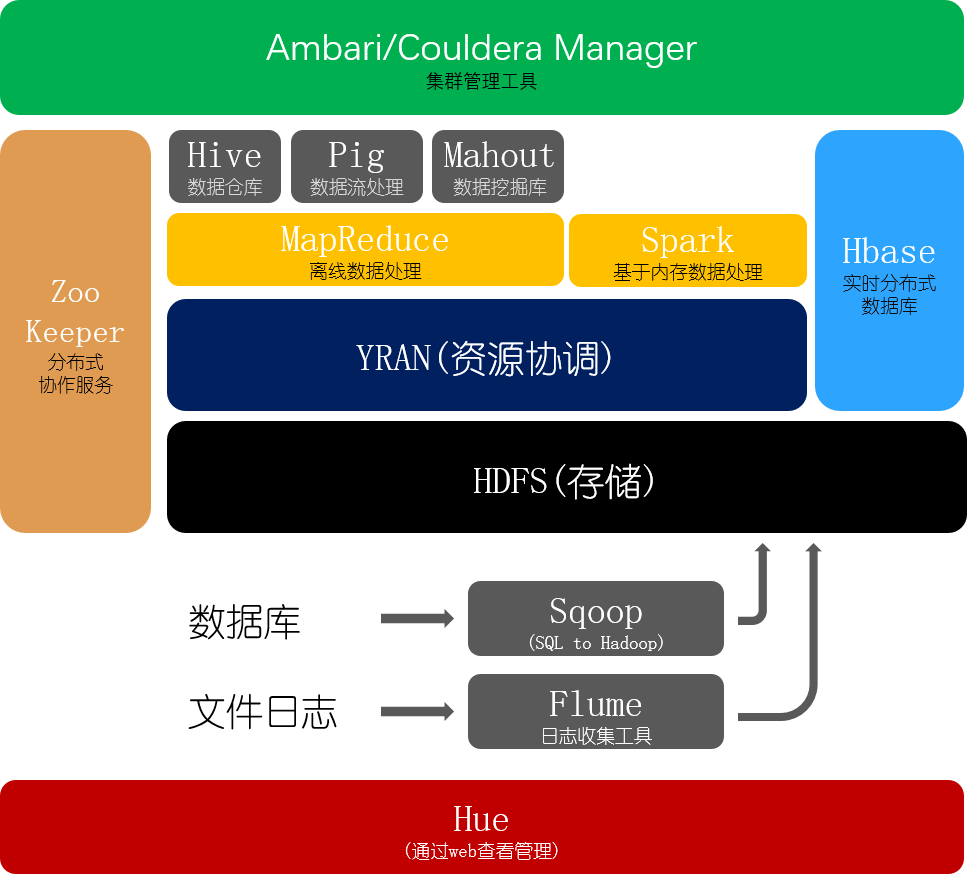
Hadoop生态架构图
参考文章:
Hadoop生态系统介绍
HDFS架构
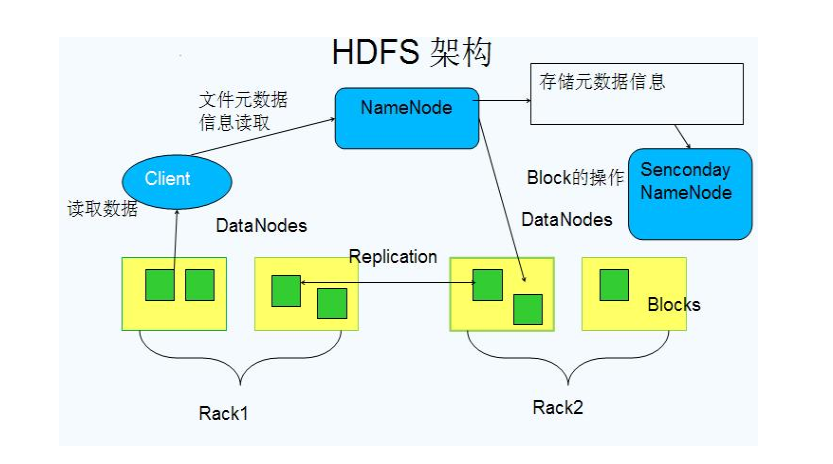
1.NaneDode:主节点,**存储文件的元数据**如文件名,文件目录结构,文件属性(生成时间,副本数量,文件权限),以及每个文件的块列表所在DataNode等
一个JAVA进程:数据存储在内存中,为了速度读写(本地还有备份)
本地磁盘:1、fsimage:镜像文件
2、edits :编辑日志
2.DataNode:数据节点,实际的本地文件系统,**存储文件块数据,以及快数据的检验和**
真正的存储:数据在磁盘中
3.Secondary NameNode用来**监控HDFS状态的辅助后台程序**,每隔一段时间**获取HDFS元数据快照**,就是定时对本地磁盘的 NameNode 的 fsimage 和 edits 进行合并,不断更新镜像
数据以block方式存储
Hadoop2.x块大小:128M
参考文章:
HDFS 原理、架构与特性介绍
谷歌三大核心技术(一)Google File System中文版
YARN架构

1.ResourceManager 资源管理者
*接收客户端请求
