常见分布有如下:

独立同分布:independent and identically distributed, 简称i.i.d
即是说每个的试验结果都是相互独立,不收前后结果影响,且每一次事件A发生的概率都一样
一、连续型随机变量的常见分布
对于连续型随机变量,使用概率密度函数(probability density function简称PDF)来描述其分布情况
连续型随机变量的特点在于取任何固定值的概率都为0,因此讨论其在特定值上的概率是没有意义的,应当讨论其在某一个区间范围内的概率,这就用到了概率密度函数的概念
假定连续型随机变量X,为概率密度函数f(x), 对于任意实数范围如[a,b],有

对于连续型随机变量,通常还会用到累积分布函数 (cumulative distribution function),简称CDF,来描述其性质,在数学上CDF是PDF的积分形式
分布函数F(x)在点处的函数值表示X落在区间内(-∞,x)的概率,所以分布函数就是定义域R为的一个普通函数
1.1均匀分布
均匀分布指的是一类在定义域内概率密度函数处处相等的统计分布。若X是服从区间[a,b]上的均匀分布,则记作X~U[a,b]。
概率密度函数:

分布函数:
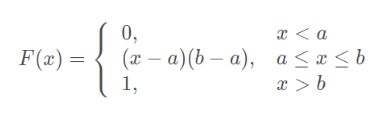
均匀分布的python代码
#1.生成随机数 import numpy as np import matplotlib.pyplot as plt from pylab import mpl # 显示中文 from scipy import stats a=np.random.uniform(low=0,high=1,size=1000) #2.计算PDF和CDF x=np.linspace(0,1,100) p=stats.uniform.pdf(x,loc=0,scale=1) c=stats.uniform.cdf(x,loc=0,scale=1) plt.plot(x,p) plt.plot(x,c) #统计分布可视化 x=np.linspace(0,1,100) t= stats.uniform.rvs(0,1,size=10000) p=stats.uniform.pdf(x, 0, 1) fig, ax = plt.subplots(1, 1) sns.distplot(t,bins=10,hist_kws={'density':True}, kde=False,label = 'Distplot from 10000 samples') sns.lineplot(x,p,color='purple',label='True mass density') plt.title('Uniforml distribution') plt.legend(bbox_to_anchor=(1.05, 1))
1.2正态分布
也叫高斯分布,其密度函数为:

记为X~N(μ,σ), 其中μ为正态分布的均值,σ为正态分布的标准差
有了一般正态分布后,可以通过公式变换将其转变为标准正态分布Z~N(0,1),正态分布的例子有:成人身高
中心极限定理说的是一组独立同分布的随机样本的平均值近似为正态分布,无论随机变量的总体符合何种分布
代码实现
1. 产生正态分布的随机数
# 生成大小为1000的符合N(0,1)正态分布的样本集,可以用np.random.randn(),也可以用normal函数自定义均值,标准差,也可以直接使用standard_normal函数 s = np.random.normal(loc=0,scale=1,size=1000) s1 = np.random.standard_normal(size=1000) # 标准正态 plt.subplot(1, 2, 1) plt.hist(s1) plt.subplot(1, 2, 2) plt.hist(s) # Scipy版本 stats.norm.rvs(0., 1., size=100)
2. 计算pdf和cdf
# 计算正态分布N(0,1)的PDF,CDF x = np.linspace(-3,3,1000) p= stats.norm.pdf(x,loc=0, scale=1) c = stats.norm.cdf(x, loc=0, scale=1) plt.plot(x, p, label='pdf') plt.plot(x, c, label='cdf') plt.legend() stats.norm.pdf(0) #pdf也可以直接求某个点的概率密度 0.398 stats.norm.ppf(0.5) # ppf 可以在累积分布函数上求y对应的x 0.0
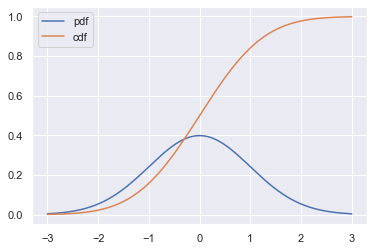
3. 统计可视化
"""统计可视化""" x=np.linspace(-3,3,100) t= stats.norm.rvs(0,1,size=10000) p=stats.norm.pdf(x, 0, 1) fig, ax = plt.subplots(1, 1) sns.distplot(t,bins=100,hist_kws={'density':True}, kde=False,label = 'Distplot from 10000 samples') sns.lineplot(x,p,color='purple',label='True mass density') plt.title('Normal distribution') plt.legend(bbox_to_anchor=(1.05, 1))
4. 不同均值和方差组合的正态分布概率密度函数
#比价不同的均值和方差组合的正态分布概率密度函数 x=np.linspace(-6,6,100) p=stats.norm.pdf(x, 0, 1)
plt.plot(p)
plt.plot(x)
fig, ax = plt.subplots() for mean, std in [(0,1),(0,2),(3,1)]: p=stats.norm.pdf(x, mean, std) sns.lineplot(x,p,label='Mean: '+ str(mean) + ', std: '+ str(std)) plt.title('Normal distribution') plt.legend()

