进程与线程的关系:
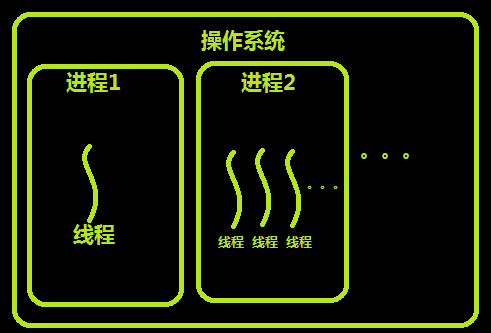
线程与进程的区别可以归纳为以下4点: 1)地址空间和其它资源(如打开文件):进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。 2)通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。 3)调度和切换:线程上下文切换比进程上下文切换要快得多。 4)在多线程操作系统中,进程不是一个可执行的实体。 *通过漫画了解线程进城 回到顶部
在多线程的操作系统中,通常是在一个进程中包括多个线程,每个线程都是作为利用CPU的基本单位,
是花费最小开销的实体。线程具有以下属性。
1)轻型实体
线程中的实体基本上不拥有系统资源,只是有一点必不可少的、能保证独立运行的资源。
线程的实体包括程序、数据和TCB。线程是动态概念,它的动态特性由线程控制块TCB(Thread Control Block)描述。
2)独立调度和分派的基本单位。
在多线程OS中,线程是能独立运行的基本单位,因而也是独立调度和分派的基本单位。
由于线程很“轻”,故线程的切换非常迅速且开销小(在同一进程中的)。
3)共享进程资源。
线程在同一进程中的各个线程,都可以共享该进程所拥有的资源,这首先表现在:
所有线程都具有相同的进程id,这意味着,线程可以访问该进程的每一个内存资源;
此外,还可以访问进程所拥有的已打开文件、定时器、信号量机构等。
由于同一个进程内的线程共享内存和文件,所以线程之间互相通信不必调用内核。
4)可并发执行。
在一个进程中的多个线程之间,可以并发执行,甚至允许在一个进程中所有线程都能并发执行;
同样,不同进程中的线程也能并发执行,充分利用和发挥了处理机与外围设备并行工作的能力。
线程的全局解释器锁:
Python代码的执行由Python虚拟机(也叫解释器主循环)来控制。Python在设计之初就考虑到要在主循环中,同时只有一个线程在执行。
虽然 Python 解释器中可以“运行”多个线程,但在任意时刻只有一个线程在解释器中运行。 对Python虚拟机的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。 在多线程环境中,Python 虚拟机按以下方式执行: a、设置 GIL; b、切换到一个线程去运行; c、运行指定数量的字节码指令或者线程主动让出控制(可以调用 time.sleep(0)); d、把线程设置为睡眠状态; e、解锁 GIL; d、再次重复以上所有步骤。 在调用外部代码(如 C/C++扩展函数)的时候,GIL将会被锁定,直到这个函数结束为止(由于在这期间没有Python的字节码被运行,
所以不会做线程切换)编写扩展的程序员可以主动解锁GIL。
全局解释锁,是由CPython解释器提供的,每次只能一个线程获得cpu的使用权:为了线程安全,也就是为了解决多线程之间的数据完整性和状态同步而加的锁,
因为我们知道线程之间的数据是共享的
线程的创建
multiprocess模块的完全模仿了threading模块的接口
利用 Threading.thread


from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('egon',)) t.start() print('主线程')
from threading import Thread import time class Sayhi(Thread): def __init__(self,name): super().__init__() self.name=name def run(self): time.sleep(2) print('%s say hello' % self.name) if __name__ == '__main__': t = Sayhi('egon') t.start() print('主线程')
多进程和多线程的区别:
from threading import Thread from multiprocessing import Process import os def work(): print('hello',os.getpid()) if __name__ == '__main__': #part1:在主进程下开启多个线程,每个线程都跟主进程的pid一样 t1=Thread(target=work) t2=Thread(target=work) t1.start() t2.start() print('主线程/主进程pid',os.getpid()) #part2:开多个进程,每个进程都有不同的pid p1=Process(target=work) p2=Process(target=work) p1.start() p2.start() print('主线程/主进程pid',os.getpid())
from threading import Thread from multiprocessing import Process import os def work(): print('hello') if __name__ == '__main__': #在主进程下开启线程 t=Thread(target=work) t.start() print('主线程/主进程') ''' 打印结果: hello 主线程/主进程 ''' #在主进程下开启子进程 t=Process(target=work) t.start() print('主线程/主进程') ''' 打印结果: 主线程/主进程 hello '''
from threading import Thread from multiprocessing import Process import os def work(): global n n=0 if __name__ == '__main__': # n=100 # p=Process(target=work) # p.start() # p.join() # print('主',n) #毫无疑问子进程p已经将自己的全局的n改成了0,但改的仅仅是它自己的,查看父进程的n仍然为100 n=1 t=Thread(target=work) t.start() t.join() print('主',n) #查看结果为0,因为同一进程内的线程之间共享进程内的数据 同一进程内的线程共享该进程的数据?
