本文目录
1.数据预处理
2.特征构建
3.特征选择
4.LightGBM模型构建
5.自动调参方法
一.数据预处理
1.1 离群点处理
Tukey Method:
一种利用数据四分位差的检测方法。通过计算特征的 IQR 四分位差,得到 outlier_step=1.5*IQR,如果值大于(上四分位数+outlier_step)或者小于(下四分位数-outlier_step),就判定这个值为离群点。为减小盲目删除样本后带来的信息损失,设定阈值 n,如果一个样本中出现离群点个数大于 n,我们就可以删除这个样本。
from collections import Counter def detect_outliers(df,n,features): outlier_indices=[] #迭代每一个特征 for col in features: #计算四分位数 Q1=np.percentile(df[col],25) Q3=np.percentile(df[col],75) #计算IQR Interquartile range 四分位差 IQR=Q3-Q1 #Outlier Step outlier_step=1.5*IQR #判断每个特征内的离群点 outlier_index=df[(df[col] > Q3+outlier_step) | (df[col] < Q1-outlier_step)].index outlier_indices.extend(outlier_index) #只有当n个以上的特征出现离群现象时,这个样本点才被判断为离群点 outlier_dict=Counter(outlier_indices) #统计样本点被判断为离群的次数,并返回一个字典 outlier_indices=[k for k,v in outlier_dict.items() if v > n] return outlier_indices outlier_index=detect_outliers(train,2,['Age','SibSp','Parch','Fare']) #删除离群点 train=train.drop(outlier_index,axis=0).reset_index(drop=True)
其他方法:
- EDA:箱型图定性分析,pandas的describe函数定量分析
- 分箱操作(连续特征离散化)
- 近似服从正态分布的特征可以用3sigma原则
- 平均值或中位数替代异常点,简单高效,信息的损失较少
- 优先使用树模型,因为在训练树模型时,树模型对离群点的鲁棒性较高,无信息损失,不影响模型训练效果
1.2 缺失值处理
(1)统计量填充:直接填充出现众数,均值,最值等
对于连续变量
若缺失率较低(小于95%)且重要性较低,则根据数据分布的情况进行填充。
- 对于数据近似符合正态分布,用该变量的均值填补缺失。
- 对于数据存在偏态分布的情况,采用中位数进行填补。
#绘制与目标变量相关的特征分布图 def plotContinuousVar(df,col,TARGET): g=sns.kdeplot(df[col][df[TARGET]==0],color='red') g=sns.kdeplot(df[col][df[TARGET]==1],ax=g,color='green') g.set_xlabel(col) g.set_ylabel('Frequency') g=g.legend(['0','1']) plotContinuousVar(train,'Fare','Survived')
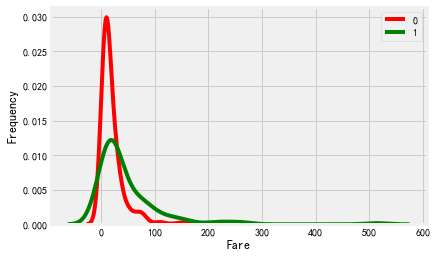
如何区别正态分布和偏态分布,正态分布是对称的,而偏态分布一般是不对称的左偏或者右偏
#通过数据可视化发现,Fare票价特征是偏态分布,故采用中位数填充 train['Fare']=train['Fare'].fillna(train['Fare'].median())
对于离散变量:
- 可以直接把缺失值作为一个属性,例如设置为None,后续用one-hot或者label-encodeing处理。
- 如果缺失少,可以用众数填充
#由于缺失值只有2个,所有选用出现次数最多的值填充 train_data['Embarked']=train_data['Embarked'].fillna('S')
(2)模型填充:将需要填充的缺失特征作为label,其他相关特征用作训练特征
from sklearn.ensemble import RandomForestRegressor #使用随机森林填补age缺失值 def set_missing_ages(df): #把已有的数值型特征取出来丢进随机森林中 num_df=df[['Age','Fare','Parch','SibSp','Pclass','Title']] #把乘客分成已知年龄和未知年龄两部分 know_age=num_df[num_df.Age.notnull()].as_matrix() unknow_age=num_df[num_df.Age.isnull()].as_matrix() #y即目标年龄 y=know_age[:,0] #X即特征属性值 X=know_age[:,1:] rfr=RandomForestRegressor(n_estimators=100,random_state=0,n_jobs=-1) rfr.fit(X,y) #用拟合好的模型来预测 y_pre=rfr.predict(unknow_age[:,1:]) #用得到的预测值来填补原缺失数据 df.loc[(df.Age.isnull()),'Age']=y_pre return df train=set_missing_ages(train)