方差越大,取值越离散,表现出来的形状就更矮胖
1.3指数分布
指数分布通常被广泛用在描述一个特定事件发生所需要的时间,在指数分布随机变量的分布中,有着很少的大数值和非常多的小数值
概率密度函数为:
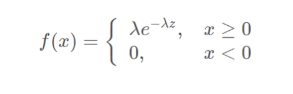
记为X~E(λ),其中λ被称为率参数(rate parameter),表示每单位时间发生该事件的次数
分布函数为:

例子:顾客到达一家店铺的时间间隔、从现在开始到发生地震的时间间隔、在产线上收到一个问题产品的时间间隔
关于指数分布还有一个有趣的性质的是指数分布是无记忆性的,假定在等候事件发生的过程中已经过了一些时间,此时距离下一次事件发生的时间间隔的分布情况和最开始是完全一样的,
就好像中间等候的那一段时间完全没有发生一样,也不会对结果有任何影响,用数学语言来表述是:

1. 随机数和计算pdf, cdf
# 生成大小为1000的符合E(1/2)指数分布的样本集,注意该方法中的参数为指数分布参数λ的倒数 s = np.random.exponential(scale=2,size=1000) # 计算指数分布E(1)的PDF x = np.linspace(0,10,1000) p= stats.expon.pdf(x,loc=0,scale=1) c = stats.expon.cdf(x, loc=0, scale=1) plt.plot(x, p) plt.plot(x, c)
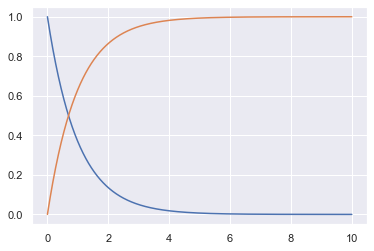
2. 统计可视化
x=np.linspace(0,10,100) t= stats.expon.rvs(0,1,size=10000) p=stats.expon.pdf(x, 0, 1) fig, ax = plt.subplots(1, 1) sns.distplot(t,bins=100,hist_kws={'density':True}, kde=False,label = 'Distplot from 10000 samples') sns.lineplot(x,p,color='purple',label='True mass density') plt.title('Exponential distribution') plt.legend(bbox_to_anchor=(1, 1))

3. 不同参数下的概率密度函数
x=np.linspace(0,10,100) fig, ax = plt.subplots() for scale in [0.2,0.5,1,2,5] : p=stats.expon.pdf(x, scale=scale) sns.lineplot(x,p,label='lamda= '+ str(1/scale)) plt.title('Exponential distribution') plt.legend()

1.4拉普拉斯分布
这个分布在机器学习领域挺常见,并且和L1正则也有关系, 所以在这里简单整理一下, 它和标准正态很像, 标准的正态分布概率密度函数为:

标准的拉普拉斯分布的概率密度函数为:

如图:
x = np.linspace(-5,5,100) y1 = stats.norm.pdf(x) y2 = stats.laplace.pdf(x) plt.plot(x,y1,color='blue',label='norm') plt.plot(x,y2,color='red',label='laplace') plt.legend()
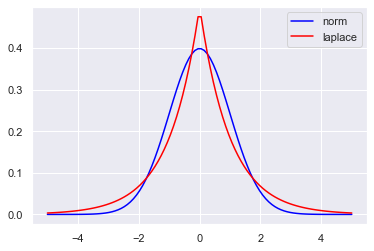
关于两者的对比应用之一就是正则化,其中L1正则化可看做是拉普拉斯先验,L2正则化看作是正态分布的先验。所以要想深度理解正则化,首先要理解这两个概率分布
x = np.linspace(-5,5,100) y1 = stats.laplace.pdf(x) y2 = stats.laplace.pdf(x,loc=0.0,scale=2.) y3 = stats.laplace.pdf(x,loc=1.0,scale=2.) plt.xlabel('x') plt.ylabel('pdf') plt.plot(x,y1,label='u=0;r=1') plt.plot(x,y2,label='u=0;r=2') plt.plot(x,y3,label='u=1,r=2') plt.legend()

二、离散型随机变量及其分布
对于离散型随机变量,使用概率质量函数(probability mass function),简称PMF,来描述其分布律。
假定离散型随机变量X, 共有n个取值,X1,X2,...Xn , 那么
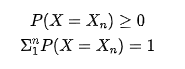
常见的离散型分布:伯努利分布、二项分布、泊松分布
2.1伯努利分布
描述的是离散型变量且发生1次的概率分布,且X取值只有2个, 要么是0, 要么是1:
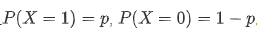
# 创建分布参数p=0.4的伯努利分布,生成满足此分布的 10 个样本点 bern = stats.bernoulli(0.4) bern.rvs(size=(10,))
2.2二项分布
二项分布可以认为是一种只有两种结果(成功/失败)的单次试验重复多次后成功次数的分布概率。
在次试验中, 单次试验成功率为p, 失败率xq=1-p, 则出现成功次数的概率为:
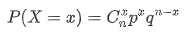
例子:抛硬币正面朝上的次数, 一批产品中有缺陷的产品数量等
# 生成大小为1000的符合b(10,0.5)二项分布的样本集 s = numpy.random.binomial(n=10,p=0.5,size=1000) # 计算二项分布B(10,0.5)的PMF x=range(11) p=stats.binom.pmf(x, n=10, p=0.5) # 统计可视化 x = range(11) # 二项分布成功的次数(X轴) t = stats.binom.rvs(10,0.5,size=10000) # B(10,0.5)随机抽样10000次 p = stats.binom.pmf(x, 10, 0.5) # B(10,0.5)真实概率质量 fig, ax = plt.subplots(1, 1) sns.distplot(t,bins=10,hist_kws={'density':True}, kde=False,label = 'Distplot from 10000 samples') sns.scatterplot(x,p,color='purple') sns.lineplot(x,p,color='purple',label='True mass density') plt.title('Binomial distribution') plt.legend(bbox_to_anchor=(1.05, 1))

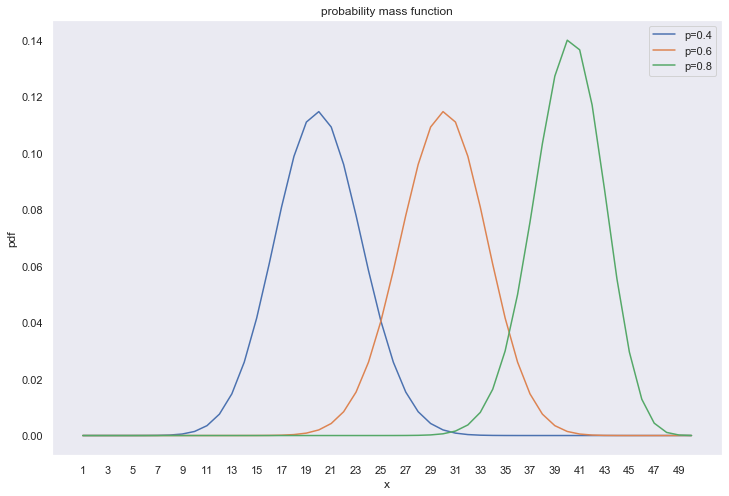
不同参数下的概率质量函数:
plt.figure(figsize=(12,8)) x = np.arange(1,51) y1 = stats.binom.pmf(x,p=0.4,n=50) y2 = stats.binom.pmf(x,p=0.6,n=50) y3 = stats.binom.pmf(x,p=0.8,n=50) plt.grid() plt.xlabel('x') plt.ylabel('pdf') plt.title('probability mass function') plt.xticks(ticks=np.arange(1,51,2)) plt.plot(x,y1,label='p=0.4') plt.plot(x,y2,label='p=0.6') plt.plot(x,y3,label='p=0.8') plt.legend() plt.show()
2.3泊松分布
假设已知事件在单位时间(或者单位面积)内发生的平均次数为λ,则泊松分布描述了事件在单位时间(或者单位面积)内发生的具体次数为k的概率
一个服从泊松分布的随机变量X,在具有比率参数(rate parameter)λ(λ=np)的一段固定时间间隔内,事件发生次数为i的概率为