多线程实现socket
import multiprocessing import threading import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.bind(('127.0.0.1',8080)) s.listen(5) def action(conn): while True: data=conn.recv(1024) print(data) conn.send(data.upper()) if __name__ == '__main__': while True: conn,addr=s.accept() p=threading.Thread(target=action,args=(conn,)) p.start()
import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if not msg:continue s.send(msg.encode('utf-8')) data=s.recv(1024) print(data)
Thread的其他方法
Thread实例对象的方法
# isAlive(): 返回线程是否活动的。
# getName(): 返回线程名。
# setName(): 设置线程名。
threading模块提供的一些方法:
# threading.currentThread(): 返回当前的线程变量。
# threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
# threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
from threading import Thread import time def sayhi(name): time.sleep(2) print('%s say hello' %name) if __name__ == '__main__': t=Thread(target=sayhi,args=('me',)) t.start() t.join() print('主线程') print(t.is_alive())
守护线程:
from threading import Thread import time def foo(): print(123) time.sleep(1) print("end123") def bar(): print(456) time.sleep(3) print("end456") t1=Thread(target=foo) t2=Thread(target=bar) t1.daemon=True t1.start() t2.start() print("main-------")
GIL锁:
是全局的解释器锁 用来锁线程的
特点:是有CPython解释器提供的,导致同一时刻只能有一个线程访问CPU.
from threading import Lock as Lock import time mutexA=Lock() mutexA.acquire() mutexA.acquire() print(123) mutexA.release() mutexA.release()
递归锁
from threading import RLock as Lock import time mutexA=Lock() mutexA.acquire() mutexA.acquire() print(123) mutexA.release() mutexA.release()
信号量:
同进程的一样
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
from threading import Thread,Semaphore import threading import time # def func(): # if sm.acquire(): # print (threading.currentThread().getName() + ' get semaphore') # time.sleep(2) # sm.release() def func(): sm.acquire() print('%s get sm' %threading.current_thread().getName()) time.sleep(3) sm.release() if __name__ == '__main__': sm=Semaphore(5) for i in range(23): t=Thread(target=func) t.start()
与进程池是完全不同的概念,进程池Pool(4),最大只能产生4个进程,而且从头到尾都只是这四个进程,
不会产生新的,而信号量是产生一堆线程/进程
事件
event.isSet():返回event的状态值;
event.wait():如果 event.isSet()==False将阻塞线程;
event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度;
event.clear():恢复event的状态值为False。
条件:
条件的概念: Python提供的Condition对象提供了对复杂线程同步问题的支持。Condition被称为条件变量,除了提供与Lock类似的acquire和release方法外,
还提供了wait和notify方法。线程首先acquire一个条件变量,然后判断一些条件。如果条件不满足则wait;如果条件满足,进行一些处理改变条件后,
通过notify方法通知其他线程,其他处于wait状态的线程接到通知后会重新判断条件。不断的重复这一过程,从而解决复杂的同步问题。
定时器:
from threading import Timer def hello(): print("hello, world") t = Timer(1, hello) t.start()
线程队列:
queue队列 :使用import queue,用法与进程Queue一样
class queue.Queue(maxsize=0) #先进先出
import queue q=queue.Queue() q.put('first') q.put('second') q.put('third') print(q.get()) print(q.get()) print(q.get())
class queue.LifoQueue(maxsize=0) #last in fisrt out
import queue q=queue.LifoQueue() q.put('first') q.put('second') q.put('third') print(q.get()) print(q.get()) print(q.get())
class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
import queue q=queue.PriorityQueue() #put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高 q.put((20,'a')) q.put((10,'b')) q.put((30,'c')) print(q.get()) print(q.get()) print(q.get()) ''' 结果(数字越小优先级越高,优先级高的优先出队): (10, 'b') (20, 'a') (30, 'c')
Python标准模块--concurrent.futures
#1 介绍
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
Both implement the same interface, which is defined by the abstract Executor class.