*启动/监控ApplicationMaster
*监控NodeManager
*资源分配与调度
2.NodeManager 节点管理者
*管理节点资源
*处理来自ResourceManager的任务
*处理来自ApplicationMaster的任务
3.ApplicationMaster 应用主管
*数据切分
*为应用程序向ResourceManager提出资源申请,并分配给内部任务
*任务监控与容错
4.container 容器
*对任务运行环境的抽象,封装了CPU,内存等多维资源以及环境变量,启动命令等运行任务的相关信息
参考文章:
Hadoop构架概览
MapReduce框架(离线运算框架)
1.将数据计算过程分为两个阶段 Map 和 Reduce
*Map将数据进行并行处理
*Reduce将处理结果进行汇总
2.shuffle 连接 Map 和 Reduce 阶段
*Map Task 将数据存储到本地磁盘
*Reduce Task 将数据从 Map Task 上读一份数据
特点:
*仅适合离线数据处理,有极高的容错性和拓展性,适合简单批处理任务
*启动开销大,过多使用磁盘导致效率低下
MapReduce on YRAN
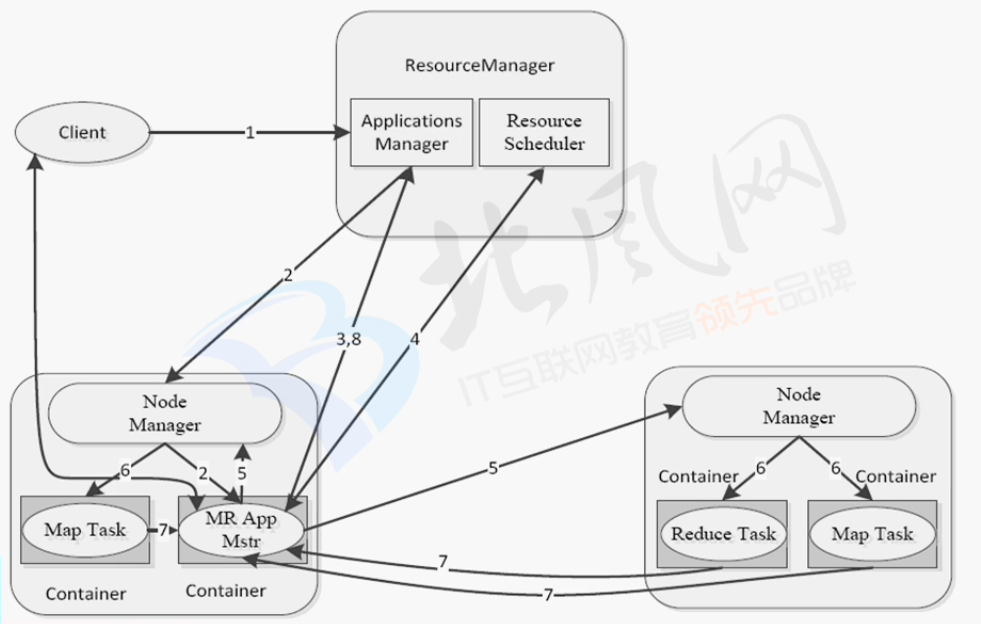
从客户端到客户端中间的过程详解图
注:图片来源见水印,侵删