hadoop 三台主机环境搭建详细记录
自己搭建的操作记录,
太详细了,,感觉就有些罗嗦了。。。
下面开始:
分别安装三台centos系统:
系统安装完成后,使用的root用户搭建的没有创建其它用户;
1、修改主机名称:
vim /etc/sysconfig/network

注意:三台主机都需要修改 ,
可以修改成 hadoop1、hadoop2、hadoop3,
或修改成:master、slave1、slave2
或修改成:master.hadoop、slave1.hadoop、slave2.hadoop
修改完成后重启服务:service network restart
第一台主机:![]()


第二台主机:![]()


第三台主机:![]()


2、修改hosts文件:vim /etc/hosts

三台主机都需要修改
3、配置ssh ,三台主机免登录访问
开户ssh服务使用命令:service sshd start
或用setup 中找到service 将sshd打开(开机启动)
ssh-keygen -t rsa(或执行ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa )
在/root/.ssh路径下 cp id_rsa.pub authorized_keys(或cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys)
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
把各个节点的authorized_keys的内容收集到一起,拷贝加入到每个节点的此文件中,然后就可以免密码彼此ssh连入;
步骤如下:

用 ssh-keygen -t rsa命令分别在其他两台主机也执行后

收集id_rsa.pub里面的内容,放入生成的authorized_keys文件中

保存修改后,这时就可以 ssh 当前主机了 :ssh localhost,或 ssh master(当前主机host文件)

ssh slave1 或 ssh slave2 连接主另外两主机,这里还需要输入密码的:
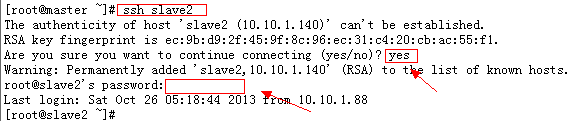
这时只需要 再执行:
scp /root/.ssh/authorized_keys slave1:~/.ssh
scp /root/.ssh/authorized_keys slave2:~/.ssh
这是将 authorized_keys文件复制到另外 slave1 和 slave2 节点上;


4、安装JDK:
我放到了/opt/目录下面
首面赋权限: chmod u+x jdk-6u38-linux-x64.bin
然后执行安装:sudo -s ./jdk-6u38-linux-x64.bin
安装完成后,配置环境变量:修改 /etc/profile(全局变量,或修改vi ~/.bash_profile)添加:
export JAVA_HOME=/opt/jdk1.6.0_38
export PATH=$PATH:$JAVA_HOME/bin
然后使之生效:source /etc/profile
验证是否配置成功:which java
JDK安装配置验证成功后,这时只需要装 安装目录通过scp复制到 其他两台主机 并修改相同的环境变量即可:
待复制完成后,修改slave1主机的profile文件:
vim /etc/profile,添加:
export JAVA_HOME=/opt/jdk1.6.0_38
export PATH=$PATH:$JAVA_HOME/bin
最后使之生效:source /etc/profile
5、安装 hadoop:
a、修改环境变量:/opt/hadoop-1.0.2/conf/hadoop-env.sh文件

b、修改/opt/hadoop-1.0.2/conf/目录下面的 master和 slave两个文件 :
master文件内修改为 做为主节点的 master(hosts文件件内主IP对应的名子)
slave文件内,为两个从节点的名子


c、修改core-site.xml添加如下内容:

d、修改hfds-site.xml文件:
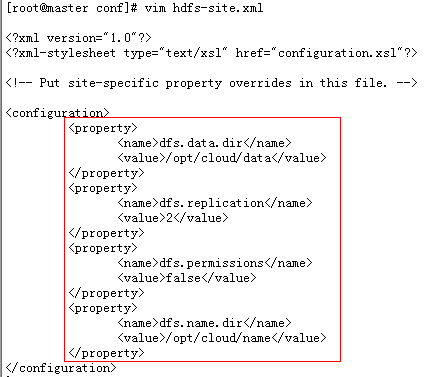
e、修改 mapred-site.xml

f、把Hadoop的安装路径添加到"/etc/profile"中,修改"/etc/profile"文件(配置java环境变量的文件),将以下语句添加到末尾,并使其有效(注意三台主机都需要):
# set hadoop path
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
修改完成后,使之生效:source /etc/profile

g、在/opt/目录下面创建 cloud文件夹,及其下面几个目录(注意三台主机都需要):

h、将配置好的hadoop通过scp复制到其他两个主机,在相同的目录:
scp -r /opt/hadoop slave1:/opt/
scp -r /opt/hadoop slave2:/opt/

至此 hadoop 配置完成了
6、格式化 namenode : hadoop namenode -format

这里注意:主机名 (hostname)一定要与 hosts表里面配置的 ip对应的主机名相同,否则格式化时,会报错,提示找不到主机:STARTUP_MSG: host = java.net.UnknownHostException: master.hadoop: master.hadoop ;
SHUTDOWN_MSG: Shutting down NameNode at java.net.UnknownHostException: master.hadoop : master.hadoop
另:停到三个节点的防火墙 service iptables stop;
7、启动 start-all.sh

8、验证hadoop
(1)验证方法一:用"jps"命令
(2)验证方式二:用"hadoop dfsadmin -report"
1)访问"http//:master:50030"
2)访问"http//:master:50070"