数据地址:https://tianchi.aliyun.com/competition/entrance/531830/information
1.导入模块和数据
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import datetime import warnings warnings.filterwarnings('ignore') data_train = pd.read_csv('F:/python/阿里云金融风控-贷款违约预测/train.csv') data_test_a = pd.read_csv('F:/python/阿里云金融风控-贷款违约预测/testA.csv')
2.数据基本认知
data_train.shape,data_test_a.shape
((800000, 47), (200000, 48))
查看y值的分布
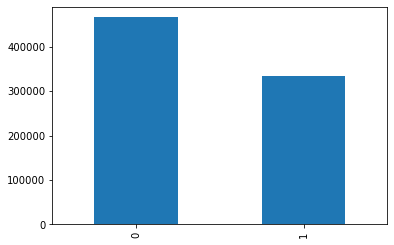
data_train['isDefault'].value_counts().plot.bar() plt.show() data_train['isDefault'].value_counts()/len(data_train)# 0 0.800488 ,1 0.199513 plt.pie([0.800488,0.199513],labels=[0,1],autopct='%1.2f%%')
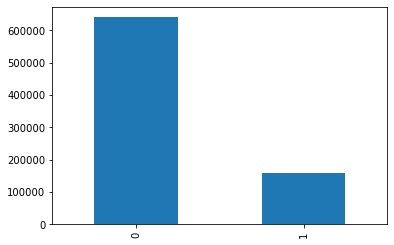
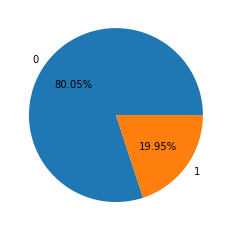
可以看出y值分布还是比较符合现实的情况
3.区分数值型和类别性特征
numerical_fea = list(data_train.select_dtypes(exclude=['object']).columns) category_fea = list(filter(lambda x: x not in numerical_fea,list(data_train.columns)))
结合一下字段含义,看看二者所属类型是否是符合真实情况
1 Field Description 2 id 为贷款清单分配的唯一信用证标识 3 loanAmnt 贷款金额 4 term 贷款期限(year) 5 interestRate 贷款利率 6 installment 分期付款金额 7 grade 贷款等级 8 subGrade 贷款等级之子级 9 employmentTitle 就业职称 10 employmentLength 就业年限(年) 11 homeOwnership 借款人在登记时提供的房屋所有权状况 12 annualIncome 年收入 13 verificationStatus 验证状态 14 issueDate 贷款发放的月份 15 purpose 借款人在贷款申请时的贷款用途类别 16 postCode 借款人在贷款申请中提供的邮政编码的前3位数字 17 regionCode 地区编码 18 dti 债务收入比 19 delinquency_2years 借款人过去2年信用档案中逾期30天以上的违约事件数 20 ficoRangeLow 借款人在贷款发放时的fico所属的下限范围 21 ficoRangeHigh 借款人在贷款发放时的fico所属的上限范围 22 openAcc 借款人信用档案中未结信用额度的数量 23 pubRec 贬损公共记录的数量 24 pubRecBankruptcies 公开记录清除的数量 25 revolBal 信贷周转余额合计 26 revolUtil 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额 27 totalAcc 借款人信用档案中当前的信用额度总数 28 initialListStatus 贷款的初始列表状态 29 applicationType 表明贷款是个人申请还是与两个共同借款人的联合申请 30 earliesCreditLine 借款人最早报告的信用额度开立的月份 31 title 借款人提供的贷款名称 32 policyCode 公开可用的策略_代码=1新产品不公开可用的策略_代码=2 33 n系列匿名特征 匿名特征n0-n14,为一些贷款人行为计数特征的处理
特征变量的值的个数