(3)XGBoost(LightGBM)自动填充缺失值
1.3 one-hot编码:处理分类变量
def one_hot_encoder(df, nan_as_category=True): original_columns = list(df.columns) categorical_columns = [col for col in df.columns if df[col].dtype == 'object'] df = pd.get_dummies(df, columns=categorical_columns, dummy_na=nan_as_category) new_columns = [c for c in df.columns if c not in original_columns] return df, new_columns
1.4 log和box-cox转换
log对数转换主要针对线性模型,让偏态分布的特征转换为近似正态分布,满足模型假设条件。
#注明偏斜度 g=sns.distplot(train['Fare'],color='m',label='skewness:%.2f'%(train['Fare'].skew())) g=g.legend(loc='best')
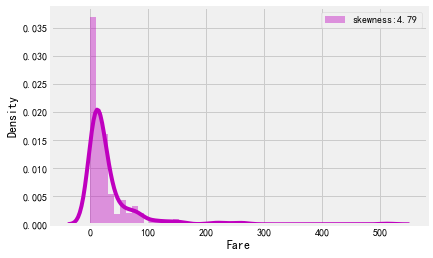
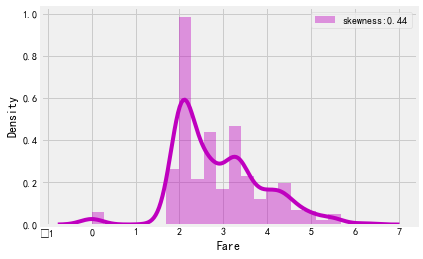
#用log函数来处理Fare分布函数skewed的情况 train['Fare']=train['Fare'].map(lambda i:np.log(i) if i>0 else 0) g=sns.distplot(train['Fare'],color='m',label='skewness:%.2f'%(train['Fare'].skew())) g=g.legend(loc='best')
Box-Cox 转换:Box 和 Cox 下(1964)提出了一种用一个参数λ进行索引的变换族:
相比 log 转换,这个变换族还包括平方变换,平方根变换,倒数变换已经在此之间的变换。就使用案例来说,Box-Cox 变换更加直接,更少遇到计算问题,而且对于预测变量同样有效。
from scipy.special import boxcox1p lam=0.15 dataset[feat]=boxcox1p(dataset[feat],lam)
二.特征构造
特征构建主要依据业务理解,新构建的特征可以加强对label的预测能力。举个例子,现在有个简单的二分类问题,要求使用逻辑回归训练一个身材分类器。输入数据 X 有身高和体重,标签 Y 则是胖或者不胖。根据经验,我们不能仅仅依靠体重来判断一个人是否胖。对于这个任务,一个非常经典的特征构造是,构造 BMI 指数,BMI=体重/身高的平方。通过 BMI 指数,就能更好地帮助我们刻画一个人的身材信息。这里仅仅总结了一些通用构建思路,具体业务需要具体对待。
2.1 多项式特征(Polynomial Features)
示例:对于特征x,y,其衍生的二阶多项式特征包括,x^2,y^2,xy
通过特征的乘积,引入特征与特征之间的交互作用,从而引入非线性
下面代码以Kaggle Home Credit Default Risk数据集为例,实现具有通用性
#将用来交叉的特征 定义为新的dataframe poly_features=dataset[['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']] from sklearn.preprocessing import PolynomialFeatures poly_transformer=PolynomialFeatures(degree=3) poly_transformer.fit(poly_features) poly_features=poly_transformer.transform(poly_features) print(poly_features.shape) #(355912, 20) #查看衍生的多项式特征 print('Polynomial feature names: {}'.format(poly_transformer.get_feature_names( ['EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3']))) #Polynomial feature names: #['1', 'EXT_SOURCE_1', 'EXT_SOURCE_2', 'EXT_SOURCE_3', 'EXT_SOURCE_1^2', 'EXT_SOURCE_1 EXT_SOURCE_2',
