上篇文档忘说环境了:
hadoop-1.0.2.tar
jdk-6u38-linux-x64
CentOS-6.4-x86_64
下面增加数据节点:
添加前记录:

1、修改新节点的主机名:

hostname:
2、修改hosts文件,增加新节点:

3、修改master节点的slave文件:

4、在新增加的机器上启动 datanode 和 tasktracker
命令如下:在新机器上进入hadoop安装目录
$hadoop-daemon.sh start datanode$hadoop-daemon.sh start tasktracker
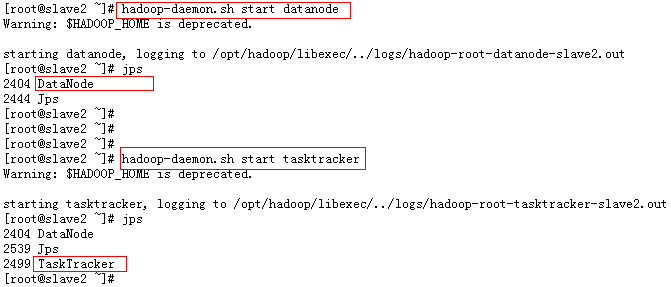
5、这时在master节点上就可以看到新节点了:

6、其他上面就已经添加成功了,但如果这前的数据已经很多了,我们可以使用hadoop的命令来平衡一下,datanode数据到新增节点上(如果是新环境,没有数据,那就没有这个执行的必要了):
这个命令需要到master主节点上执行 也就是 namenode节点上执行:
hadoop balancer

但有个问题: 这样添加完成,,hadoop是可以正常使用了,但 如果通过生产机启停全部是操作不了,那就是SSH;

所以最后一步,还需要配置 SSH了 ;