1 id :800000 缺失值个数: 0 2 loanAmnt :1540 缺失值个数: 0 3 term :2 缺失值个数: 0 4 interestRate :641 缺失值个数: 0 5 installment :72360 缺失值个数: 0 6 grade :7 缺失值个数: 0 7 subGrade :35 缺失值个数: 0 #删除,相关性太高,如果是评分卡可以使用这个变量 8 employmentTitle :248683 缺失值个数: 1 9 employmentLength :11 缺失值个数: 46799 有缺失值 10 homeOwnership :6 缺失值个数: 0 11 annualIncome :44926 缺失值个数: 0 12 verificationStatus :3 缺失值个数: 0 13 issueDate :139 缺失值个数: 0 14 isDefault :2 缺失值个数: 0 15 purpose :14 缺失值个数: 0 16 postCode :932 缺失值个数: 1 17 regionCode :51 缺失值个数: 0 18 dti :6321 缺失值个数: 239 19 delinquency_2years :30 缺失值个数: 0 20 ficoRangeLow :39 缺失值个数: 0 21 ficoRangeHigh :39 缺失值个数: 0 22 openAcc :75 缺失值个数: 0 23 pubRec :32 缺失值个数: 0 24 pubRecBankruptcies :11 缺失值个数: 405 25 revolBal :71116 缺失值个数: 0 26 revolUtil :1286 缺失值个数: 531 27 totalAcc :134 缺失值个数: 0 28 initialListStatus :2 缺失值个数: 0 29 applicationType :2 缺失值个数: 0 30 earliesCreditLine :720 缺失值个数: 0 31 title :39644 缺失值个数: 1 32 policyCode :1 缺失值个数: 0 33 n0 :39 缺失值个数: 40270 34 n1 :33 缺失值个数: 40270 35 n2 :50 缺失值个数: 40270 36 n2.1 :50 缺失值个数: 40270 37 n4 :46 缺失值个数: 33239 38 n5 :65 缺失值个数: 40270 39 n6 :107 缺失值个数: 40270 40 n7 :70 缺失值个数: 40270 41 n8 :102 缺失值个数: 40271 42 n9 :44 缺失值个数: 40270 43 n10 :76 缺失值个数: 33239 44 n11 :5 缺失值个数: 69752 45 n12 :5 缺失值个数: 40270 46 n13 :28 缺失值个数: 40270 47 n14 :31 缺失值个数: 40270
1.贷款金额(loanAmnt)
# 解决Seaborn中文显示问题并调整字体大小 sns.set(font='SimHei') data_train['loanAmnt'].value_counts() #data_train['loanAmnt'].value_counts().plot.hist() plt.figure(figsize=(16,12)) plt.subplot(221) sub_plot_1=sns.distplot(data_train['loanAmnt']) sub_plot_1.set_title("训练集", fontsize=18) plt.subplot(222) sub_plot_2=sns.distplot(data_test_a['loanAmnt']) sub_plot_2.set_title("测试集", fontsize=18)
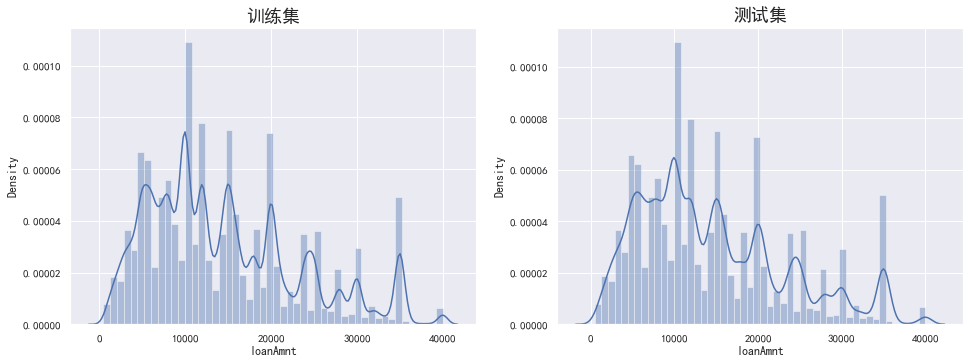

(40000.0, 500.0, count 800000.000000 mean 14416.818875 std 8716.086178 min 500.000000 25% 8000.000000 50% 12000.000000 75% 20000.000000 max 40000.000000
最大值是4万最小值是500,没有异常值,但是也不符合正太分布
2.term 借款期限
plt.figure(figsize=(16,12)) plt.subplot(221) sub_plot_1=data_train['term'].value_counts().plot.bar() sub_plot_1.set_title("训练集", fontsize=18) plt.subplot(222) sub_plot_2=data_test_a['term'].value_counts().plot.bar() sub_plot_2.set_title("测试集", fontsize=18) plt.show() plt.figure(figsize=(16,12)) plt.subplot(221) a=data_train['term'].value_counts()/len(data_train)# 0 0.800488 ,1 0.199513 plt.pie(a.values,labels=a.index,autopct='%1.2f%%') plt.title('训练集') plt.subplot(222) b=data_test_a['term'].value_counts()/len(data_test_a)# 0 0.800488 ,1 0.199513 plt.pie(b.values,labels=b.index,autopct='%1.2f%%') plt.title('测试集') plt.show() a=pd.crosstab(data_train['term'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()