'EXT_SOURCE_1 EXT_SOURCE_3', 'EXT_SOURCE_2^2', 'EXT_SOURCE_2 EXT_SOURCE_3', 'EXT_SOURCE_3^2', 'EXT_SOURCE_1^3',
'EXT_SOURCE_1^2 EXT_SOURCE_2', 'EXT_SOURCE_1^2 EXT_SOURCE_3', 'EXT_SOURCE_1 EXT_SOURCE_2^2', 'EXT_SOURCE_1 EXT_SOURCE_2 EXT_SOURCE_3',
'EXT_SOURCE_1 EXT_SOURCE_3^2', 'EXT_SOURCE_2^3', 'EXT_SOURCE_2^2 EXT_SOURCE_3', 'EXT_SOURCE_2 EXT_SOURCE_3^2', 'EXT_SOURCE_3^3']
2.2 统计特征
这里用Kaggle Home Credit Default Risk贷款违约预测比赛的数据集作为例子
申请贷款的客户信息表applicationtrain.csv,原始特征122,本文为了便于展示,只选取其中9个特征。同时,比赛还有其余四个辅助表,这里只取其中的信用卡数据表。其中SK_ID_CURR是在applicationtrain.表唯一的,但在credit_card_balance表是不唯一的,所以需要进行聚合。
表一:客户信息表application_train SK_ID_CURR 客户ID TARGET 标签 0/1 NAME_CONTRACT_TYPE 贷款类型(周转或现金) CODE_GENDER 性别 FLAG_OWN_CAR 是否有车 FLAG_OWN_REALTY 是否有房 CNT_CHILDREN 孩子数量 AMT_INCOME_TOTAL 年收入 AMT_CREDIT 贷款金额 表二:信用卡数据表credit_card_balance SK_ID_CURR 客户ID MONTHS_BALANCE 相对于申请日期而言的余额月份(-1是指最新的余额日期) AMT_BALANCE 上一次贷款月余额 ...
针对不同特征进行不同的统计聚合操作
time_agg={ 'CC_PAID_LATE': ['mean', 'sum'], 'CC_PAID_LATE_WITH_TOLERANCE':['mean', 'sum'], 'AMT_CREDIT_LIMIT_ACTUAL':['mean', 'var','median'], 'AMT_LAST_DEBT':['mean','var'], 'DRAWINGS_ATM_RATIO':['mean','var','max','min','median'], 'DRAWINGS_POS_RATIO':['mean','var','max','min','median'], 'RECEIVABLE_PAYMENT_RATIO':['mean','var','max','min','median'], 'AMT_PAYMENT_TOTAL_CURRENT':['mean','var','median'], 'AMT_INST_MIN_REGULARITY':['mean','median'], 'CNT_INSTALMENT_MATURE_CUM':['max'], 'AMT_DRAWINGS_POS_CURRENT':['mean'] } cc_agg = cc.groupby('SK_ID_CURR').agg(time_agg) #重命名 cc_agg.columns = pd.Index(['CC_' + e[0] + '_' + e[1].upper() +'_'+'75' for e in cc_agg.columns.tolist()])
2.3 时间特征:将秒转化为分钟和小时
#时间特征处理 timedelta = pd.to_timedelta(df['Time'], unit='s') df['Minute'] = (timedelta.dt.components.minutes).astype(int) df['Hour'] = (timedelta.dt.components.hours).astype(int)
2.4 频率特征:针对特征值数较多的离散特征,反应特征值频数分布
def frequence_encoding(df, feature): #计算 特征值频数 / 总样本数 freq_dict = dict(df[feature].value_counts() / df.shape[0]) new_feature = feature + '_freq' df[new_feature] = df[feature].map(freq_dict) return df
三.特征选择
特征选择的方法有方差选择,皮尔逊相关系数,互信息,正则化等。由于树模型的广泛使用,基于树模型的特征重要性排序是一种高效常用的方法。然而模型得到的特征重要性存在一定的偏差,这些往往对特征选择产生干扰。这里介绍Kaggle中有人用过的一种特征选择方法-PIMP算法(Permutation Importance),它的主要思想是修正已有的特征重要性。具体算法描述如下:
1.打乱标签的排序,得到新的训练集,重新训练并评估特征重要性。
2.重复第一步n次,得到每个特征进行多次评估的特征重要性集合,我们称之为thenull importance.