例子:交通流的预测、一定时间内,到车站等候公交汽车的人数等
# 生成大小为1000的符合P(1)的泊松分布的样本集 s = numpy.random.poisson(lam=1,size=1000) # 计算泊松分布P(1)的PMF x=range(11) p=stats.poisson.pmf(x, mu=1) # 统计可视化 # 比较λ=2的泊松分布的真实概率质量和10000次随机抽样的结果 x=range(11) t= stats.poisson.rvs(2,size=10000) p=stats.poisson.pmf(x, 2) fig, ax = plt.subplots(1, 1) sns.distplot(t,bins=10,hist_kws={'density':True}, kde=False,label = 'Distplot from 10000 samples') sns.scatterplot(x,p,color='purple') sns.lineplot(x,p,color='purple',label='True mass density') plt.title('Poisson distribution') plt.legend()

下面是不同参数对应的概率质量函数:
x=range(50) fig, ax = plt.subplots() for lam in [1,2,5,10,20] : p=stats.poisson.pmf(x, lam) sns.lineplot(x,p,label='lamda= '+ str(lam)) plt.title('Poisson distribution') plt.legend()
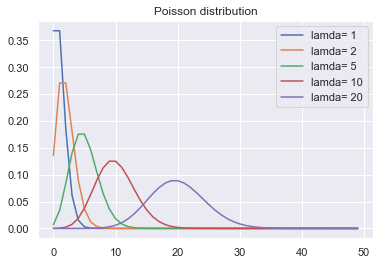
随着参数增大,泊松分布开始逐渐变得对称,分布也越来越均匀,趋近于正态分布。当λ很大时, 比如大于1000, 泊松分布可以近似为正态。
下面看一下泊松和二项分布的比较:
plt.figure(figsize=(12,8)) x = np.arange(1,51) y1 = stats.binom.pmf(x,p=0.4,n=50) y2 = stats.poisson.pmf(x,20) plt.grid() plt.xlabel('x') plt.ylabel('pmf') plt.title('probability mass function') plt.xticks(ticks=np.arange(1,51,2)) plt.plot(x,y1,label='binom:p=0.4,n=50') plt.plot(x,y2,label='u=20') plt.legend() plt.show()
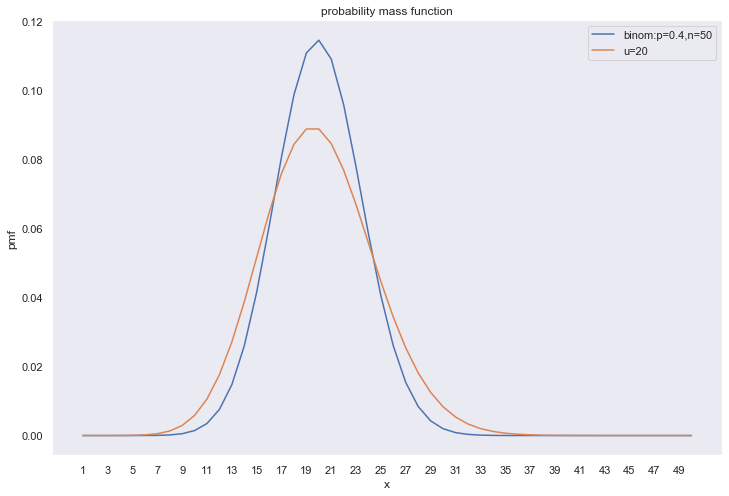
当n很大, p很小的时候,如n>=100或者np<=10的时候, 二项分布可以近似泊松。