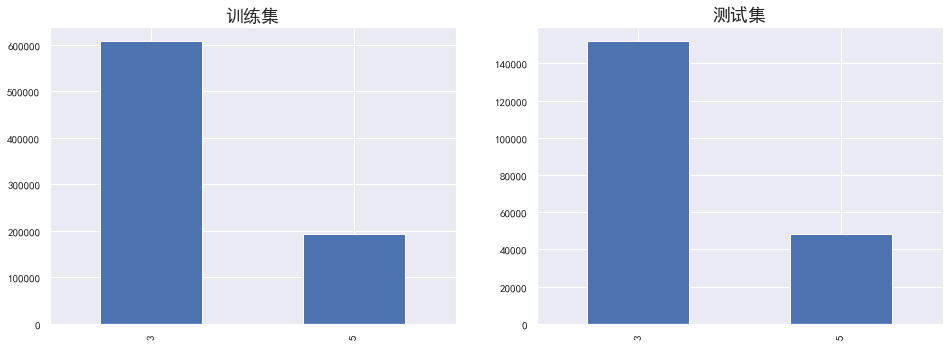
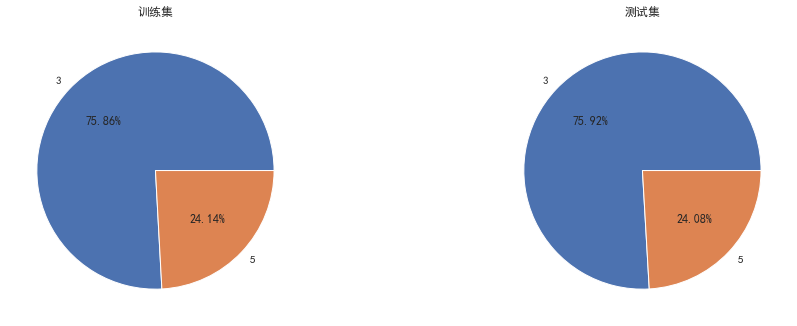
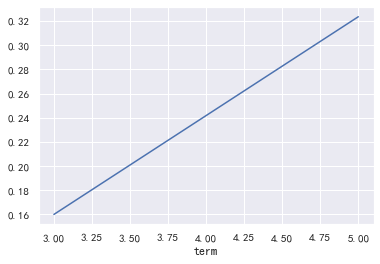
由此可见训练集和测试集分布基本是一致的,且贷款期限对逾期有着明显的区别
3.贷款利率 interestRate 看着是连续型数据
data_train['interestRate'].value_counts().plot.hist() plt.show() sns.distplot(data_train['interestRate']) plt.show() sns.distplot(np.log(data_train['interestRate']))
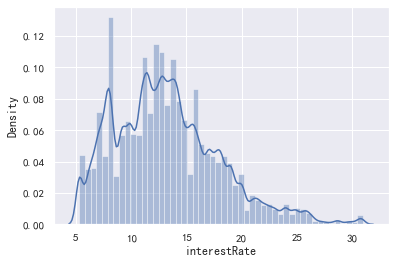
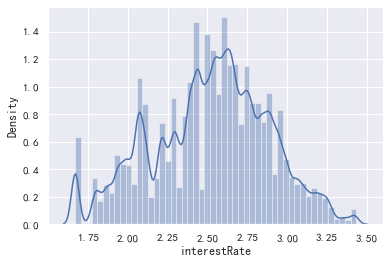
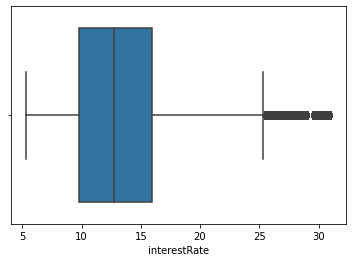
(30.99, 5.31, count 800000.000000 mean 13.238391 std 4.765757 min 5.310000 25% 9.750000 50% 12.740000 75% 15.990000 max 30.990000 Name: interestRate, dtype: float64)
看着后面数据还是的自己处理,可以分箱看看数据的表现如何(后面再处理吧),没有异常值,这个特征还是很有用处的,但是可能会和等分字段的较强的相关性,毕竟等级越好,说明用户越优质,利率就会越低
4.installment 分期付款金额
data_train['installment'].value_counts().plot.hist() plt.show() sns.distplot(data_train['installment']) plt.show() sns.distplot(np.log(data_train['installment']))
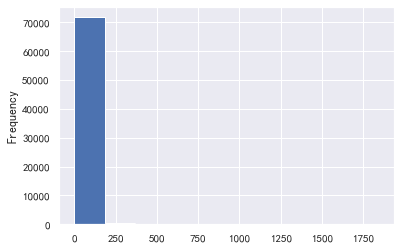
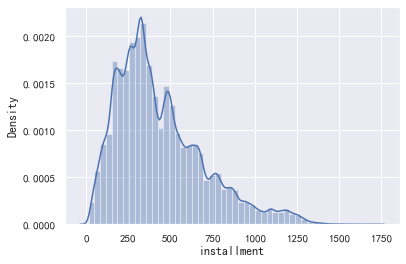
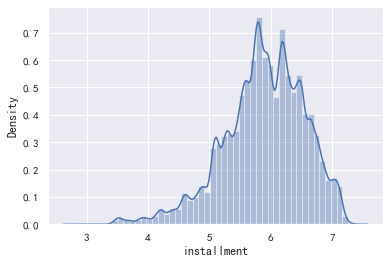
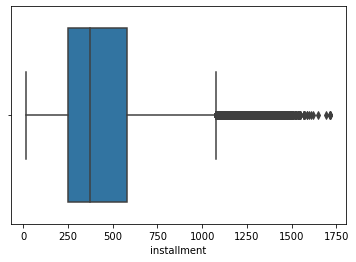
(1715.42, 15.69, count 800000.000000 mean 437.947723 std 261.460393 min 15.690000 25% 248.450000 50% 375.135000 75% 580.710000 max 1715.420000 Name: installment, dtype: float64)
这个每期还款金额和贷款金额,以及期限有关,没有异常值
5.'grade','subGrade' 用户等级之类的
plt.figure(figsize=(16,12)) plt.subplot(221) sub_plot_1=data_train['grade'].value_counts().sort_index().plot.bar() sub_plot_1.set_title("训练集", fontsize=18) plt.subplot(222) sub_plot_2=data_test_a['grade'].value_counts().sort_index().plot.bar() sub_plot_2.set_title("测试集", fontsize=18) plt.show() plt.figure(figsize=(16,12)) plt.subplot(221) a=data_train['grade'].value_counts()/len(data_train)# 0 0.800488 ,1 0.199513 plt.pie(a.values,labels=a.index,autopct='%1.2f%%') plt.title('训练集') plt.subplot(222) b=data_test_a['grade'].value_counts()/len(data_test_a)# 0 0.800488 ,1 0.199513 plt.pie(b.values,labels=b.index,autopct='%1.2f%%') plt.title('测试集') plt.show() a=pd.crosstab(data_train['grade'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()