3.计算标签真实排序时,模型训练得到的特征重要性。
4.利用第二步得到的集合,对每个特征计算修正得分。
5.修正规则如下:Corrected_gain_score=100*
(null_importance_gain<np.percentile(actual_imp,25)).sum()/null_importance.size()
def get_feature_importance(data,shuffle,seed=None): #获取有用的特征 删除target和一些id trian_features=[f for f in data if f not in ['TARGET','SK_ID_CURR']] #shuffle y=data['TARGET'].copy() if shuffle: y=data['TARGET'].copy().sample(frac=1.0) #随机抽样 dtrain=lgb.Dataset(data[train_features],y,free_raw_data=False,silent=True) lgb_params={ 'objective':'binary', 'boosting_type':'rf', 'subsample':0.623, 'colsample_bytree':0.7, 'num_leaves':127, 'max_depth':8, 'seed':seed, 'bagging_freq':1, 'n_jobs':4 } clf=lgb.train(params=lgb_params,train_set=dtrain,num_boost_round=200,categorical_feature=categorical_feats) imp_df=pd.DataFrame() imp_df['feature']=list(train_features) imp_df['importance_gain']=clf.feature_importance(importance_type='gain') imp_df['train_score']=roc_auc_score(y,clf.predict(data[train_features])) return imp_df #获取真实目标排序的feature_importance actual_imp_df=get_feature_importance(data=data,shuffle=False) #获取n次打乱target后的feature_importance null_imp_df=pd.DataFrame() nb_runs=30 #打乱运行的次数 for i in range(nb_runs): imp_df=get_feature_importance(data=data,shuffle=True) imp_df['run']=i+1 null_imp_df=pd.concat([null_imp_df,imp_df],axis=0) #计算修正后的feature_scores feature_scores=[] for feature in actual_imp_df['feature'].unique(): f_null_imps_gain=null_imp_df.loc[null_imp_df['feature']==feature,'importance_gain'].values f_act_imps_gain=actual_imp_df.loc[actual_imp_df['feature']==feature,'importance_gain'].values.mean() corrected_gain_score=np.log(1e-10+f_act_imps_gain/(1+np.percentile(f_null_imps_gain,75))) feature_scores.append((feature,corrected_gain_score)) #用不同的阈值来筛选特征 for threshold in [0,10,20,30,40,50,60,70,80,90,95,99]: gain_feats=[feature for feature,score in feature_scores if score>=threshold]
四.LightGBM模型构建
#以Kaggle Home Credit Default Risk数据集为例,代码实现具有通用性 def kfold_lightgbm(df, num_folds, stratified=False, debug=False): train_df = df[df['TARGET'].notnull()] test_df = df[df['TARGET'].isnull()] print("Starting LightGBM. Train shape: {}, test shape: {}".format(train_df.shape, test_df.shape)) del df gc.collect() if stratified: folds = StratifiedKFold(n_splits=num_folds, shuffle=True, random_state=1001) else: folds = KFold(n_splits=num_folds, shuffle=True, random_state=1001) oof_preds = np.zeros(train_df.shape[0]) sub_preds = np.zeros(test_df.shape[0]) feature_importance_df = pd.DataFrame() #删除label或者id型数据 feats = [f for f in train_df.columns if f not in ['TARGET', 'SK_ID_CURR', 'SK_ID_BUREAU', 'SK_ID_PREV', 'index']] #五折交叉验证 for n_fold, (train_idx, valid_idx) in enumerate(folds.split(train_df[feats], train_df['TARGET'])): dtrain = lgb.Dataset(data=train_df[feats].iloc[train_idx], label=train_df['TARGET'].iloc[train_idx], free_raw_data=False, silent=True) dvalid = lgb.Dataset(data=train_df[feats].iloc[valid_idx], label=train_df['TARGET'].iloc[valid_idx], free_raw_data=False, silent=True) # LightGBM parameters found by Bayesian optimization params = { 'objective': 'binary', 'boosting_type': 'gbdt', 'nthread': 4, 'learning_rate': 0.02, # 02, 'num_leaves': 20, 'colsample_bytree': 0.9497036, 'subsample': 0.8715623, 'subsample_freq': 1, 'max_depth': 8, 'reg_alpha': 0.041545473, 'reg_lambda': 0.0735294, 'min_split_gain': 0.0222415, 'min_child_weight': 60, # 39.3259775, 'seed': 0, 'verbose': -1, 'metric': 'auc', } clf = lgb.train( params=params, train_set=dtrain, num_boost_round=13000, valid_sets=[dtrain, dvalid], early_stopping_rounds=200, verbose_eval=False ) oof_preds[valid_idx] = clf.predict(dvalid.data) sub_preds += clf.predict(test_df[feats]) / folds.n_splits fold_importance_df = pd.DataFrame() fold_importance_df["feature"] = feats