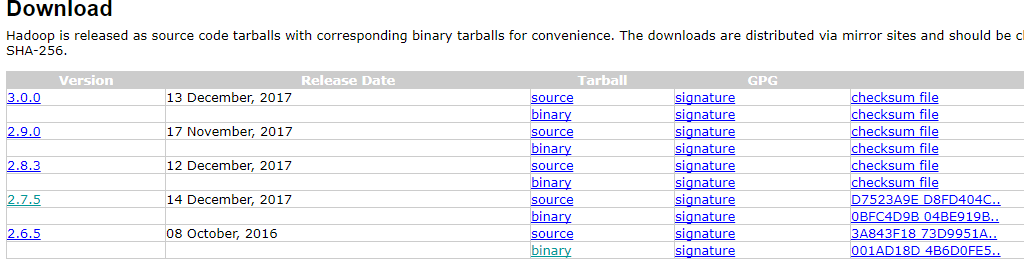
下载后,传输到master上
6.2.安装
在master上操作:
解压hadoop:
tar -zxvf hadoop-2.7.5.tar.gz
移动到指定位置:
mv hadoop-2.7.5 /usr/hadoop
6.3.配置
在master上,进入到hadoop的安装目录:/usr/hadoop,再进入hadoop的环境配置目录:/usr/hadoop/etc/hadoop。然后进行以下设置
1.修改Java路径
vi hadoop-env.sh
在第27行,修改java的路径,此处的路径应该是上文设置的JAVA_HOME路径。修改如下:
export JAVA_HOME=/usr/java/jdk1.8.0_151
2.修改core-site.xml
<configuration>
<!-- 指定Hadoop所使用的文件系统schema,HDFS老大的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定Hadoop运行时产生的文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
</property>
</configuration>
3.修改hdfs-site.xml
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 指定HDFS系统namenode路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/root/hadoop/dfs/name</value>
</property>
<!-- 指定HDFS系统datanode路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/root/hadoop/dfs/data</value>
</property>
<!-- 指定HDFS系统secondarynamenode路径 -->
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.1.10:50090</value>
</property>
</configuration>
4.mapred-site.xml
如果mapred-site.xml文件不存在,需要复制一个过来:mv mapred-site.xml.template mapred-site.xml。
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5.修改yarn-site.xml
<configuration>
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
把在master上配置好的/usr/hadoop目录分发到每个salve上。使用命令如下:
scp -r /usr/hadoop salve11:/usr/hadoop,
salve12和salve13同样操作。
6.4.添加到环境变量
需要在每个节点添加Hadoop的环境,主要添加下面两条:
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin
到此为之,添加过java和hadoop,此时的/etc/profile自己添加的部分如下:
export JAVA_HOME=/usr/java/jdk1.8.0_151
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
更新配置文件
source /etc/profile
每个节点上创建以下几个目录:
/root/hadoop/tmp
/root/hadoop/dfs/name
/root/hadoop/dfs/data
7.启动集群
修改master节点上的以下文件:
vi /usr/hadoop/etc/hadoop/slaves
添加如下:
salve11
salve12
salve13
在master上执行以下命令开启集群
先格式hadoop:
hdfs namenode -format
启动hdfs:
/usr/hadoop/sbin/start-dfs.sh
再启动yarn:
/usr/hadoop/sbin/start-yarn.sh
使用jps命令可以查看集群启动是否成功。
在master上执行jps,返回如下,表示正确启动:
[root@master hadoop]# jps
3393 Jps
2660 SecondaryNameNode
3111 ResourceManager
2471 NameNode
salve11等其他节点执行jsp,返回如下结果,表示正确启动
[root@salve11 usr]# jps
2502 Jps
2380 NodeManager
2268 DataNode
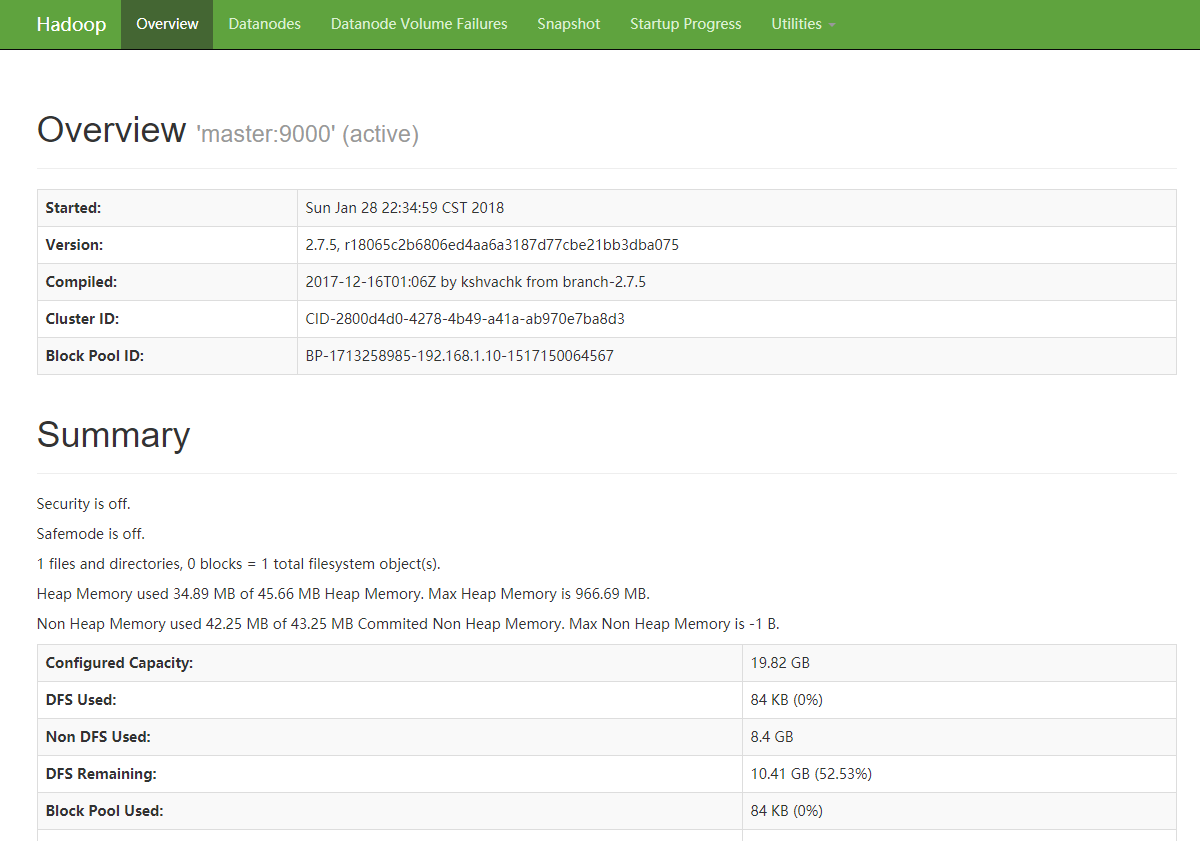
可以通过网页访问查看
网页访问:http://192.168.1.10:50070
访问后截图如下:
8.其他
也可以单独开启一个节点的namenode或者datanode,使用命令如下:
hadoop-daemon.sh start namenode
或
hadoop-daemon.sh start datanode