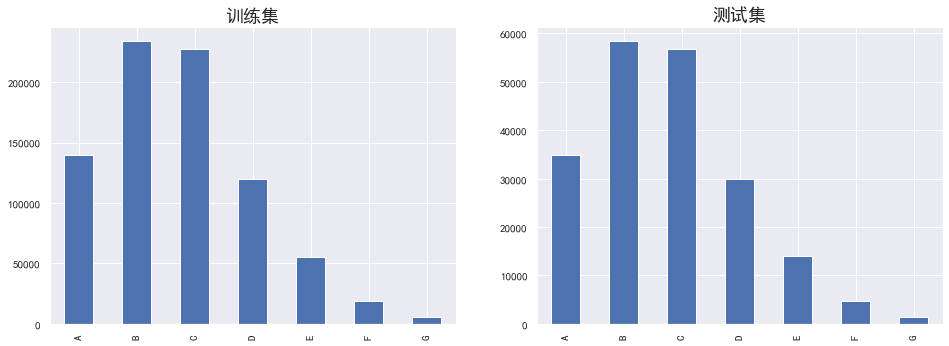
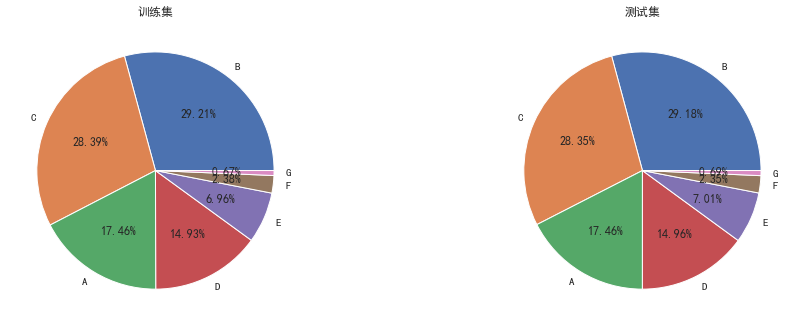
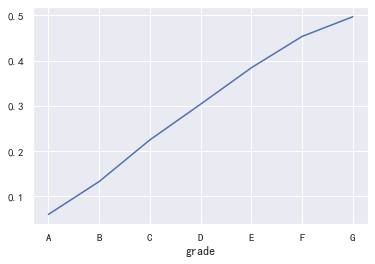
看的出来等级分布基本符合正态分布,且这个特征的逾期率是单调增的
plt.figure(figsize=(16,12)) plt.subplot(221) sub_plot_1=data_train['subGrade'].value_counts().sort_index().plot.bar() sub_plot_1.set_title("训练集", fontsize=18) plt.subplot(222) sub_plot_2=data_test_a['subGrade'].value_counts().sort_index().plot.bar() sub_plot_2.set_title("测试集", fontsize=18) plt.show() plt.figure(figsize=(16,12)) plt.subplot(221) a=data_train['subGrade'].value_counts()/len(data_train)# 0 0.800488 ,1 0.199513 plt.pie(a.values,labels=a.index,autopct='%1.2f%%') plt.title('训练集') plt.subplot(222) b=data_test_a['subGrade'].value_counts()/len(data_test_a)# 0 0.800488 ,1 0.199513 plt.pie(b.values,labels=b.index,autopct='%1.2f%%') plt.title('测试集') plt.show() a=pd.crosstab(data_train['subGrade'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show() #还需要看一下这二者之间的相关性如何,由于二者都不是数值型特征,故暂时不可以计算相关性 data_train['subGrade'].corr(data_train['grade'])

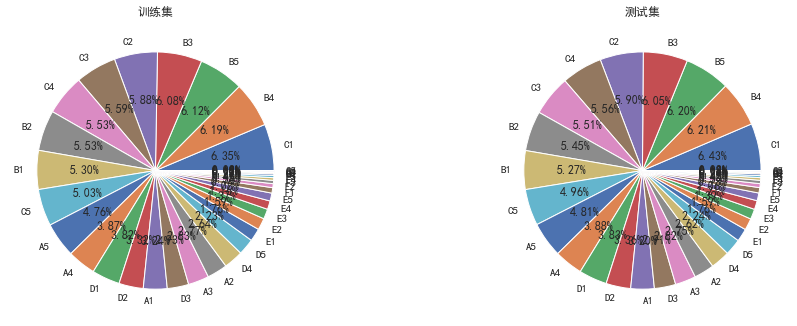
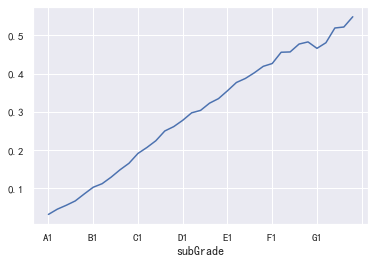
觉得可以删除小等级的那个特征
6.就业职称和就业年限 employmentTitle(就一堆数字,已经加密过的),employmentLength,现在只是在简单理解每个特征的分布,还没有到特征构造的时候(后面再进行)
#data_train['employmentTitle'].value_counts().plot.hist() sns.distplot(data_train['employmentTitle']) data_train['employmentTitle'].value_counts().sort_values(
这个数据是连续型,暂时留着吧
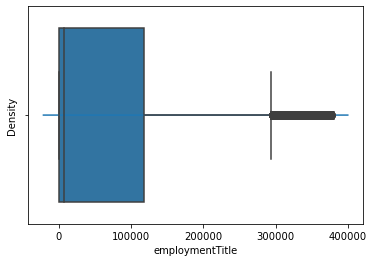
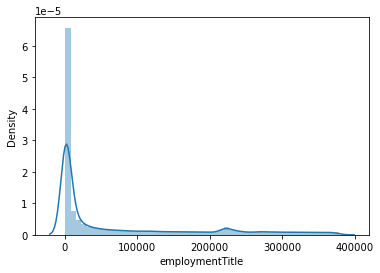
(378351.0, -1.0, count 800000.000000 mean 72005.261706 std 106585.603991 min -1.000000 25% 427.000000 50% 7755.000000 75% 117663.250000 max 378351.000000 Name: employmentTitle, dtype: float64)