fold_importance_df["importance"] = clf.feature_importance(importance_type='gain') fold_importance_df["importance"] = clf.feature_importance(importance_type='gain') fold_importance_df["fold"] = n_fold + 1 feature_importance_df = pd.concat([feature_importance_df, fold_importance_df], axis=0) print('Fold %2d AUC : %.6f' % (n_fold + 1, roc_auc_score(dvalid.label, oof_preds[valid_idx]))) del clf, dtrain, dvalid gc.collect() print('Full AUC score %.6f' % roc_auc_score(train_df['TARGET'], oof_preds)) #输出测试集预测结果,同时绘制特征重要性图 if not debug: sub_df = test_df[['SK_ID_CURR']].copy() sub_df['TARGET'] = sub_preds sub_df[['SK_ID_CURR', 'TARGET']].to_csv(submission_file_name, index=False) display_importances(feature_importance_df) feature_importance_df= feature_importance_df.groupby('feature')['importance'].mean().reset_index().rename(index=str,columns={'importance':'importance_mean'}) feature_importance_df.to_csv('feature_importance.csv') print(feature_importance_df.sort_values('importance_mean',ascending=False)[500:]) return feature_importance_df #绘制特征重要性图函数 def display_importances(feature_importance_df_): cols = feature_importance_df_[["feature", "importance"]].groupby("feature").mean().sort_values(by="importance",ascending=False)[:40].index best_features = feature_importance_df_.loc[feature_importance_df_.feature.isin(cols)] plt.figure(figsize=(8, 10)) sns.barplot(x="importance", y="feature", data=best_features.sort_values(by="importance", ascending=False)) plt.title('LightGBM Features (avg over folds)') plt.tight_layout() plt.savefig('lgbm_importances01.png')
五.自动调参方法
5.1 网格搜索:穷举参数的所有组合,选择最优解
from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, learning_curve kfold = StratifiedKFold(n_splits=10) tree=DecisionTreeClassifier(random_state=0) tree_param_grid={ 'max_depth':[7,8,9,11,12,13,14], 'min_samples_leaf':[2,3,4,5,6,7,8,9], 'min_samples_split':[2,3,4,5,6,7,8,9] } tree_grid_search=GridSearchCV(tree,param_grid=tree_param_grid,cv=kfold,scoring='accuracy',n_jobs=-1) tree_grid_search.fit(X_train,y_train) print('Best parameters:{}'.format(tree_grid_search.best_params_)) #Best parameters:{'max_depth': 7, 'min_samples_leaf': 2, 'min_samples_split': 2} print('Best cv score:{}'.format(tree_grid_search.best_score_)) #Best cv score:0.8149829738933031 print('Accuracy training set:{}'.format(tree_grid_search.score(X_train,y_train))) #Accuracy training set:0.8683314415437003
5.2 贝叶斯优化
相比网格搜索会穷举所有可能结果,贝叶斯调参考虑了之前的参数信息,不断调整当前参数
#feats是df中用于训练的有效特征 def kfold_lightgbm(train_df,feats,params): oof_preds = np.zeros(train_df.shape[0]) for n_fold, (train_idx, valid_idx) in enumerate(folds.split(train_df[feats], train_df['Class'])): dtrain = lgb.Dataset(data=train_df[feats].iloc[train_idx], label=train_df['Class'].iloc[train_idx], free_raw_data=False, silent=True) dvalid = lgb.Dataset(data=train_df[feats].iloc[valid_idx], label=train_df['Class'].iloc[valid_idx], free_raw_data=False, silent=True) clf = lgb.train( params=params, train_set=dtrain, num_boost_round=1000, valid_sets=[dtrain, dvalid], early_stopping_rounds=20, feval=average_precision_score_vali, verbose_eval=False ) oof_preds[valid_idx] = clf.predict(dvalid.data) del clf, dtrain, dvalid gc.collect() return average_precision_score(train_df['Class'], oof_preds) #objective function def lgb_objective(params,n_folds=5): loss = -kfold_lightgbm(params) return {'loss':-loss,'params':params,'status':STATUS_OK} #定义搜索空间 space = { 'objective':'regression', 'boosting_type': 'gbdt', 'subsample':0.8, 'colsample_bytree':hp.uniform('colsample_bytree',0.8,0.9), 'max_depth':7, 'learning_rate':0.01, "lambda_l1":hp.uniform('lambda_l1',0.0,0.2), 'seed':0, } #定义优化算法 tpe_algorithm = tpe.suggest best = fmin(fn = lgb_objective,space = space,algo=tpe_algorithm,max_evals=50) print(best) result=space_eval(space, best) print(space_eval(space, best))