#2 基本方法
#submit(fn, *args, **kwargs)
异步提交任务
#map(func, *iterables, timeout=None, chunksize=1)
取代for循环submit的操作
#shutdown(wait=True)
相当于进程池的pool.close()+pool.join()操作
wait=True,等待池内所有任务执行完毕回收完资源后才继续
wait=False,立即返回,并不会等待池内的任务执行完毕
但不管wait参数为何值,整个程序都会等到所有任务执行完毕
submit和map必须在shutdown之前
#result(timeout=None)
取得结果
#add_done_callback(fn)
回调函数
进程池:
import os,time from multiprocessing import Pool def work(n): print('%s run' %os.getpid()) time.sleep(3) return n**2 if __name__ == '__main__': p=Pool(3) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务 res_l=[] for i in range(10): res=p.apply(work,args=(i,)) # 同步调用,直到本次任务执行完毕拿到res,等待任务work执行的过程中可能有阻塞也可能没有阻塞 # 但不管该任务是否存在阻塞,同步调用都会在原地等着 print(res_l)
import os import time import random from multiprocessing import Pool def work(n): print('%s run' %os.getpid()) time.sleep(random.random()) return n**2 if __name__ == '__main__': p=Pool(3) #进程池中从无到有创建三个进程,以后一直是这三个进程在执行任务 res_l=[] for i in range(10): res=p.apply_async(work,args=(i,)) # 异步运行,根据进程池中有的进程数,每次最多3个子进程在异步执行 # 返回结果之后,将结果放入列表,归还进程,之后再执行新的任务 # 需要注意的是,进程池中的三个进程不会同时开启或者同时结束 # 而是执行完一个就释放一个进程,这个进程就去接收新的任务。 res_l.append(res) # 异步apply_async用法:如果使用异步提交的任务,主进程需要使用jion,等待进程池内任务都处理完,然后可以用get收集结果 # 否则,主进程结束,进程池可能还没来得及执行,也就跟着一起结束了 p.close() p.join() for res in res_l: print(res.get()) #使用get来获取apply_aync的结果,如果是apply,则没有get方法,因为apply是同步执行,立刻获取结果,也根本无需get 进程池的异步调用
concurrent.futures ThreadPoolExecutor 用法 和 ProcessPoolExecutor 一样
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os,time,random def task(n): print('%s is runing' %os.getpid()) time.sleep(random.randint(1,3)) return n**2 if __name__ == '__main__': executor=ThreadPoolExecutor(max_workers=3) # for i in range(11): # future=executor.submit(task,i) executor.map(task,range(1,12)) #map取代了for+submit
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor from multiprocessing import Pool import requests import json import os def get_page(url): print('<进程%s> get %s' %(os.getpid(),url)) respone=requests.get(url) if respone.status_code == 200: return {'url':url,'text':respone.text} def parse_page(res): res=res.result() print('<进程%s> parse %s' %(os.getpid(),res['url'])) parse_res='url:<%s> size:[%s] ' %(res['url'],len(res['text'])) with open('db.txt','a') as f: f.write(parse_res) if __name__ == '__main__': urls=[ 'https://www.baidu.com', 'https://www.python.org', 'https://www.openstack.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] # p=Pool(3) # for url in urls: # p.apply_async(get_page,args=(url,),callback=pasrse_page) # p.close() # p.join() p=ProcessPoolExecutor(3) for url in urls: p.submit(get_page,url).add_done_callback(parse_page) #parse_page拿到的是一个future对象obj,需要用obj.result()拿到结果
import multiprocessing import threading import socket s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.bind(('127.0.0.1',8080)) s.listen(5) def action(conn): while True: data=conn.recv(1024) print(data) conn.send(data.upper()) if __name__ == '__main__': while True: conn,addr=s.accept() p=threading.Thread(target=action,args=(conn,)) p.start()
from gevent.threadpool import ThreadPoolExecutor p = ThreadPoolExecutor(1) for i in make_url(): p.submit(ul.content,i)
多线程之间的线程安全
from concurrent.futures import ThreadPoolExecutor
future_list = []
result = []
# 使用submit提交执行的函数到线程池中,并返回futer对象(非阻塞)
with ThreadPoolExecutor(max_workers=args.c) as exector:
future = exector.submit(download_one, cc)
future_list.append(future)
.....
# as_completed方法传入一个Future迭代器,然后在Future对象运行结束之后yield Future
for future in futures.as_completed(future_list):
# 通过result()方法获取结果
res = future.result()
result.append(res)