def employmentLength_to_int(s): if pd.isnull(s): return s else: return np.int8(s.split()[0]) for data in [data_train, data_test_a]: data['employmentLength'].replace(to_replace='10+ years', value='10 years', inplace=True) data['employmentLength'].replace('< 1 year', '0 years', inplace=True) data['employmentLength'] = data['employmentLength'].apply(employmentLength_to_int) data_train['employmentLength'].value_counts().sort_index().plot.bar() plt.show() a=pd.crosstab(data_train['employmentLength'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()
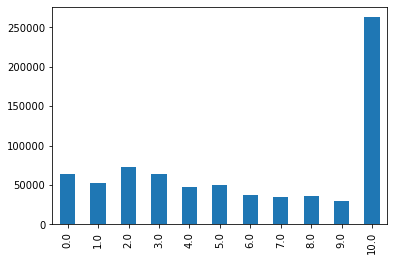
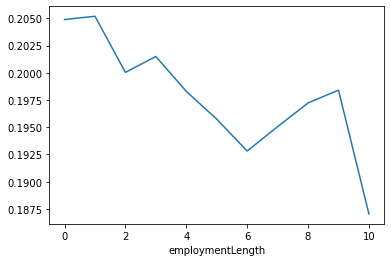
这个字段已经处理过了,后面主要注意一下,上面图中,缺失值并没有显示出来,需要注意一下
7.homeOwnership,借款人在登记时提供的房屋所有权状况,verificationStatus:验证状态,purpose:借款人在贷款申请时的贷款用途类别,
data_train['homeOwnership'].value_counts().plot.bar() plt.show() a=pd.crosstab(data_train['homeOwnership'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()
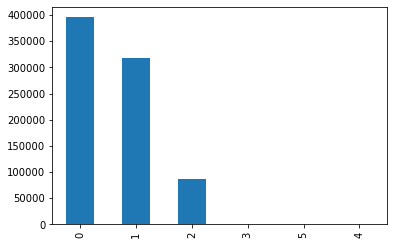
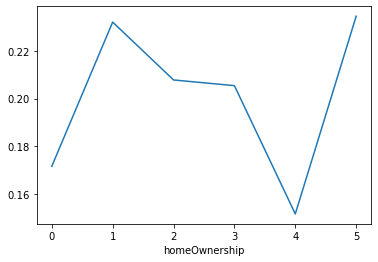
修改之后就好多了
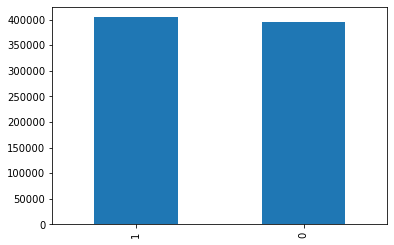
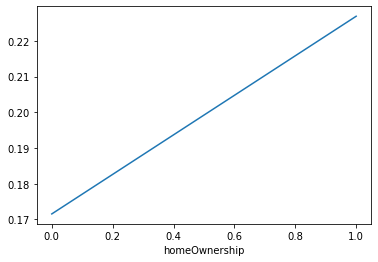
这个分布奇奇怪怪的,应该是0是有房子,1是没有房子,其他的值可以并到一起
data_train['verificationStatus'].value_counts().sort_index().plot.bar() plt.show() a=pd.crosstab(data_train['verificationStatus'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()
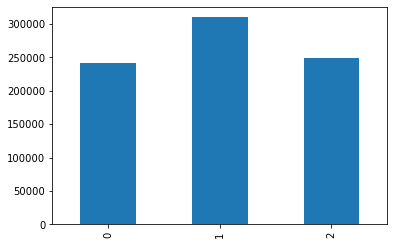
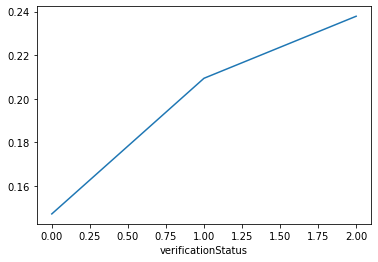
这个特征看着就舒服多了
data_train['purpose'].value_counts() data_train['purpose'].value_counts().sort_index().plot.bar() plt.show() a=pd.crosstab(data_train['purpose'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()
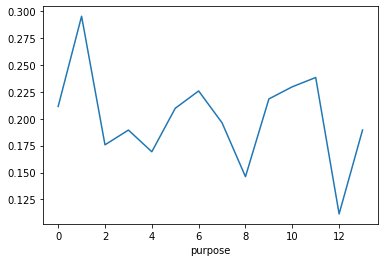
乱七八糟的
贷款时初始状态initialListStatus
data_train['initialListStatus'].value_counts().sort_index().plot.bar() plt.show() a=pd.crosstab(data_train['initialListStatus'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()

annualIncome:年收入
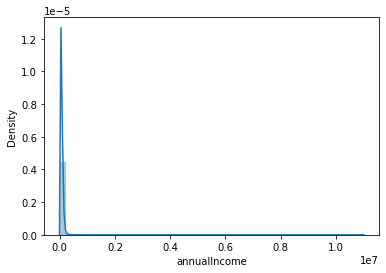

这个值异常值就很多,看看得要怎么处理
dti:债务收入比,异常值很多,我觉得这个应该是<=100是合理的(323个值异常)

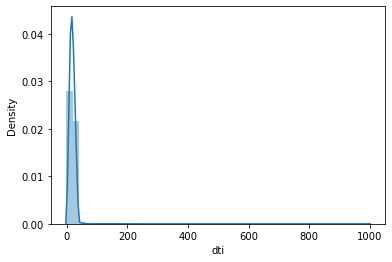
(999.0, -1.0, count 800000.000000 mean 18.278796 std 11.153469 min -1.000000 25% 11.790000 50% 17.610000 75% 24.060000 max 999.000000 Name: dti, dtype: float64)
delinquency_2years:借款人过去2年信用档案中逾期30天以上的违约事件数
离群值特别多,可以划分为0,1-3,4-7,8+
(39.0, 0.0, count 800000.000000 mean 0.318239 std 0.880325 min 0.000000 25% 0.000000 50% 0.000000 75% 0.000000 max 39.000000 Name: delinquency_2years, dtype: float64)
借款人在贷款发放时的fico所属的下限范围 和借款人在贷款发放时的fico所属的上限范围
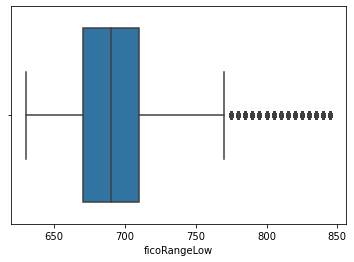
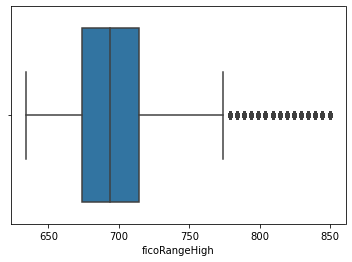
openAcc:借款人信用档案中未结信用额度的数量
离群点多
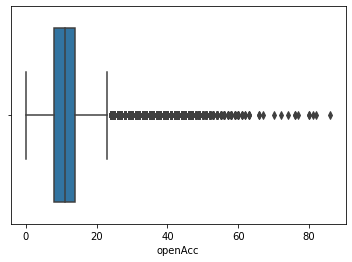
(86.0, 0.0, count 800000.000000 mean 11.598020 std 5.475286 min 0.000000 25% 8.000000 50% 11.000000 75% 14.000000 max 86.000000 Name: openAcc, dtype: float64)


applicationType:表明贷款是个人申请还是与两个共同借款人的联合申请,这个字段严重倾斜
data_train['applicationType'].value_counts().sort_index().plot.bar() plt.show() a=pd.crosstab(data_train['applicationType'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()

policyCode:公开可用的策略_代码=1新产品不公开可用的策略_代码=2,都是一个值,可以删除了
data_train['policyCode'].value_counts().sort_index().plot.bar() plt.show() a=pd.crosstab(data_train['policyCode'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()


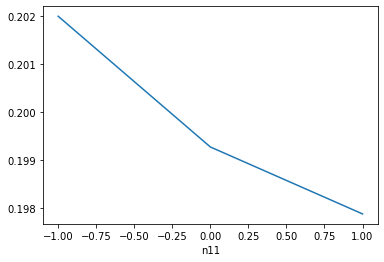
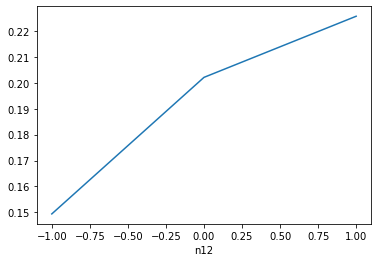
n11,和n12 ,数据严重倾斜,我做了一定处理,才能弄成这样
data=data_train data['n11'].replace(2, value=1, inplace=True) data['n11'].replace(3, value=1, inplace=True) data['n11'].replace(4, value=1, inplace=True) data['n11'] = data['n11'].fillna(-1) data['n11'].value_counts().sort_index().plot.bar() plt.show() a=pd.crosstab(data['n11'],data['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show() data['n12'].replace(2, value=1, inplace=True) data['n12'].replace(3, value=1, inplace=True) data['n12'].replace(4, value=1, inplace=True) data['n12'] = data['n12'].fillna(-1) data['n12'].value_counts().sort_index().plot.bar() plt.show() a=pd.crosstab(data['n12'],data['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()
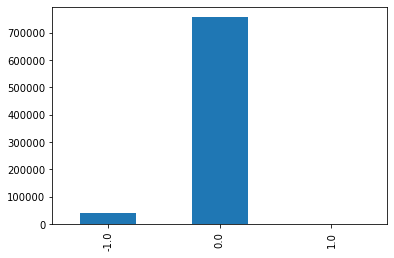
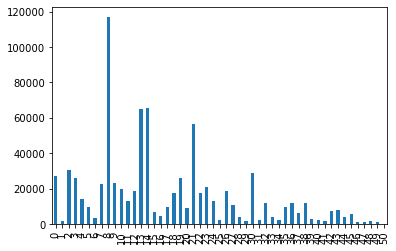
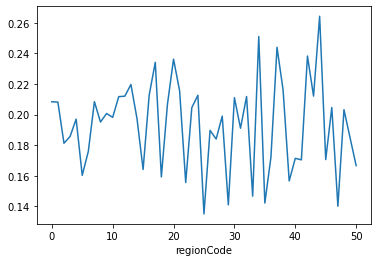
8.postCode:借款人在贷款申请中提供的邮政编码的前3位数字,regionCode:地区编码
data_train[['postCode', 'regionCode']].head() #postCode没有什么信息,加密过的,数值特别多,后面再看看吧 #主要看看地区编码 data_train['regionCode'].value_counts() data_train['regionCode'].value_counts().sort_index().plot.bar() plt.show() a=pd.crosstab(data_train['regionCode'],data_train['isDefault']) a['坏用户占比']=a[1]/(a[0]+a[1]) a['坏用户占比'].plot() plt.show()
划分数值型特征和类别型
numerical_fea = list(data_train.select_dtypes(exclude=['object']).columns) category_fea = list(filter(lambda x: x not in numerical_fea,list(data_train.columns)))
数值特征中也有离散特征
#过滤数值型类别特征 def get_numerical_serial_fea(data,feas): ''' 目的:划分数值型变量中的连续变量和分类变量 data:需要划分的数据集 feas:需要区分的特征的名称 返回:连续变量和分类变量 的list集合 ''' numerical_serial_fea = [] numerical_noserial_fea = [] for fea in feas: temp = data[fea].nunique() if temp <= 10: numerical_noserial_fea.append(fea) continue numerical_serial_fea.append(fea) return numerical_serial_fea,numerical_noserial_fea numerical_serial_fea,numerical_noserial_fea = get_numerical_serial_fea(data_train,numerical_fea)
将全部的类别特征转化,有一定层次的用标签化,其余的用独热编码['grade', 'subGrade', 'issueDate', 'earliesCreditLine']
data_train[['grade', 'subGrade', 'issueDate', 'earliesCreditLine']].isnull().sum() for data in [data_train, data_test_a]: data['grade'] = data['grade'].map({'A':1,'B':2,'C':3,'D':4,'E':5,'F':6,'G':7}) #label-encode:subGrade,postCode,title # 高维类别特征需要进行转换 from tqdm import tqdm from sklearn.preprocessing import LabelEncoder for col in tqdm(['subGrade']): le = LabelEncoder() le.fit(list(data_train[col].astype(str).values) + list(data_test_a[col].astype(str).values)) data_train[col] = le.transform(list(data_train[col].astype(str).values)) data_test_a[col] = le.transform(list(data_test_a[col].astype(str).values)) print('Label Encoding 完成')
看一下这二者之间的相关性,删除其中一个
data_train['subGrade'].corr(data_train['grade']) #0.9756093687672992 可以考虑删除一样 data_train=data_train.drop(['subGrade'],axis=1) data_test_a=data_test_a.drop(['subGrade'],axis=1)
贷款发放日期'issueDate',借款人最早报告的信用额度开立的月份:earliesCreditLine,看了一下,这个这两个字段是有时间的,
#构造字段 #转化成时间格式 data_train['issueDate'] = pd.to_datetime(data_train['issueDate'],format='%Y-%m-%d') startdate = datetime.datetime.strptime('2007-06-01', '%Y-%m-%d') data_train['issueDateDT'] = data_train['issueDate'].apply(lambda x: x-startdate).dt.days #转化成时间格式 data_test_a['issueDate'] = pd.to_datetime(data_train['issueDate'],format='%Y-%m-%d') startdate = datetime.datetime.strptime('2007-06-01', '%Y-%m-%d') data_test_a['issueDateDT'] = data_test_a['issueDate'].apply(lambda x: x-startdate).dt.days
年份数,月份数
for data in [data_train,data_test_a]: data['year']=data['earliesCreditLine'].apply(lambda x:x[4:]) data['month']=data['earliesCreditLine'].apply(lambda x:x[:3]) data['month']=data['month'].map({'Apr':4, 'Aug':8, 'Dec':12, 'Feb':2, 'Jan':1, 'Jul':7, 'Jun':6, 'Mar':3, 'May':5, 'Nov':11, 'Oct':10, 'Sep':9}) data['year_1']=data['issueDate'].dt.year data['month_1']=data['issueDate'].dt.month data['earliesCreditLine_month']=(data['year_1']-data['year'].astype(int))*12+(data['month_1']-data['month'].astype(int)) data['earliesCreditLine_year']=data['year_1']-data['year'].astype(int) #data=data.drop(['year','month','year_1','month_1'],axis=1)
离散型数值变量
['term', 'homeOwnership', 分为0和1 吧 'verificationStatus', 'isDefault', 这个是label 'initialListStatus', 'applicationType', 虽然严重倾斜,但是区分度很好,不知道要不要留着 'policyCode', 只有一个值,可以删除 'n11', 也是严重倾斜,可以把>=1合并,空值为-1 'n12'] 同上
for data in [data_train,data_test_a]: data['n11'].replace(2, value=1, inplace=True) data['n11'].replace(3, value=1, inplace=True) data['n11'].replace(4, value=1, inplace=True) data['n11'] = data['n11'].fillna(-1) for data in [data_train,data_test_a]: data['n12'].replace(2, value=1, inplace=True) data['n12'].replace(3, value=1, inplace=True) data['n12'].replace(4, value=1, inplace=True) data['n12'] = data['n12'].fillna(-1) for data in [data_train,data_test_a]: data['homeOwnership'].replace(2, value=1, inplace=True) data['homeOwnership'].replace(3, value=1, inplace=True) data['homeOwnership'].replace(4, value=1, inplace=True) data['homeOwnership'].replace(5, value=1, inplace=True)
删除了变量,然后做独热编码
data_train=data_train.drop(['policyCode'],axis=1) data_test_a=data_test_a.drop(['policyCode'],axis=1) print(data_train.shape,data_test_a.shape) #(800000, 54) (200000, 55)
独热编码
data_train=pd.get_dummies(data_train, columns=['term', 'homeOwnership', 'verificationStatus','initialListStatus','applicationType', 'n11', 'n12'], drop_first=True) data_test_a=pd.get_dummies(data_test_a, columns=['term', 'homeOwnership', 'verificationStatus','initialListStatus','applicationType', 'n11', 'n12'], drop_first=True)